搜索到
10
篇与
的结果
-
 SpringBoot 优雅实现超大文件上传,通用方案 前言文件上传是一个老生常谈的话题了,在文件相对比较小的情况下,可以直接把文件转化为字节流上传到服务器,但在文件比较大的情况下,用普通的方式进行上传,这可不是一个好的办法,毕竟很少有人会忍受,当文件上传到一半中断后,继续上传却只能重头开始上传,这种让人不爽的体验。那有没有比较好的上传体验呢,答案有的,就是下边要介绍的几种上传方式详细教程秒传1、什么是秒传通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。2、本文实现的秒传核心逻辑a、利用redis的set方法存放文件上传状态,其中key为文件上传的md5,value为是否上传完成的标志位,b、当标志位true为上传已经完成,此时如果有相同文件上传,则进入秒传逻辑。如果标志位为false,则说明还没上传完成,此时需要在调用set的方法,保存块号文件记录的路径,其中key为上传文件md5加一个固定前缀,value为块号文件记录路径分片上传1、什么是分片上传分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。2、分片上传的场景1、大文件上传2、网络环境环境不好,存在需要重传风险的场景断点续传1、什么是断点续传断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。本文的断点续传主要是针对断点上传场景。2、应用场景断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。3、实现断点续传的核心逻辑在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。4、实现流程步骤a、方案一,常规步骤将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;初始化一个分片上传任务,返回本次分片上传唯一标识;按照一定的策略(串行或并行)发送各个分片数据块;发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。b、方案二、本文实现的步骤前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。5、分片上传/断点上传代码实现a、前端采用百度提供的webuploader的插件,进行分片。因本文主要介绍服务端代码实现,webuploader如何进行分片,具体实现可以查看链接: http://fex.baidu.com/webuploader/getting-started.htmlb、后端用两种方式实现文件写入,一种是用RandomAccessFile,如果对RandomAccessFile不熟悉的朋友,可以查看链接: https://blog.csdn.net/dimudan2015/article/details/81910690另一种是使用MappedByteBuffer,对MappedByteBuffer不熟悉的朋友,可以查看链接进行了解: https://www.jianshu.com/p/f90866dcbffc后端进行写入操作的核心代码a、RandomAccessFile实现方式@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS) @Slf4j public class RandomAccessUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile accessTmpFile = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); accessTmpFile = new RandomAccessFile(tmpFile, "rw"); //这个必须与前端设定的值一致 long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); long offset = chunkSize * param.getChunk(); //定位到该分片的偏移量 accessTmpFile.seek(offset); //写入该分片数据 accessTmpFile.write(param.getFile().getBytes()); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessTmpFile); } return false; } } b、MappedByteBuffer实现方式@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER) @Slf4j public class MappedByteBufferUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile tempRaf = null; FileChannel fileChannel = null; MappedByteBuffer mappedByteBuffer = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); tempRaf = new RandomAccessFile(tmpFile, "rw"); fileChannel = tempRaf.getChannel(); long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); //写入该分片数据 long offset = chunkSize * param.getChunk(); byte[] fileData = param.getFile().getBytes(); mappedByteBuffer = fileChannel .map(FileChannel.MapMode.READ_WRITE, offset, fileData.length); mappedByteBuffer.put(fileData); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.freedMappedByteBuffer(mappedByteBuffer); FileUtil.close(fileChannel); FileUtil.close(tempRaf); } return false; } } c、文件操作核心模板类代码@Slf4j public abstract class SliceUploadTemplate implements SliceUploadStrategy { public abstract boolean upload(FileUploadRequestDTO param); protected File createTmpFile(FileUploadRequestDTO param) { FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class); param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath())); String fileName = param.getFile().getOriginalFilename(); String uploadDirPath = filePathUtil.getPath(param); String tempFileName = fileName + "_tmp"; File tmpDir = new File(uploadDirPath); File tmpFile = new File(uploadDirPath, tempFileName); if (!tmpDir.exists()) { tmpDir.mkdirs(); } return tmpFile; } @Override public FileUploadDTO sliceUpload(FileUploadRequestDTO param) { boolean isOk = this.upload(param); if (isOk) { File tmpFile = this.createTmpFile(param); FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile); return fileUploadDTO; } String md5 = FileMD5Util.getFileMD5(param.getFile()); Map<Integer, String> map = new HashMap<>(); map.put(param.getChunk(), md5); return FileUploadDTO.builder().chunkMd5Info(map).build(); } /** * 检查并修改文件上传进度 */ public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) { String fileName = param.getFile().getOriginalFilename(); File confFile = new File(uploadDirPath, fileName + ".conf"); byte isComplete = 0; RandomAccessFile accessConfFile = null; try { accessConfFile = new RandomAccessFile(confFile, "rw"); //把该分段标记为 true 表示完成 System.out.println("set part " + param.getChunk() + " complete"); //创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127 accessConfFile.setLength(param.getChunks()); accessConfFile.seek(param.getChunk()); accessConfFile.write(Byte.MAX_VALUE); //completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传) byte[] completeList = FileUtils.readFileToByteArray(confFile); isComplete = Byte.MAX_VALUE; for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) { //与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE isComplete = (byte) (isComplete & completeList[i]); System.out.println("check part " + i + " complete?:" + completeList[i]); } } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessConfFile); } boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete); return isOk; } /** * 把上传进度信息存进redis */ private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath, String fileName, File confFile, byte isComplete) { RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class); if (isComplete == Byte.MAX_VALUE) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true"); redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5()); confFile.delete(); return true; } else { if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false"); redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(), uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf"); } return false; } } /** * 保存文件操作 */ public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) { FileUploadDTO fileUploadDTO = null; try { fileUploadDTO = renameFile(tmpFile, fileName); if (fileUploadDTO.isUploadComplete()) { System.out .println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName); //TODO 保存文件信息到数据库 } } catch (Exception e) { log.error(e.getMessage(), e); } finally { } return fileUploadDTO; } /** * 文件重命名 * * @param toBeRenamed 将要修改名字的文件 * @param toFileNewName 新的名字 */ private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) { //检查要重命名的文件是否存在,是否是文件 FileUploadDTO fileUploadDTO = new FileUploadDTO(); if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) { log.info("File does not exist: {}", toBeRenamed.getName()); fileUploadDTO.setUploadComplete(false); return fileUploadDTO; } String ext = FileUtil.getExtension(toFileNewName); String p = toBeRenamed.getParent(); String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName; File newFile = new File(filePath); //修改文件名 boolean uploadFlag = toBeRenamed.renameTo(newFile); fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp()); fileUploadDTO.setUploadComplete(uploadFlag); fileUploadDTO.setPath(filePath); fileUploadDTO.setSize(newFile.length()); fileUploadDTO.setFileExt(ext); fileUploadDTO.setFileId(toFileNewName); return fileUploadDTO; } } 总结在实现分片上传的过程,需要前端和后端配合,比如前后端的上传块号的文件大小,前后端必须得要一致,否则上传就会有问题。其次文件相关操作正常都是要搭建一个文件服务器的,比如使用fastdfs、hdfs等。本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的md5值计算,后端写入的速度还是比较快。如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:https://help.aliyun.com/product/31815.html阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
SpringBoot 优雅实现超大文件上传,通用方案 前言文件上传是一个老生常谈的话题了,在文件相对比较小的情况下,可以直接把文件转化为字节流上传到服务器,但在文件比较大的情况下,用普通的方式进行上传,这可不是一个好的办法,毕竟很少有人会忍受,当文件上传到一半中断后,继续上传却只能重头开始上传,这种让人不爽的体验。那有没有比较好的上传体验呢,答案有的,就是下边要介绍的几种上传方式详细教程秒传1、什么是秒传通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。2、本文实现的秒传核心逻辑a、利用redis的set方法存放文件上传状态,其中key为文件上传的md5,value为是否上传完成的标志位,b、当标志位true为上传已经完成,此时如果有相同文件上传,则进入秒传逻辑。如果标志位为false,则说明还没上传完成,此时需要在调用set的方法,保存块号文件记录的路径,其中key为上传文件md5加一个固定前缀,value为块号文件记录路径分片上传1、什么是分片上传分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。2、分片上传的场景1、大文件上传2、网络环境环境不好,存在需要重传风险的场景断点续传1、什么是断点续传断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。本文的断点续传主要是针对断点上传场景。2、应用场景断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。3、实现断点续传的核心逻辑在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。4、实现流程步骤a、方案一,常规步骤将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;初始化一个分片上传任务,返回本次分片上传唯一标识;按照一定的策略(串行或并行)发送各个分片数据块;发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。b、方案二、本文实现的步骤前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。5、分片上传/断点上传代码实现a、前端采用百度提供的webuploader的插件,进行分片。因本文主要介绍服务端代码实现,webuploader如何进行分片,具体实现可以查看链接: http://fex.baidu.com/webuploader/getting-started.htmlb、后端用两种方式实现文件写入,一种是用RandomAccessFile,如果对RandomAccessFile不熟悉的朋友,可以查看链接: https://blog.csdn.net/dimudan2015/article/details/81910690另一种是使用MappedByteBuffer,对MappedByteBuffer不熟悉的朋友,可以查看链接进行了解: https://www.jianshu.com/p/f90866dcbffc后端进行写入操作的核心代码a、RandomAccessFile实现方式@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS) @Slf4j public class RandomAccessUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile accessTmpFile = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); accessTmpFile = new RandomAccessFile(tmpFile, "rw"); //这个必须与前端设定的值一致 long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); long offset = chunkSize * param.getChunk(); //定位到该分片的偏移量 accessTmpFile.seek(offset); //写入该分片数据 accessTmpFile.write(param.getFile().getBytes()); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessTmpFile); } return false; } } b、MappedByteBuffer实现方式@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER) @Slf4j public class MappedByteBufferUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile tempRaf = null; FileChannel fileChannel = null; MappedByteBuffer mappedByteBuffer = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); tempRaf = new RandomAccessFile(tmpFile, "rw"); fileChannel = tempRaf.getChannel(); long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); //写入该分片数据 long offset = chunkSize * param.getChunk(); byte[] fileData = param.getFile().getBytes(); mappedByteBuffer = fileChannel .map(FileChannel.MapMode.READ_WRITE, offset, fileData.length); mappedByteBuffer.put(fileData); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.freedMappedByteBuffer(mappedByteBuffer); FileUtil.close(fileChannel); FileUtil.close(tempRaf); } return false; } } c、文件操作核心模板类代码@Slf4j public abstract class SliceUploadTemplate implements SliceUploadStrategy { public abstract boolean upload(FileUploadRequestDTO param); protected File createTmpFile(FileUploadRequestDTO param) { FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class); param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath())); String fileName = param.getFile().getOriginalFilename(); String uploadDirPath = filePathUtil.getPath(param); String tempFileName = fileName + "_tmp"; File tmpDir = new File(uploadDirPath); File tmpFile = new File(uploadDirPath, tempFileName); if (!tmpDir.exists()) { tmpDir.mkdirs(); } return tmpFile; } @Override public FileUploadDTO sliceUpload(FileUploadRequestDTO param) { boolean isOk = this.upload(param); if (isOk) { File tmpFile = this.createTmpFile(param); FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile); return fileUploadDTO; } String md5 = FileMD5Util.getFileMD5(param.getFile()); Map<Integer, String> map = new HashMap<>(); map.put(param.getChunk(), md5); return FileUploadDTO.builder().chunkMd5Info(map).build(); } /** * 检查并修改文件上传进度 */ public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) { String fileName = param.getFile().getOriginalFilename(); File confFile = new File(uploadDirPath, fileName + ".conf"); byte isComplete = 0; RandomAccessFile accessConfFile = null; try { accessConfFile = new RandomAccessFile(confFile, "rw"); //把该分段标记为 true 表示完成 System.out.println("set