搜索到
1
篇与
的结果
-
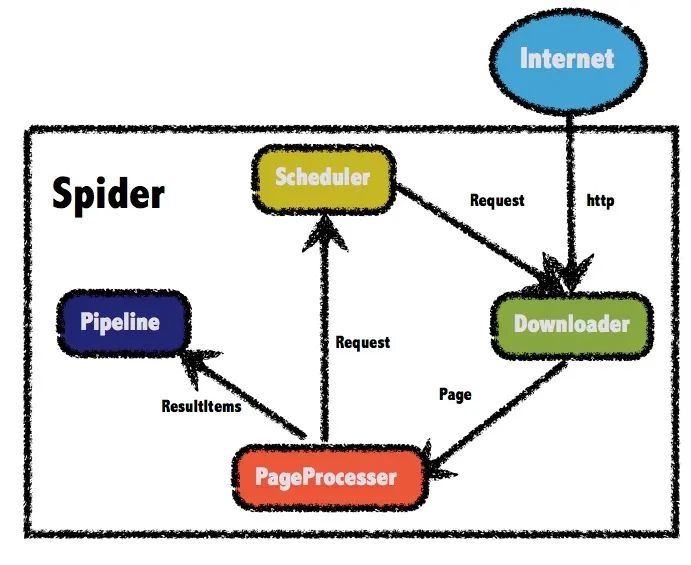
 用 Java 写爬虫 前两天,百度紧随 GPT-4 发布了自己的语言模型文心一言。讲道理,对于国内能够发布这样一个敢于对标CHAT GPT的高质量语言模型,大家应该更多感受到的是赛博朋克与现实生活贴近的真实感,对这个模型应该有着更多的鼓励或赞美。可不知是因为整个发布会搞的过于像没有好好准备的学生毕业答辩PPT,还是它的实际表现并没有那么如人意,大家貌似对文心一言并不那么买账。于是我决定看一下知乎大神们对文心一言的评价,哪想到随便打开一个问题,居然有600多条回答…要是我这一条一条翻完所有回答,估计就得拿出一天来全职摸鱼了,那么有没有什么办法能够最快的分析出对待这个问题大家的综合评价呢?那么今天就让我纱布擦屁股,给大家露一小手,写一个爬虫扒下来所有的回答,再对结果进行一下分析。WebMagic正式开始前,咱们得先搞定工具。虽然python写起爬虫来有天然的框架优势,不过鉴于大家都是搞java的,那么我们今天就用java框架来实现一个爬虫。咱们要使用的工具 WebMagic ,就是一款简单灵活的java爬虫框架,总体架构由下面这几部分构成:Downloader:负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。PageProcessor:负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。Scheduler:负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。Pipeline:负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了输出到控制台和保存到文件两种结果处理方案。在4个主要组件中,除了 PageProcessor 之外,其他3个组件基本都可以复用。而我们实际爬虫中的重点,就是要针对不同网页进行页面元素的分析,进而定制化地开发不同的 PageProcessor 。下面我们开始准备实战,先引入 webmagic 的 core 和 extension 两个依赖,最新0.8.0版本搞里头:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.8.0</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.8.0</version> </dependency>PageProcessor 与 xpath 在正式开始抓取页面前,我们先看看知乎上一个问题的页面是怎么构成的,还是以上面图中那个问题为例,原问题的地址在这里:https://www.zhihu.com/question/589929380我们先做个简单的测试,来获取这个问题的标题,以及对这个问题的描述。通过浏览器的审查元素,可以看到标题是一个h1的标题元素,并且它的class属性是QuestionHeader-title,而问题的描述部分在一个div中,它的class中包含了QuestionRichText。简单分析完了,按照前面说的,我们要对这个页面定制一个 PageProcessor组件 抽取信息,直接上代码。新建一个类实现 PageProcessor接口 ,并实现接口中的 process() 这个方法即可。public class WenxinProcessor implements PageProcessor { private Site site = Site.me() .setRetryTimes(3).setSleepTime(1000); @Override public void process(Page page) { String title = page.getHtml() .xpath("//h1[@class='QuestionHeader-title']/text()").toString(); String question= page.getHtml() .xpath("//div[@class='QuestionRichText']//tidyText()").toString(); System.out.println(title); System.out.println(question); } public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .run(); } }查看运行结果:可以看到,在代码中通过 xpath() 这样一个方法,成功拿到了我们要取的两个元素。其实说白了,这个 xpath 也不是爬虫框架中才有的新玩意,而是一种 XML 路径语言(XML Path Language),是一种用来确定XML文档中某部分位置的语言。它基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。常用的路径表达式包括:表达式描述nodename选取此节点的所有子节点。/从根节点选取。//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。.选取当前节点。..选取当前节点的父节点。@选取属性。在上面的代码中,//h1[@class='QuestionHeader-title']就表示选取一个类型为 h1 的节点,并且它有一个 class 为 QuestionHeader-title 的属性。