part " + param.getChunk() + " complete"); //创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127 accessConfFile.setLength(param.getChunks()); accessConfFile.seek(param.getChunk()); accessConfFile.write(Byte.MAX_VALUE); //completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传) byte[] completeList = FileUtils.readFileToByteArray(confFile); isComplete = Byte.MAX_VALUE; for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) { //与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE isComplete = (byte) (isComplete & completeList[i]); System.out.println("check part " + i + " complete?:" + completeList[i]); } } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessConfFile); } boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete); return isOk; } /** * 把上传进度信息存进redis */ private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath, String fileName, File confFile, byte isComplete) { RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class); if (isComplete == Byte.MAX_VALUE) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true"); redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5()); confFile.delete(); return true; } else { if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false"); redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(), uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf"); } return false; } } /** * 保存文件操作 */ public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) { FileUploadDTO fileUploadDTO = null; try { fileUploadDTO = renameFile(tmpFile, fileName); if (fileUploadDTO.isUploadComplete()) { System.out .println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName); //TODO 保存文件信息到数据库 } } catch (Exception e) { log.error(e.getMessage(), e); } finally { } return fileUploadDTO; } /** * 文件重命名 * * @param toBeRenamed 将要修改名字的文件 * @param toFileNewName 新的名字 */ private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) { //检查要重命名的文件是否存在,是否是文件 FileUploadDTO fileUploadDTO = new FileUploadDTO(); if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) { log.info("File does not exist: {}", toBeRenamed.getName()); fileUploadDTO.setUploadComplete(false); return fileUploadDTO; } String ext = FileUtil.getExtension(toFileNewName); String p = toBeRenamed.getParent(); String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName; File newFile = new File(filePath); //修改文件名 boolean uploadFlag = toBeRenamed.renameTo(newFile); fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp()); fileUploadDTO.setUploadComplete(uploadFlag); fileUploadDTO.setPath(filePath); fileUploadDTO.setSize(newFile.length()); fileUploadDTO.setFileExt(ext); fileUploadDTO.setFileId(toFileNewName); return fileUploadDTO; } } 总结在实现分片上传的过程,需要前端和后端配合,比如前后端的上传块号的文件大小,前后端必须得要一致,否则上传就会有问题。其次文件相关操作正常都是要搭建一个文件服务器的,比如使用fastdfs、hdfs等。本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的md5值计算,后端写入的速度还是比较快。如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:https://help.aliyun.com/product/31815.html阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。 -
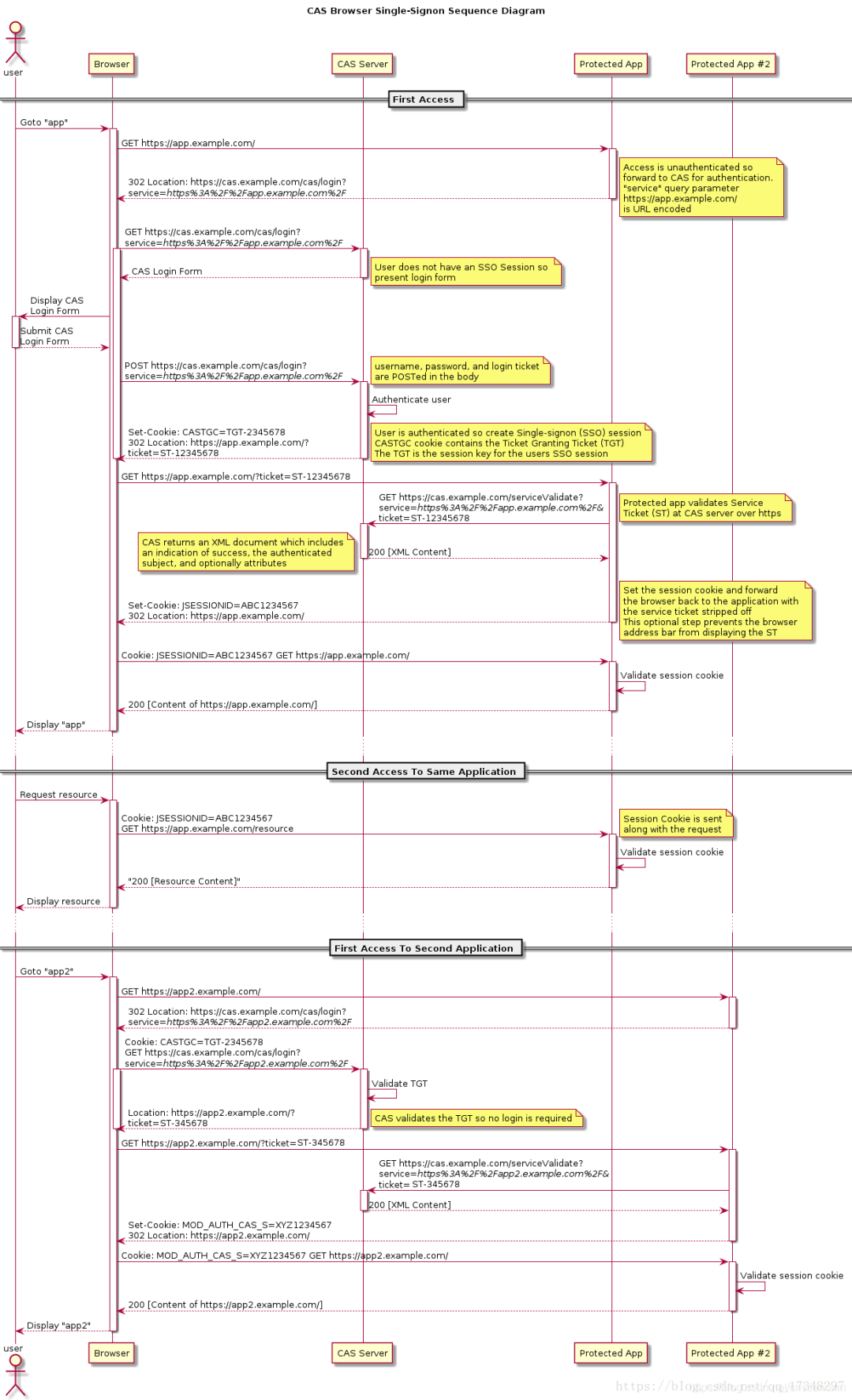
SSO 单点登录和 OAuth2.0 的区别和理解 一、概述SSO 是Single Sign On的缩写,OAuth是Open Authority的缩写,这两者都是使用令牌的方式来代替用户密码访问应用。流程上来说他们非常相似,但概念上又十分不同。SSO大家应该比较熟悉,它将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。OAuth2.0 原理可能比较陌生,但平时用的却很多,比如访问某网站想留言又不想注册时使用了微信授权。以上两者,你在业务系统中都没有账号和密码,账号密码是存放在登录中心或微信服务器中的,这就是所谓的使用令牌代替账号密码访问应用。二、SSO两者有很多相似之处,下面我们来解释一下这个过程。先来讲解SSO,通过SSO对比OAuth2.0,才比较好理解OAuth2.0的原理。SSO的实现有很多框架,比如CAS框架,以下是CAS框架的官方流程图。特别注意:SSO是一种思想,而CAS只是实现这种思想的一种框架而已上面的流程大概为:用户输入网址进入业务系统 Protected App ,系统发现用户未登录,将用户重定向到单点登录系统 CAS Server ,并带上自身地址service参数用户浏览器重定向到单点登录系统,系统检查该用户是否登录,这是SSO(这里是CAS)系统的第一个接口,该接口如果用户未登录,则将用户重定向到登录界面,如果已登录,则设置全局session,并重定向到业务系统用户填写密码后提交登录,注意此时的登录界面是SSO系统提供的,只有SSO系统保存了用户的密码,SSO系统验证密码是否正确,若正确则重定向到业务系统,并带上SSO系统的签发的ticket浏览器重定向到业务系统的登录接口,这个登录接口是不需要密码的,而是带上SSO的ticket,业务系统拿着ticket请求SSO系统,获取用户信息。并设置局部session,表示登录成功返回给浏览器 sessionId (tomcat中叫 JSESSIONID )之后所有的交互用 sessionId 与业务系统交互即可最常见的例子是,我们打开淘宝APP,首页就会有天猫、聚划算等服务的链接,当你点击以后就直接跳过去了,并没有让你再登录一次三、OAuth2.0OAuth2.0 有多种模式,这里讲的是OAuth2.0授权码模式,OAuth2.0的流程跟SSO差不多,在OAuth2中,有授权服务器、资源服务器、客户端这样几个角色,当我们用它来实现SSO的时候是不需要资源服务器这个角色的,有授权服务器和客户端就够了。授权服务器当然是用来做认证的,客户端就是各个应用系统,我们只需要登录成功后拿到用户信息以及用户所拥有的权限即可用户在某网站上点击使用微信授权,这里的某网站就类似业务系统,微信授权服务器就类似单点登录系统之后微信授权服务器返回一个确认授权页面,类似登录界面,这个页面当然是微信的而不是业务系统的用户确认授权,类似填写了账号和密码,提交后微信鉴权并返回一个ticket,并重定向业务系统。业务系统带上ticket访问微信服务器,微信服务器返回正式的token,业务系统就可以使用token获取用户信息了简介一下OAuth2.0的四种模式:授权码(authorization-code)授权码(authorization code)方式,指的是第三方应用先申请一个授权码,然后再用该码获取令牌。这种方式是最常用的流程,安全性也最高,它适用于那些有后端的 Web 应用。授权码通过前端传送,令牌则是储存在后端,而且所有与资源服务器的通信都在后端完成。这样的前后端分离,可以避免令牌泄漏。隐藏式(implicit)有些 Web 应用是纯前端应用,没有后端。这时就不能用上面的方式了,必须将令牌储存在前端。RFC 6749 就规定了第二种方式,允许直接向前端颁发令牌。这种方式没有授权码这个中间步骤,所以称为(授权码)“隐藏式”(implicit)密码式(password)如果你高度信任某个应用,RFC 6749 也允许用户把用户名和密码,直接告诉该应用。该应用就使用你的密码,申请令牌,这种方式称为"密码式"(password)。客户端凭证(client credentials)最后一种方式是凭证式(client credentials),适用于没有前端的命令行应用,即在命令行下请求令牌。简单流程四、说一下几个名词的区别首先,SSO 是一种思想,或者说是一种解决方案,是抽象的,我们要做的就是按照它的这种思想去实现它其次,OAuth2 是用来允许用户授权第三方应用访问他在另一个服务器上的资源的一种协议,它不是用来做单点登录的,但我们可以利用它来实现单点登录。在本例实现SSO的过程中,受保护的资源就是用户的信息(包括,用户的基本信息,以及用户所具有的权限),而我们想要访问这这一资源就需要用户登录并授权,OAuth2服务端负责令牌的发放等操作,这令牌的生成我们采用JWT,也就是说JWT是用来承载用户的Access_Token的最后,Spring Security、Shiro 是用于安全访问的,用来做访问权限控制。
-