至于后面的 text() 和 tidyText() 方法,则是用于提取元素中的文本,这些函数不是标准 xpath 中的,而是 webMagic 中特有的新方法,这些函数的使用可以参考文档:http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html看到这,你可能还有个问题,这里对于问题的描述部分没有显示完全,你需要在页面上点一下这个显示全部它才会显示详细的信息。没关系,这里先留个坑,这个问题放在后面解决。获取提问的答案我们完善一下上面的代码,尝试获取问题的解答。按照老套路,还是先分析页面元素再用 xpath 写表达式获取。修改 process 方法:@Override public void process(Page page) { String contentPath= "div[@class='QuestionAnswers-answers']"+ "//div[@class='RichContent RichContent--unescapable']" + "//div[@class='RichContent-inner']"+ "/tidyText()"; List<String> answerList = page.getHtml().xpath(contentPath).all(); for (int i = 0; i < answerList.size(); i++) { System.out.println("第"+(i+1)+"条回答:"); System.out.println(answerList.get(i)+"\n======="); } }在上面的代码中,使用了 xpath 获取页面中具有相同属性的元素,并将它们存入了 List 列表中。看一下运行结果:纳尼?这个问题明明有着689条的回答,为什么我们只爬到了两条答案?如果你经常用知乎来学习摸鱼的话,其实就会知道对于这种有大量回答的问题,页面刚开始只会默认显示很少的几条的消息,随着你不断的下拉页面才会把新的回答显示出来。那么如果我想拿到所有的评论应该怎么做呢?这时候就要引出 webMagic 中另一个神奇的组件 Selenium 了。Selenium简单来说, selenium 是一个用于 Web应用程序 测试的工具, selenium 测试可以直接运行在浏览器中,就像真正的用户在操作一样,并且目前主流的大牌浏览器一般都支持这项技术。所以在爬虫中,我们可以通过编写模仿用户操作的 selenium脚本 ,模拟进行一部分用互操作,比如点击事件或屏幕滚动等等。WebMagic-Selenium 需要依赖于 WebDriver ,所以我们先进行本地 WebDriver 的安装操作。安装WebDriver 查看自己电脑上 Chrome 版本,可以点击 设置 -> 关于chrome 查看,也可以直接在地址栏输入 chrome://settings/help :可以看到版本号,然后需要下载对应版本的 WebDriver ,下载地址:http://chromedriver.storage.googleapis.com/index.html打开后,可以看到各个版本,选择与本地浏览器最接近的版本:点击进入后,根据我们的系统选择对应版本下载即可。下载完成后,解压到本地目录中,之后在使用 selenium模块 中会使用到。这个文件建议放在 chrome安装目录 下,否则之后在代码中可能会报一个 WebDriverException: unknown error: cannot find Chrome binary 找不到 chrome文件的错误 。修改Selenium源码webMagic 中已经封装了 selenium模块 的代码,但官方版本的代码有些地方需要修改,我们下载源码后要自己简单改动一下然后重新编译。我这下载了 0.8.1-SNAPSHOT 版本的代码,官方 git 地址:https://github.com/code4craft/webmagic修改配置文件地址,在 WebDriverPool 将 selenium配置文件 路径写死了,需要改变配置路径:// 修改前 // private static final String DEFAULT_CONFIG_FILE = "/data/webmagic/webmagic-selenium/config.ini"; // 修改后 private static final String DEFAULT_CONFIG_FILE = "selenium.properties";在 resources目录 下添加配置文件 selenium.properties :# What WebDriver to use for the tests driver=chrome # PhantomJS specific config (change according to your installation) chrome_driver_loglevel=DEBUGjs模拟页面操作修改 SeleniumDownloader 的 download()方法 ,在代码中的这个位置,作者很贴心的给我们留了一行注释:意思就是,你可以在这添加鼠标事件或者干点别的什么东西了。我们在这添加页面向下滚动这一模拟事件,每休眠 2s 就向下滚动一下页面,一共下拉 20 次://模拟下拉,刷新页面 for (int i=0; i < 20; i++){ System.out.println("休眠2s"); try { //滚动到最底部 ((JavascriptExecutor)webDriver) .executeScript("window.scrollTo(0,document.body.scrollHeight)"); //休眠,等待加载页面 Thread.sleep(2000); //往回滚一点,否则不加载 ((JavascriptExecutor)webDriver) .executeScript("window.scrollBy(0,-300)"); } catch (InterruptedException e) { e.printStackTrace(); } }修改完成后本地打个包,注意还要修改一下版本号,改成和发行版的不同即可,我这里改成了 0.8.1.1-SNAPSHOT 。mvn clean install调用回到之前的爬虫项目,引入我们自己打好的包:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-selenium</artifactId> <version>0.8.1.1-SNAPSHOT</version> </dependency>修改之前的主程序启动时的代码,添加 Downloader 组件, SeleniumDownloader 构造方法的参数中传入我们下好的 chrome 的 webDriver 的可执行文件的地址:public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }进行测试,可以看到在拉动了40秒窗口后,获取到的答案条数是100条:通过适当地添加下拉页面的循环的次数,我们就能够获取到当前问题下的全部回答了。另外,在启动爬虫后我们会看到 webDriver 弹出了一个 chrome 的窗口,在这个窗口中有一个提示: Chrome 正受到自动测试软件的控制,并且可以看到页面不断的自动下拉情况:如果不想要这个弹窗的话,可以修改 selenium模块 的代码进行隐藏。修改 WebDriverPool 的 configure()方法 ,找到这段代码:if (driver.equals(DRIVER_CHROME)) { mDriver = new ChromeDriver(sCaps); }添加一个隐藏显示的选项,并且在修改完成后,重新打包一下。if (driver.equals(DRIVER_CHROME)) { ChromeOptions options=new ChromeOptions(); options.setHeadless(true); mDriver = new ChromeDriver(options); }获取问题详细描述不知道大家还记不记得在前面还留了一个坑,我们现在获取到的对问题的描述是不全的,需要点一下这个按钮才能显示完全。同样,这个问题也可以用 selenium 来解决,在我们下拉页面前,加上这么一个模拟点击事件,就可以获得对问题的详细描述了:((JavascriptExecutor)webDriver) .executeScript("document.getElementsByClassName('Button QuestionRichText-more')[0].click()");看一下执行结果,已经可以拿到完整内容了:Pipeline到这里,虽然要爬的数据获取到了,但是要进行分析的话,还需要进行持久化操作。在前面的 webMagic 的架构图中,介绍过 Pipeline组件 主要负责结果的处理,所以我们再优化一下代码,添加一个 Pipeline 负责数据的持久化。由于数据量也不是非常大,这里我选择了直接存入 ElasticSearch 中,同时也方便我们进行后续的分析操作, ES组件 我使用的是 esclientrhl ,为了方便我还是把项目整个扔到了 spring 里面。定制一个 Pipeline 也很简单,实现 Pipeline接口 并实现里面的 process()接口 就可以了,通过构造方法传入 ES 持久化层组件:@Slf4j @AllArgsConstructor public class WenxinPipeline implements Pipeline { private final ZhihuRepository zhihuRepository; @Override public void process(ResultItems resultItems, Task task) { Map<String, Object> map = resultItems.getAll(); String title = map.get("title").toString(); String question = map.get("question").toString(); List<String> answer = (List<String>) map.get("answer"); ZhihuEntity zhihuEntity; for (String an : answer) { zhihuEntity = new ZhihuEntity(); zhihuEntity.setTitle(title); zhihuEntity.setQuestion(question); zhihuEntity.setAnswer(an); try { zhihuRepository.save(zhihuEntity); } catch (Exception e) { e.printStackTrace(); } } } }把 selenium 向下拉取页面的次数改成200后,通过接口启动程序:@GetMapping("wenxin") public void wenxin() { new Thread(() -> { Request request = new Request("https://www.zhihu.com/question/589929380"); WenxinProcessor4 wenxinProcessor = new WenxinProcessor4(); Spider.create(wenxinProcessor) .addRequest(request) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }).start(); }运行完成后,查询一下 ES 中的数据,可以看到,实际爬取到了673条回答。