小而全的第三方登录开源类库,开箱即用! JustAuth ,如你所见,它仅仅是一个第三方授权登录的工具类库,它可以让我们脱离繁琐的第三方登录 SDK,让登录变得 So easy!JustAuth 集成了诸如:Github、Gitee、支付宝、新浪微博、微信、Google、Facebook、Twitter、StackOverflow 等国内外数十家第三方平台。功能丰富的 OAuth 平台: 集成国内外数十家第三方平台,实现快速接入。自定义 state: 支持自定义 State 和缓存方式,开发者可根据实际情况选择任意缓存插件。自定义 OAuth: 提供统一接口,支持接入任意 OAuth 网站,快速实现 OAuth 登录功能。更容易适配自有的 OAuth 服务。自定义 Http: 接口 HTTP 工具,开发者可以根据自己项目的实际情况选择相对应的 HTTP 工具。自定义 Scope: 支持自定义 scope,以适配更多的业务场景,而不仅仅是为了登录。代码规范·简单: JustAuth 代码严格遵守阿里巴巴编码规约,结构清晰、逻辑简单。快速使用(以 QQ 为例)申请开发者如果是第一次使用,需要到 “QQ 互联平台” 申请开发者,通过后创建应用并且复制三个信息:App ID、App Key和网站回调域。集成 JustAuth添加依赖<dependency> <groupId>me.zhyd.oauth</groupId> <artifactId>JustAuth</artifactId> <version>{latest-version}</version> </dependency>创建Request,把第一步的三个信息添加进去AuthRequest authRequest = new AuthQqRequest(AuthConfig.builder() .clientId("App ID") .clientSecret("App Key") .redirectUri("网站回调域") .build());生成授权地址//这个链接可以直接在后台重定向跳转,也可以返回到前端跳转 String authorizeUrl = authRequest.authorize(AuthStateUtils.createState());或者生成静态授权页面AuthRequest authRequest = AuthRequestBuilder.builder() .source("github") .authConfig(AuthConfig.builder() .clientId("clientId") .clientSecret("clientSecret") .redirectUri("redirectUri") .build()) .build(); // 生成授权页面 authRequest.authorize("state"); // 授权登录后会返回code(auth_code(仅限支付宝))、state,1.8.0版本后,可以用AuthCallback类作为回调接口的参数 // 注:JustAuth默认保存state的时效为3分钟,3分钟内未使用则会自动清除过期的state authRequest.login(callback);或者生成动态授权页面AuthRequest authRequest = AuthRequestBuilder.builder() .source("gitee") .authConfig((source) -> { // 通过 source 动态获取 AuthConfig // 此处可以灵活的从 sql 中取配置也可以从配置文件中取配置 return AuthConfig.builder() .clientId("clientId") .clientSecret("clientSecret") .redirectUri("redirectUri") .build(); }) .build(); Assert.assertTrue(authRequest instanceof AuthGiteeRequest); System.out.println(authRequest.authorize(AuthStateUtils.createState()));JustAuth 的团队还在持续接入其他平台的授权登录,感兴趣的可以关注一下。开源地址:https://github.com/justauth/JustAuth
-
不要再封装各种JAVA Util 工具类了,这个神级框架值得拥有! 今天给大家推荐一个非常好用的Java工具类库,企业级常用工具类,基本都有,能避免重复造轮子及节省大量的开发时间,非常不错,值得大家去了解使用。Hutool 谐音 “糊涂”,寓意追求 “万事都作糊涂观,无所谓失,无所谓得” 的境界。Hutool 是一个 Java 工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让 Java 语言也可以 “甜甜的”。Hutool 最初是我项目中 “util” 包的一个整理,后来慢慢积累并加入更多非业务相关功能,并广泛学习其它开源项目精髓,经过自己整理修改,最终形成丰富的开源工具集。一、功能一个 Java 基础工具类,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行封装,组成各种 Util 工具类,同时提供以下组件:tool-aop JDK 动态代理封装,提供非 IOC 下的切面支持hutool-bloomFilter 布隆过滤,提供一些 Hash 算法的布隆过滤hutool-cache 缓存hutool-core 核心,包括 Bean 操作、日期、各种 Util 等hutool-cron 定时任务模块,提供类 Crontab 表达式的定时任务hutool-crypto 加密解密模块hutool-db JDBC 封装后的数据操作,基于 ActiveRecord 思想hutool-dfa 基于 DFA 模型的多关键字查找hutool-extra 扩展模块,对第三方封装(模板引擎、邮件等)hutool-http 基于 HttpUrlConnection 的 Http 客户端封装hutool-log 自动识别日志实现的日志门面hutool-script 脚本执行封装,例如 Javascripthutool-setting 功能更强大的 Setting 配置文件和 Properties 封装hutool-system 系统参数调用封装(JVM 信息等)hutool-json JSON 实现hutool-captcha 图片验证码实现二、安装maven 项目在 pom.xml 添加以下依赖即可:<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>4.6.3</version> </dependency>三、简单测试DateUtil 日期时间工具类,定义了一些常用的日期时间操作方法。//Date、long、Calendar之间的相互转换 //当前时间 Date date = DateUtil.date(); //Calendar转Date date = DateUtil.date(Calendar.getInstance()); //时间戳转Date date = DateUtil.date(System.currentTimeMillis()); //自动识别格式转换 String dateStr = "2017-03-01"; date = DateUtil.parse(dateStr); //自定义格式化转换 date = DateUtil.parse(dateStr, "yyyy-MM-dd"); //格式化输出日期 String format = DateUtil.format(date, "yyyy-MM-dd"); //获得年的部分 int year = DateUtil.year(date); //获得月份,从0开始计数 int month = DateUtil.month(date); //获取某天的开始、结束时间 Date beginOfDay = DateUtil.beginOfDay(date); Date endOfDay = DateUtil.endOfDay(date); //计算偏移后的日期时间 Date newDate = DateUtil.offset(date, DateField.DAY_OF_MONTH, 2); //计算日期时间之间的偏移量 long betweenDay = DateUtil.between(date, newDate, DateUnit.DAY);StrUtil 字符串工具类,定义了一些常用的字符串操作方法。//判断是否为空字符串 String str = "test"; StrUtil.isEmpty(str); StrUtil.isNotEmpty(str); //去除字符串的前后缀 StrUtil.removeSuffix("a.jpg", ".jpg"); StrUtil.removePrefix("a.jpg", "a."); //格式化字符串 String template = "这只是个占位符:{}"; String str2 = StrUtil.format(template, "我是占位符"); LOGGER.info("/strUtil format:{}", str2);NumberUtil 数字处理工具类,可用于各种类型数字的加减乘除操作及判断类型。double n1 = 1.234; double n2 = 1.234; double result; //对float、double、BigDecimal做加减乘除操作 result = NumberUtil.add(n1, n2); result = NumberUtil.sub(n1, n2); result = NumberUtil.mul(n1, n2); result = NumberUtil.div(n1, n2); //保留两位小数 BigDecimal roundNum = NumberUtil.round(n1, 2); String n3 = "1.234"; //判断是否为数字、整数、浮点数 NumberUtil.isNumber(n3); NumberUtil.isInteger(n3); NumberUtil.isDouble(n3); BeanUtil JavaBean的工具类,可用于Map与JavaBean对象的互相转换以及对象属性的拷贝。 PmsBrand brand = new PmsBrand(); brand.setId(1L); brand.setName("小米"); brand.setShowStatus(0); //Bean转Map Map<String, Object> map = BeanUtil.beanToMap(brand); LOGGER.info("beanUtil bean to map:{}", map); //Map转Bean PmsBrand mapBrand = BeanUtil.mapToBean(map, PmsBrand.class, false); LOGGER.info("beanUtil map to bean:{}", mapBrand); //Bean属性拷贝 PmsBrand copyBrand = new PmsBrand(); BeanUtil.copyProperties(brand, copyBrand); LOGGER.info("beanUtil copy properties:{}", copyBrand);MapUtil Map操作工具类,可用于创建Map对象及判断Map是否为空。//将多个键值对加入到Map中 Map<Object, Object> map = MapUtil.of(new String[][]{ {"key1", "value1"}, {"key2", "value2"}, {"key3", "value3"} }); //判断Map是否为空 MapUtil.isEmpty(map); MapUtil.isNotEmpty(map); AnnotationUtil 注解工具类,可用于获取注解与注解中指定的值。 //获取指定类、方法、字段、构造器上的注解列表 Annotation[] annotationList = AnnotationUtil.getAnnotations(HutoolController.class, false); LOGGER.info("annotationUtil annotations:{}", annotationList); //获取指定类型注解 Api api = AnnotationUtil.getAnnotation(HutoolController.class, Api.class); LOGGER.info("annotationUtil api value:{}", api.description()); //获取指定类型注解的值 Object annotationValue = AnnotationUtil.getAnnotationValue(HutoolController.class, RequestMapping.class);SecureUtil 加密解密工具类,可用于MD5加密。//MD5加密 String str = "123456"; String md5Str = SecureUtil.md5(str); LOGGER.info("secureUtil md5:{}", md5Str);CaptchaUtil 验证码工具类,可用于生成图形验证码。//生成验证码图片 LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200, 100); try { request.getSession().setAttribute("CAPTCHA_KEY", lineCaptcha.getCode()); response.setContentType("image/png");//告诉浏览器输出内容为图片 response.setHeader("Pragma", "No-cache");//禁止浏览器缓存 response.setHeader("Cache-Control", "no-cache"); response.setDateHeader("Expire", 0); lineCaptcha.write(response.getOutputStream()); } catch (IOException e) { e.printStackTrace(); }Hutool中的工具类很多,可以参考官网:https://www.hutool.cn/当然,还有很多其他非常方便的方法,留着你自己去测试吧!使用Hutool工具,可以大大提高你的开发效率!