另外,我们可以在一个爬虫程序中传入多个页面地址,只要页面元素具有相同的规则,那么它们就能用相同的爬虫逻辑处理,在下面的代码中,我们一次性传入多个页面:Spider.create(new WenxinProcessor4()) .addUrl(new String[]{"https://www.zhihu.com/question/589941496", "https://www.zhihu.com/question/589904230","https://www.zhihu.com/question/589938328"}) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run();一顿忙活下来,最终扒下来1300多条数据。分析数据落到了 ES 里后,那我们就可以根据关键字进行分析了,我们先选择10个负面方向的词语进行查询,可以看到查到了403条数据,将近占到了总量的三分之一。再从各种回答中选择10个正向词语查询,结果大概只有负面方向的一半左右:不得不说,这届网友真的是很严厉…Proxy代理说到爬虫,其实还有一个绕不过去的东西,那就是代理。像咱们这样的小打小闹,爬个百八十条数据虽然没啥问题,但是如果要去爬取大量数据或是用于商业,还是建议使用一下代理,一方面能够隐藏我们的IP地址起到保护自己的作用,另一方面动态IP也能有效的应对一些反爬策略。个人在使用中,比较推荐的是隧道代理。简单的来说,如果你购买了IP服务的话,用普通代理方式的话需要你去手动请求接口获取IP地址,再到代码中动态修改。而使用隧道代理的话,就不需要自己提取代理IP了,每条隧道自动提取并使用代理IP转发用户请求,这样我们就可以专注于业务了。虽然网上也有免费的代理能够能用,但要不然就是失效的太快,要不就是很容易被网站加入黑名单,所以如果追求性能的话还是买个专业点的代理比较好,虽然可能价格不那么便宜就是了。最后附上源码下载地址源码地址:https://github.com/trunks2008/zhihu-spider
用 Java 写爬虫 前两天,百度紧随 GPT-4 发布了自己的语言模型文心一言。讲道理,对于国内能够发布这样一个敢于对标CHAT GPT的高质量语言模型,大家应该更多感受到的是赛博朋克与现实生活贴近的真实感,对这个模型应该有着更多的鼓励或赞美。可不知是因为整个发布会搞的过于像没有好好准备的学生毕业答辩PPT,还是它的实际表现并没有那么如人意,大家貌似对文心一言并不那么买账。于是我决定看一下知乎大神们对文心一言的评价,哪想到随便打开一个问题,居然有600多条回答…要是我这一条一条翻完所有回答,估计就得拿出一天来全职摸鱼了,那么有没有什么办法能够最快的分析出对待这个问题大家的综合评价呢?那么今天就让我纱布擦屁股,给大家露一小手,写一个爬虫扒下来所有的回答,再对结果进行一下分析。WebMagic正式开始前,咱们得先搞定工具。虽然python写起爬虫来有天然的框架优势,不过鉴于大家都是搞java的,那么我们今天就用java框架来实现一个爬虫。咱们要使用的工具 WebMagic ,就是一款简单灵活的java爬虫框架,总体架构由下面这几部分构成:Downloader:负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。PageProcessor:负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。Scheduler:负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。Pipeline:负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了输出到控制台和保存到文件两种结果处理方案。在4个主要组件中,除了 PageProcessor 之外,其他3个组件基本都可以复用。而我们实际爬虫中的重点,就是要针对不同网页进行页面元素的分析,进而定制化地开发不同的 PageProcessor 。下面我们开始准备实战,先引入 webmagic 的 core 和 extension 两个依赖,最新0.8.0版本搞里头:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.8.0</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.8.0</version> </dependency>PageProcessor 与 xpath 在正式开始抓取页面前,我们先看看知乎上一个问题的页面是怎么构成的,还是以上面图中那个问题为例,原问题的地址在这里:https://www.zhihu.com/question/589929380我们先做个简单的测试,来获取这个问题的标题,以及对这个问题的描述。通过浏览器的审查元素,可以看到标题是一个h1的标题元素,并且它的class属性是QuestionHeader-title,而问题的描述部分在一个div中,它的class中包含了QuestionRichText。简单分析完了,按照前面说的,我们要对这个页面定制一个 PageProcessor组件 抽取信息,直接上代码。新建一个类实现 PageProcessor接口 ,并实现接口中的 process() 这个方法即可。public class WenxinProcessor implements PageProcessor { private Site site = Site.me() .setRetryTimes(3).setSleepTime(1000); @Override public void process(Page page) { String title = page.getHtml() .xpath("//h1[@class='QuestionHeader-title']/text()").toString(); String question= page.getHtml() .xpath("//div[@class='QuestionRichText']//tidyText()").toString(); System.out.println(title); System.out.println(question); } public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .run(); } }查看运行结果:可以看到,在代码中通过 xpath() 这样一个方法,成功拿到了我们要取的两个元素。其实说白了,这个 xpath 也不是爬虫框架中才有的新玩意,而是一种 XML 路径语言(XML Path Language),是一种用来确定XML文档中某部分位置的语言。它基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。常用的路径表达式包括:表达式描述nodename选取此节点的所有子节点。/从根节点选取。//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。.选取当前节点。..选取当前节点的父节点。@选取属性。在上面的代码中,//h1[@class='QuestionHeader-title']就表示选取一个类型为 h1 的节点,并且它有一个 class 为 QuestionHeader-title 的属性。至于后面的 text() 和 tidyText() 方法,则是用于提取元素中的文本,这些函数不是标准 xpath 中的,而是 webMagic 中特有的新方法,这些函数的使用可以参考文档:http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html看到这,你可能还有个问题,这里对于问题的描述部分没有显示完全,你需要在页面上点一下这个显示全部它才会显示详细的信息。没关系,这里先留个坑,这个问题放在后面解决。获取提问的答案我们完善一下上面的代码,尝试获取问题的解答。按照老套路,还是先分析页面元素再用 xpath 写表达式获取。修改 process 方法:@Override public void process(Page page) { String contentPath= "div[@class='QuestionAnswers-answers']"+ "//div[@class='RichContent RichContent--unescapable']" + "//div[@class='RichContent-inner']"+ "/tidyText()"; List<String> answerList = page.getHtml().xpath(contentPath).all(); for (int i = 0; i < answerList.size(); i++) { System.out.println("第"+(i+1)+"条回答:"); System.out.println(answerList.get(i)+"\n======="); } }在上面的代码中,使用了 xpath 获取页面中具有相同属性的元素,并将它们存入了 List 列表中。看一下运行结果:纳尼?这个问题明明有着689条的回答,为什么我们只爬到了两条答案?如果你经常用知乎来学习摸鱼的话,其实就会知道对于这种有大量回答的问题,页面刚开始只会默认显示很少的几条的消息,随着你不断的下拉页面才会把新的回答显示出来。那么如果我想拿到所有的评论应该怎么做呢?这时候就要引出 webMagic 中另一个神奇的组件 Selenium 了。Selenium简单来说, selenium 是一个用于 Web应用程序 测试的工具, selenium 测试可以直接运行在浏览器中,就像真正的用户在操作一样,并且目前主流的大牌浏览器一般都支持这项技术。所以在爬虫中,我们可以通过编写模仿用户操作的 selenium脚本 ,模拟进行一部分用互操作,比如点击事件或屏幕滚动等等。WebMagic-Selenium 需要依赖于 WebDriver ,所以我们先进行本地 WebDriver 的安装操作。