-
讲的太通透了,切面 AOP 优雅的实现权限校验! 1 理解AOP1.1 什么是AOPAOP(Aspect Oriented Programming) ,面向切面思想,是 Spring 的三大核心思想之一(两外两个:IOC-控制反转、DI-依赖注入)。那么 AOP 为何那么重要呢?在我们的程序中,经常存在一些系统性的需求,比如权限校验、日志记录、统计等,这些代码会散落穿插在各个业务逻辑中,非常冗余且不利于维护。例如下面这个示意图:有多少业务操作,就要写多少重复的校验和日志记录代码,这显然是无法接受的。当然,用面向对象的思想,我们可以把这些重复的代码抽离出来,写成公共方法,就是下面这样:这样,代码冗余和可维护性的问题得到了解决,但每个业务方法中依然要依次手动调用这些公共方法,也是略显繁琐。有没有更好的方式呢?有的,那就是AOP,AOP将权限校验、日志记录等非业务代码完全提取出来,与业务代码分离,并寻找节点切入业务代码中:1.2 AOP体系与概念简单地去理解,其实AOP要做三类事:在哪里切入,也就是权限校验等非业务操作在哪些业务代码中执行。在什么时候切入,是业务代码执行前还是执行后。切入后做什么事,比如做权限校验、日志记录等。因此,AOP的体系可以梳理为下图:一些概念详解:「Pointcut」:切点,决定处理如权限校验、日志记录等在何处切入业务代码中(即织入切面)。切点分为execution方式和annotation方式。前者可以用路径表达式指定哪些类织入切面,后者可以指定被哪些注解修饰的代码织入切面。「Advice」:处理,包括处理时机和处理内容。处理内容就是要做什么事,比如校验权限和记录日志。处理时机就是在什么时机执行处理内容,分为前置处理(即业务代码执行前)、后置处理(业务代码执行后)等。「Aspect」:切面,即Pointcut和Advice。「Joint point」:连接点,是程序执行的一个点。例如,一个方法的执行或者一个异常的处理。在 Spring AOP 中,一个连接点总是代表一个方法执行。「Weaving」:织入,就是通过动态代理,在目标对象方法中执行处理内容的过程。网络上有张图,我觉得非常传神,贴在这里供大家观详:2 AOP实例实践出真知,接下来我们就撸代码来实现一下AOP。完整项目已上传至:GitHub AOP demo项目,该项目是关于springboot的集成项目,AOP部分请关注【aop-demo】模块。使用 AOP,首先需要引入 AOP 的依赖。<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>2.1 第一个实例接下来,我们先看一个极简的例子:所有的get请求被调用前在控制台输出一句"get请求的advice触发了"。具体实现如下:1.创建一个AOP切面类,只要在类上加个 @Aspect 注解即可。@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。@Component 注解将该类交给 Spring 来管理。在这个类里实现advice:package com.mu.demo.advice; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.aspectj.lang.annotation.Pointcut; import org.springframework.stereotype.Component; @Aspect @Component public class LogAdvice { // 定义一个切点:所有被GetMapping注解修饰的方法会织入advice @Pointcut("@annotation(org.springframework.web.bind.annotation.GetMapping)") private void logAdvicePointcut() {} // Before表示logAdvice将在目标方法执行前执行 @Before("logAdvicePointcut()") public void logAdvice(){ // 这里只是一个示例,你可以写任何处理逻辑 System.out.println("get请求的advice触发了"); } }2.创建一个接口类,内部创建一个get请求:package com.mu.demo.controller; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping(value = "/aop") public class AopController { @GetMapping(value = "/getTest") public JSONObject aopTest() { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200}"); } @PostMapping(value = "/postTest") public JSONObject aopTest2(@RequestParam("id") String id) { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200}"); } }项目启动后,请求http://localhost:8085/aop/getTest接口:请求http://localhost:8085/aop/postTest接口,控制台无输出,证明切点确实是只针对被GetMapping修饰的方法。2.2 第二个实例下面我们将问题复杂化一些,该例的场景是:自定义一个注解PermissionsAnnotation创建一个切面类,切点设置为拦截所有标注PermissionsAnnotation的方法,截取到接口的参数,进行简单的权限校验将PermissionsAnnotation标注在测试接口类的测试接口test上具体的实现步骤:1.使用 @Target、@Retention、@Documented 自定义一个注解(关于这三个注解详情请见:元注解详解):@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface PermissionAnnotation{ }2.创建第一个AOP切面类,,只要在类上加个 @Aspect 注解即可。@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。 @Component 注解将该类交给 Spring 来管理。在这个类里实现第一步权限校验逻辑:package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; @Aspect @Component @Order(1) public class PermissionFirstAdvice { // 定义一个切面,括号内写入第1步中自定义注解的路径 @Pointcut("@annotation(com.mu.demo.annotation.PermissionAnnotation)") private void permissionCheck() { } @Around("permissionCheck()") public Object permissionCheckFirst(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("===================第一个切面===================:" + System.currentTimeMillis()); //获取请求参数,详见接口类 Object[] objects = joinPoint.getArgs(); Long id = ((JSONObject) objects[0]).getLong("id"); String name = ((JSONObject) objects[0]).getString("name"); System.out.println("id1->>>>>>>>>>>>>>>>>>>>>>" + id); System.out.println("name1->>>>>>>>>>>>>>>>>>>>>>" + name); // id小于0则抛出非法id的异常 if (id < 0) { return JSON.parseObject("{\"message\":\"illegal id\",\"code\":403}"); } return joinPoint.proceed(); } }3.创建接口类,并在目标方法上标注自定义注解 PermissionsAnnotation :package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping(value = "/permission") public class TestController { @RequestMapping(value = "/check", method = RequestMethod.POST) // 添加这个注解 @PermissionsAnnotation() public JSONObject getGroupList(@RequestBody JSONObject request) { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200}"); } }在这里,我们先进行一个测试。首先,填好请求地址和header:其次,构造正常的参数:可以拿到正常的响应结果:然后,构造一个异常参数,再次请求:响应结果显示,切面类进行了判断,并返回相应结果:有人会问,如果我一个接口想设置多个切面类进行校验怎么办?这些切面的执行顺序如何管理?很简单,一个自定义的AOP注解可以对应多个切面类,这些切面类执行顺序由@Order注解管理,该注解后的数字越小,所在切面类越先执行。