安装WebDriver 查看自己电脑上 Chrome 版本,可以点击 设置 -> 关于chrome 查看,也可以直接在地址栏输入 chrome://settings/help :可以看到版本号,然后需要下载对应版本的 WebDriver ,下载地址:http://chromedriver.storage.googleapis.com/index.html打开后,可以看到各个版本,选择与本地浏览器最接近的版本:点击进入后,根据我们的系统选择对应版本下载即可。下载完成后,解压到本地目录中,之后在使用 selenium模块 中会使用到。这个文件建议放在 chrome安装目录 下,否则之后在代码中可能会报一个 WebDriverException: unknown error: cannot find Chrome binary 找不到 chrome文件的错误 。修改Selenium源码webMagic 中已经封装了 selenium模块 的代码,但官方版本的代码有些地方需要修改,我们下载源码后要自己简单改动一下然后重新编译。我这下载了 0.8.1-SNAPSHOT 版本的代码,官方 git 地址:https://github.com/code4craft/webmagic修改配置文件地址,在 WebDriverPool 将 selenium配置文件 路径写死了,需要改变配置路径:// 修改前 // private static final String DEFAULT_CONFIG_FILE = "/data/webmagic/webmagic-selenium/config.ini"; // 修改后 private static final String DEFAULT_CONFIG_FILE = "selenium.properties";在 resources目录 下添加配置文件 selenium.properties :# What WebDriver to use for the tests driver=chrome # PhantomJS specific config (change according to your installation) chrome_driver_loglevel=DEBUGjs模拟页面操作修改 SeleniumDownloader 的 download()方法 ,在代码中的这个位置,作者很贴心的给我们留了一行注释:意思就是,你可以在这添加鼠标事件或者干点别的什么东西了。我们在这添加页面向下滚动这一模拟事件,每休眠 2s 就向下滚动一下页面,一共下拉 20 次://模拟下拉,刷新页面 for (int i=0; i < 20; i++){ System.out.println("休眠2s"); try { //滚动到最底部 ((JavascriptExecutor)webDriver) .executeScript("window.scrollTo(0,document.body.scrollHeight)"); //休眠,等待加载页面 Thread.sleep(2000); //往回滚一点,否则不加载 ((JavascriptExecutor)webDriver) .executeScript("window.scrollBy(0,-300)"); } catch (InterruptedException e) { e.printStackTrace(); } }修改完成后本地打个包,注意还要修改一下版本号,改成和发行版的不同即可,我这里改成了 0.8.1.1-SNAPSHOT 。mvn clean install调用回到之前的爬虫项目,引入我们自己打好的包:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-selenium</artifactId> <version>0.8.1.1-SNAPSHOT</version> </dependency>修改之前的主程序启动时的代码,添加 Downloader 组件, SeleniumDownloader 构造方法的参数中传入我们下好的 chrome 的 webDriver 的可执行文件的地址:public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }进行测试,可以看到在拉动了40秒窗口后,获取到的答案条数是100条:通过适当地添加下拉页面的循环的次数,我们就能够获取到当前问题下的全部回答了。另外,在启动爬虫后我们会看到 webDriver 弹出了一个 chrome 的窗口,在这个窗口中有一个提示: Chrome 正受到自动测试软件的控制,并且可以看到页面不断的自动下拉情况:如果不想要这个弹窗的话,可以修改 selenium模块 的代码进行隐藏。修改 WebDriverPool 的 configure()方法 ,找到这段代码:if (driver.equals(DRIVER_CHROME)) { mDriver = new ChromeDriver(sCaps); }添加一个隐藏显示的选项,并且在修改完成后,重新打包一下。if (driver.equals(DRIVER_CHROME)) { ChromeOptions options=new ChromeOptions(); options.setHeadless(true); mDriver = new ChromeDriver(options); }获取问题详细描述不知道大家还记不记得在前面还留了一个坑,我们现在获取到的对问题的描述是不全的,需要点一下这个按钮才能显示完全。同样,这个问题也可以用 selenium 来解决,在我们下拉页面前,加上这么一个模拟点击事件,就可以获得对问题的详细描述了:((JavascriptExecutor)webDriver) .executeScript("document.getElementsByClassName('Button QuestionRichText-more')[0].click()");看一下执行结果,已经可以拿到完整内容了:Pipeline到这里,虽然要爬的数据获取到了,但是要进行分析的话,还需要进行持久化操作。在前面的 webMagic 的架构图中,介绍过 Pipeline组件 主要负责结果的处理,所以我们再优化一下代码,添加一个 Pipeline 负责数据的持久化。由于数据量也不是非常大,这里我选择了直接存入 ElasticSearch 中,同时也方便我们进行后续的分析操作, ES组件 我使用的是 esclientrhl ,为了方便我还是把项目整个扔到了 spring 里面。定制一个 Pipeline 也很简单,实现 Pipeline接口 并实现里面的 process()接口 就可以了,通过构造方法传入 ES 持久化层组件:@Slf4j @AllArgsConstructor public class WenxinPipeline implements Pipeline { private final ZhihuRepository zhihuRepository; @Override public void process(ResultItems resultItems, Task task) { Map<String, Object> map = resultItems.getAll(); String title = map.get("title").toString(); String question = map.get("question").toString(); List<String> answer = (List<String>) map.get("answer"); ZhihuEntity zhihuEntity; for (String an : answer) { zhihuEntity = new ZhihuEntity(); zhihuEntity.setTitle(title); zhihuEntity.setQuestion(question); zhihuEntity.setAnswer(an); try { zhihuRepository.save(zhihuEntity); } catch (Exception e) { e.printStackTrace(); } } } }把 selenium 向下拉取页面的次数改成200后,通过接口启动程序:@GetMapping("wenxin") public void wenxin() { new Thread(() -> { Request request = new Request("https://www.zhihu.com/question/589929380"); WenxinProcessor4 wenxinProcessor = new WenxinProcessor4(); Spider.create(wenxinProcessor) .addRequest(request) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }).start(); }运行完成后,查询一下 ES 中的数据,可以看到,实际爬取到了673条回答。另外,我们可以在一个爬虫程序中传入多个页面地址,只要页面元素具有相同的规则,那么它们就能用相同的爬虫逻辑处理,在下面的代码中,我们一次性传入多个页面:Spider.create(new WenxinProcessor4()) .addUrl(new String[]{"https://www.zhihu.com/question/589941496", "https://www.zhihu.com/question/589904230","https://www.zhihu.com/question/589938328"}) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run();一顿忙活下来,最终扒下来1300多条数据。分析数据落到了 ES 里后,那我们就可以根据关键字进行分析了,我们先选择10个负面方向的词语进行查询,可以看到查到了403条数据,将近占到了总量的三分之一。再从各种回答中选择10个正向词语查询,结果大概只有负面方向的一半左右:不得不说,这届网友真的是很严厉…Proxy代理说到爬虫,其实还有一个绕不过去的东西,那就是代理。像咱们这样的小打小闹,爬个百八十条数据虽然没啥问题,但是如果要去爬取大量数据或是用于商业,还是建议使用一下代理,一方面能够隐藏我们的IP地址起到保护自己的作用,另一方面动态IP也能有效的应对一些反爬策略。个人在使用中,比较推荐的是隧道代理。简单的来说,如果你购买了IP服务的话,用普通代理方式的话需要你去手动请求接口获取IP地址,再到代码中动态修改。而使用隧道代理的话,就不需要自己提取代理IP了,每条隧道自动提取并使用代理IP转发用户请求,这样我们就可以专注于业务了。虽然网上也有免费的代理能够能用,但要不然就是失效的太快,要不就是很容易被网站加入黑名单,所以如果追求性能的话还是买个专业点的代理比较好,虽然可能价格不那么便宜就是了。最后附上源码下载地址源码地址:https://github.com/trunks2008/zhihu-spider