下面在实例中进行演示:创建第二个AOP切面类,在这个类里实现第二步权限校验:package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; @Aspect @Component @Order(0) public class PermissionSecondAdvice { @Pointcut("@annotation(com.mu.demo.annotation.PermissionAnnotation)") private void permissionCheck() { } @Around("permissionCheck()") public Object permissionCheckSecond(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("===================第二个切面===================:" + System.currentTimeMillis()); //获取请求参数,详见接口类 Object[] objects = joinPoint.getArgs(); Long id = ((JSONObject) objects[0]).getLong("id"); String name = ((JSONObject) objects[0]).getString("name"); System.out.println("id->>>>>>>>>>>>>>>>>>>>>>" + id); System.out.println("name->>>>>>>>>>>>>>>>>>>>>>" + name); // name不是管理员则抛出异常 if (!name.equals("admin")) { return JSON.parseObject("{\"message\":\"not admin\",\"code\":403}"); } return joinPoint.proceed(); } }重启项目,继续测试,构造两个参数都异常的情况:响应结果,表面第二个切面类执行顺序更靠前:3 AOP相关注解上面的案例中,用到了诸多注解,下面针对这些注解进行详解。3.1 @Pointcut@Pointcut 注解,用来定义一个切点,即上文中所关注的某件事情的入口,切入点定义了事件触发时机。@Aspect @Component public class LogAspectHandler { /** * 定义一个切面,拦截 com.mutest.controller 包和子包下的所有方法 */ @Pointcut("execution(* com.mutest.controller..*.*(..))") public void pointCut() {} }@Pointcut 注解指定一个切点,定义需要拦截的东西,这里介绍两个常用的表达式:一个是使用 execution() ,另一个是使用 annotation() 。execution表达式: 以 execution(* com.mutest.controller...(..))) 表达式为例:第一个 号的位置:表示返回值类型, 表示所有类型。包名:表示需要拦截的包名,后面的两个句点表示当前包和当前包的所有子包,在本例中指 com.mutest.controller包、子包下所有类的方法。第二个 号的位置:表示类名, 表示所有类。(..):这个星号表示方法名, 表示所有的方法,后面括弧里面表示方法的参数,两个句点表示任何参数。annotation() 表达式: annotation() 方式是针对某个注解来定义切点,比如我们对具有 @PostMapping 注解的方法做切面,可以如下定义切面:@Pointcut("@annotation(org.springframework.web.bind.annotation.PostMapping)") public void annotationPointcut() {}然后使用该切面的话,就会切入注解是 @PostMapping 的所有方法。这种方式很适合处理 @GetMapping、@PostMapping、@DeleteMapping 不同注解有各种特定处理逻辑的场景。还有就是如上面案例所示,针对自定义注解来定义切面。@Pointcut("@annotation(com.example.demo.PermissionsAnnotation)") private void permissionCheck() {}3.2 @Around@Around 注解用于修饰Around增强处理,Around增强处理非常强大,表现在:@Around可以自由选择增强动作与目标方法的执行顺序,也就是说可以在增强动作前后,甚至过程中执行目标方法。这个特性的实现在于,调用ProceedingJoinPoint参数的procedd()方法才会执行目标方法。@Around可以改变执行目标方法的参数值,也可以改变执行目标方法之后的返回值。Around增强处理有以下特点:当定义一个Around增强处理方法时,该方法的第一个形参必须是 ProceedingJoinPoint 类型(至少一个形参)。在增强处理方法体内,调用ProceedingJoinPoint的proceed方法才会执行目标方法:这就是@Around增强处理可以完全控制目标方法执行时机、如何执行的关键;如果程序没有调用ProceedingJoinPoint的proceed方法,则目标方法不会执行。调用ProceedingJoinPoint的proceed方法时,还可以传入一个Object[ ]对象,该数组中的值将被传入目标方法作为实参——这就是Around增强处理方法可以改变目标方法参数值的关键。这就是如果传入的Object[ ]数组长度与目标方法所需要的参数个数不相等,或者Object[ ]数组元素与目标方法所需参数的类型不匹配,程序就会出现异常。@Around功能虽然强大,但通常需要在线程安全的环境下使用。因此,如果使用普通的Before、AfterReturning就能解决的问题,就没有必要使用Around了。如果需要目标方法执行之前和之后共享某种状态数据,则应该考虑使用Around。尤其是需要使用增强处理阻止目标的执行,或需要改变目标方法的返回值时,则只能使用Around增强处理了。下面,在前面例子上做一些改造,来观察@Around的特点。自定义注解类不变。首先,定义接口类:package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping(value = "/permission") public class TestController { @RequestMapping(value = "/check", method = RequestMethod.POST) @PermissionsAnnotation() public JSONObject getGroupList(@RequestBody JSONObject request) { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200,\"data\":" + request + "}"); } }唯一切面类(前面案例有两个切面类,这里只需保留一个即可):package com.example.demo; import com.alibaba.fastjson.JSONObject; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; @Aspect @Component @Order(1) public class PermissionAdvice { @Pointcut("@annotation(com.example.demo.PermissionsAnnotation)") private void permissionCheck() { } @Around("permissionCheck()") public Object permissionCheck(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("===================开始增强处理==================="); //获取请求参数,详见接口类 Object[] objects = joinPoint.getArgs(); Long id = ((JSONObject) objects[0]).getLong("id"); String name = ((JSONObject) objects[0]).getString("name"); System.out.println("id1->>>>>>>>>>>>>>>>>>>>>>" + id); System.out.println("name1->>>>>>>>>>>>>>>>>>>>>>" + name); // 修改入参 JSONObject object = new JSONObject(); object.put("id", 8); object.put("name", "lisi"); objects[0] = object; // 将修改后的参数传入 return joinPoint.proceed(objects); } }同样使用JMeter调用接口,传入参数:{"id":-5,"name":"admin"},响应结果表明:@Around截取到了接口的入参,并使接口返回了切面类中的结果。3.3 @Before@Before 注解指定的方法在切面切入目标方法之前执行,可以做一些 Log 处理,也可以做一些信息的统计,比如获取用户的请求 URL 以及用户的 IP 地址等等,这个在做个人站点的时候都能用得到,都是常用的方法。例如下面代码:@Aspect @Component @Slf4j public class LogAspectHandler { /** * 在上面定义的切面方法之前执行该方法 * @param joinPoint jointPoint */ @Pointcut("execution(* com.mutest.controller..*.*(..))") public void pointCut() {} @Before("pointCut()") public void doBefore(JoinPoint joinPoint) { log.info("====doBefore方法进入了===="); // 获取签名 Signature signature = joinPoint.getSignature(); // 获取切入的包名 String declaringTypeName = signature.getDeclaringTypeName(); // 获取即将执行的方法名 String funcName = signature.getName(); log.info("即将执行方法为: {},属于{}包", funcName, declaringTypeName); // 也可以用来记录一些信息,比如获取请求的 URL 和 IP ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); // 获取请求 URL String url = request.getRequestURL().toString(); // 获取请求 IP String ip = request.getRemoteAddr(); log.info("用户请求的url为:{},ip地址为:{}", url, ip); } }JointPoint 对象很有用,可以用它来获取一个签名,利用签名可以获取请求的包名、方法名,包括参数(通过 joinPoint.getArgs() 获取)等。3.4 @After@After 注解和 @Before 注解相对应,指定的方法在切面切入目标方法之后执行,也可以做一些完成某方法之后的 Log 处理。@Aspect @Component @Slf4j public class LogAspectHandler { /** * 定义一个切面,拦截 com.mutest.controller 包下的所有方法 */ @Pointcut("execution(* com.mutest.controller..*.*(..))") public void pointCut() {} /** * 在上面定义的切面方法之后执行该方法 * @param joinPoint jointPoint */ @After("pointCut()") public void doAfter(JoinPoint joinPoint) { log.info("==== doAfter 方法进入了===="); Signature signature = joinPoint.getSignature(); String method = signature.getName(); log.info("方法{}已经执行完", method); } }到这里,我们来写个 Controller 测试一下执行结果,新建一个 AopController 如下:@RestController @RequestMapping("/aop") public class AopController { @GetMapping("/{name}") public String testAop(@PathVariable String name) { return "Hello " + name; } }启动项目,在浏览器中输入:localhost:8080/aop/csdn,观察一下控制台的输出信息:====doBefore 方法进入了==== 即将执行方法为: testAop,属于com.itcodai.mutest.AopController包 用户请求的 url 为:http://localhost:8080/aop/name,ip地址为:0:0:0:0:0:0:0:1 ==== doAfter 方法进入了==== 方法 testAop 已经执行完从打印出来的 Log 中可以看出程序执行的逻辑与顺序,可以很直观的掌握 @Before 和 @After 两个注解的实际作用。3.5 @AfterReturning@AfterReturning 注解和 @After 有些类似,区别在于 @AfterReturning 注解可以用来捕获切入方法执行完之后的返回值,对返回值进行业务逻辑上的增强处理,例如:@Aspect @Component @Slf4j public class LogAspectHandler { /** * 在上面定义的切面方法返回后执行该方法,可以捕获返回对象或者对返回对象进行增强 * @param joinPoint joinPoint * @param result result */ @AfterReturning(pointcut = "pointCut()", returning = "result") public void doAfterReturning(JoinPoint joinPoint, Object result) { Signature signature = joinPoint.getSignature(); String classMethod = signature.getName(); log.info("方法{}执行完毕,返回参数为:{}", classMethod, result); // 实际项目中可以根据业务做具体的返回值增强 log.info("对返回参数进行业务上的增强:{}", result + "增强版"); } }需要注意的是,在 @AfterReturning 注解 中,属性 returning 的值必须要和参数保持一致,否则会检测不到。该方法中的第二个入参就是被切方法的返回值,在 doAfterReturning 方法中可以对返回值进行增强,可以根据业务需要做相应的封装。我们重启一下服务,再测试一下:方法 testAop 执行完毕,返回参数为:Hello CSDN 对返回参数进行业务上的增强:Hello CSDN 增强版3.6 @AfterThrowing当被切方法执行过程中抛出异常时,会进入 @AfterThrowing 注解的方法中执行,在该方法中可以做一些异常的处理逻辑。要注意的是 throwing 属性的值必须要和参数一致,否则会报错。该方法中的第二个入参即为抛出的异常。@Aspect @Component @Slf4j public class LogAspectHandler { /** * 在上面定义的切面方法执行抛异常时,执行该方法 * @param joinPoint jointPoint * @param ex ex */ @AfterThrowing(pointcut = "pointCut()", throwing = "ex") public void afterThrowing(JoinPoint joinPoint, Throwable ex) { Signature signature = joinPoint.getSignature(); String method = signature.getName(); // 处理异常的逻辑 log.info("执行方法{}出错,异常为:{}", method, ex); } }完整的项目已上传至Gtihub:https://github.com/ThinkMugz/aopDemo以上就是AOP的全部内容。通过几个例子就可以感受到,AOP的便捷之处。欢迎大家指出文中不足之处。( •̀ ω •́ )y
-
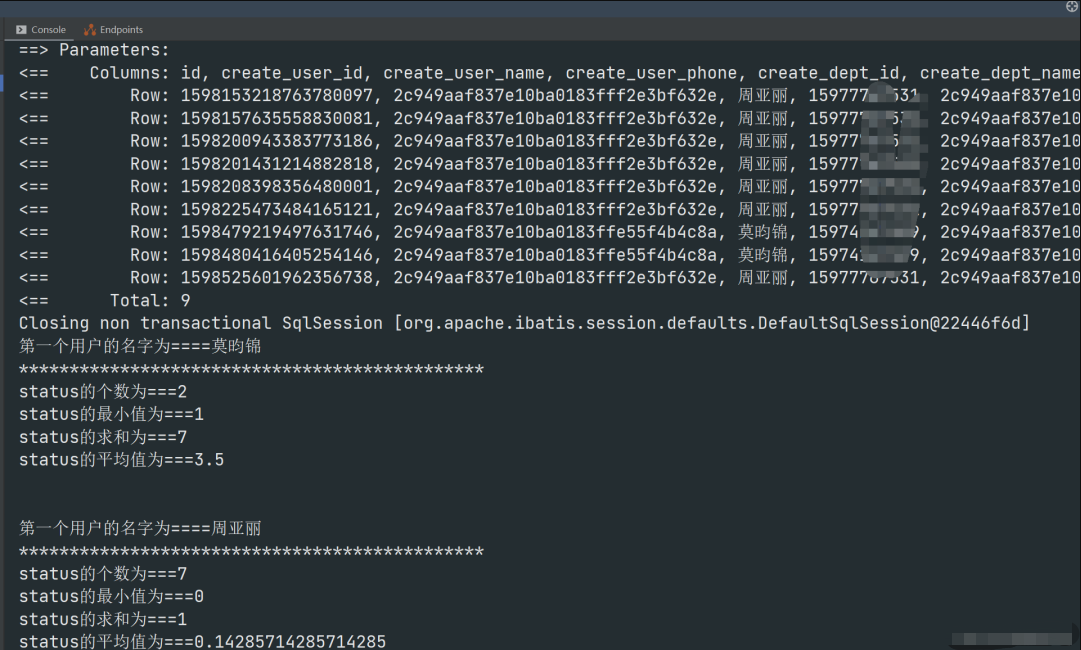
Java8 Stream 一行代码实现数据分组统计、排序、最大值、最小值、平均值、总数、合计 示例:统计用户status的最大值,最小值,求和,平均值分组统计:如果我们想看某个部门下面有哪些数据,可以如下代码求最大值,最小值对某个字段求最大,最小,求和,统计,计数求最大值,最小值还可以这样做对某个字段求和并汇总求某个字段的平均值拼接某个字段的值,可以设置前缀,后缀或者分隔符根据部门进行分组,并获取汇总人数根据部门和是否退休进行分组,并汇总人数根据部门和是否退休进行分组,并取得每组中年龄最大的人Java8 对数据处理可谓十分流畅,既不改变数据,又能对数据进行很好的处理,今天给大家演示下,用Java8的 Stream 如何对数据进行分组统计,排序,求和等这些方法属于Java8的汇总统计类:getAverage(): 它返回所有接受值的平均值。getCount(): 它计算所有元素的总数。getMax(): 它返回最大值。getMin(): 它返回最小值。getSum(): 它返回所有元素的总和。示例:统计用户status的最大值,最小值,求和,平均值看官可以根据自己的需求进行灵活变通@GetMapping("/list") public void list(){ List<InputForm> inputForms = inputFormMapper.selectList(); Map<String, IntSummaryStatistics> collect = inputForms.stream() .collect(Collectors.groupingBy(InputForm::getCreateUserName, Collectors.summarizingInt(InputForm::getStatus))); // 对名字去重 Set<String> collect1 = inputForms.stream().distinct().map(InputForm::getCreateUserName).collect(Collectors.toSet()); // 遍历名字,从map中取出对应用户的status最大值,最小值,平均值。。。 for (String s1 : collect1) { IntSummaryStatistics statistics1 = collect.get(s1); System.out.println("第一个用户的名字为====" + s1); System.out.println("**********************************************"); System.out.println("status的个数为===" + statistics1.getCount()); System.out.println("status的最小值为===" + statistics1.getMin()); System.out.println("status的求和为===" + statistics1.getSum()); System.out.println("status的平均值为===" + statistics1.getAverage()); System.out.println(); System.out.println(); } }结果如下:分组统计:@GetMapping("/list") public void list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); Map<String, Long> collect = inputForms.stream().collect(Collectors.groupingBy(InputForm::getCreateUserName, Collectors.counting())); System.out.println("collect = " + collect); }❝其中Collectors.groupingBy(InputForm::getCreateUserName, Collectors.counting())返回的是一个Map集合,InputForm::getCreateUserName代表key,Collectors.counting()代表value,我是按照创建人的姓名进行统计❞可以看到总共有九条数据,其中莫昀锦有两个,周亚丽有七个如果我们想看某个部门下面有哪些数据,可以如下代码@GetMapping("/list") public Map<String, List<InputForm>> list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); Map<String, List<InputForm>> collect = inputForms.stream() .collect(Collectors.groupingBy(InputForm::getCreateCompanyName)); return collect; }求最大值,最小值@GetMapping("/list") public Map<String, List<InputForm>> list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); Optional<InputForm> min = inputForms.stream() .min(Comparator.comparing(InputForm::getId)); System.out.println("min = " + min); return null; }可以看到此id是最小的,最大值雷同对某个字段求最大,最小,求和,统计,计数@GetMapping("/list") public void list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); IntSummaryStatistics collect = inputForms.stream() .collect(Collectors.summarizingInt(InputForm::getStatus)); double average = collect.getAverage(); int max = collect.getMax(); int min = collect.getMin(); long sum = collect.getSum(); long count = collect.getCount(); System.out.println("collect = " + collect); }求最大值,最小值还可以这样做// 求最大值 Optional<InputForm> max = inputForms.stream().max(Comparator.comparing(InputForm::getAgency)); if (max.isPresent()){ System.out.println("max = " + max); } // 求最小值 Optional<InputForm> min = inputForms.stream().min(Comparator.comparing(InputForm::getAgency)); if (min.isPresent()){ System.out.println("min = " + min); }对某个字段求和并汇总int sum = inputForms.stream().mapToInt(InputForm::getStatus).sum(); System.out.println("sum = " + sum);求某个字段的平均值// 求某个字段的平均值 Double collect2 = inputForms.stream().collect(Collectors.averagingInt(InputForm::getStatus)); System.out.println("collect2 = " + collect2); // 简化后 OptionalDouble average = inputForms.stream().mapToDouble(InputForm::getStatus).average(); if (average.isPresent()){ System.out.println("average = " + average); }拼接某个字段的值,可以设置前缀,后缀或者分隔符// 拼接某个字段的值,用逗号分隔,并设置前缀和后缀 String collect3 = inputForms.stream().map(InputForm::getCreateUserName).collect(Collectors.joining(",", "我是前缀", "我是后缀")); System.out.println("collect3 = " + collect3);根据部门进行分组,并获取汇总人数// 根据部门进行汇总,并获取汇总人数 Map<String, Long> collect4 = inputForms.stream().collect(Collectors.groupingBy(InputForm::getCreateDeptName, Collectors.counting())); System.out.println("collect4 = " + collect4);根据部门和是否退休进行分组,并汇总人数// 根据部门和是否退休进行分组,并汇总人数 Map<String, Map<Integer, Long>> collect5 = inputForms.stream().collect(Collectors.groupingBy(InputForm::getCreateDeptName, Collectors.groupingBy(InputForm::getIsDelete, Collectors.counting()))); System.out.println("collect5 = " + collect5);根据部门和是否退休进行分组,并取得每组中年龄最大的人// 根据部门和是否退休进行分组,并取得每组中年龄最大的人 Map<String, Map<Integer, InputForm>> collect6 = inputForms.stream().collect( Collectors.groupingBy(InputForm::getCreateDeptName, Collectors.groupingBy(InputForm::getIsDelete, Collectors.collectingAndThen( Collectors.maxBy( Comparator.comparing(InputForm::getAge)), Optional::get)))); System.out.println("collect6 = " + collect6);
-
SpringBoot 业务组件化开发,维护起来很香~ 1、背景首先,谈一谈什么是“springBoot业务组件化开发”,最近一直在开发一直面临这一个问题,就是相同的业务场景场景在一个项目中使用了,又需要再另外一个项目中复用,一遍又一遍的复制代码,然后想将该业务的代码在不同的项目中维护起来真的很难。最开始想用微服务的方式来解决这个问题,但是觉得一套完整的微服务太重,而且目前微服务还处于振荡期(去年的微服务解决方案,今年国内直接都换成了阿里的技术解决方案),此外很多时候我们接私活,就是个单体的springboot项目,用不上微服务这种级别的项目,所以想来想去这条路不是很满足我的需求;再后来,想到单体的聚合架构,但是聚合架构的项目,个人觉得有时候也不是很好,一般的聚合项目就是基于某个具体实例架构下才能使用,换一个架构自己写的业务model就不能用了(比如你在suoyi框架下开发的模块业务包,在guns下可能就直接不能使用了)。最后,想了一下,能不能单独开发一个项目,这个项目可以自己独立运行(微服务架构下用),也可以在单体项目中直接通过pom引入的方式,然后简单的配置一下,然后直接使用多好;查了一下网上没有现成的技术解决方案,问了同事,他说我这种思想属于SOA的一种实现,同时有第三包和聚合项目的影子在里面。也许有什么更好的技术解决方案,也希望各位能够不吝赐教。补充一句,之所以说“业务组件化”开发,来源于Vue的思想,希望Java后端开发的业务也可像vue的组件一样去使用,这样多好2、DEMO2-1 项目准备建一个Java项目项目,结构如下图:pom文件如下:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.1.RELEASE</version> </parent> <groupId>top.wp</groupId> <artifactId>cx-flow</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <mysql-connector-java.version>8.0.17</mysql-connector-java.version> <druid.version>1.1.21</druid.version> <mp.version>3.3.2</mp.version> <fastjson.version>1.2.70</fastjson.version> <jwt.version>0.9.1</jwt.version> <hutool.version>5.3.7</hutool.version> <lombok.versin>1.18.12</lombok.versin> <swagger.version>2.9.2</swagger.version> <swagger.bootstrap.ui.version>1.9.6</swagger.bootstrap.ui.version> <easypoi.version>4.2.0</easypoi.version> <jodconverter.version>4.2.0</jodconverter.version> <libreoffice.version>6.4.3</libreoffice.version> <justauth.version>1.15.6</justauth.version> <aliyun.oss.version>3.8.0</aliyun.oss.version> <qcloud.oss.version>5.6.23</qcloud.oss.version> <aliyun.sms.sdk.version>4.4.6</aliyun.sms.sdk.version> <aliyun.sms.esc.version>4.17.6</aliyun.sms.esc.version> <qcloud.sms.sdk.version>3.1.57</qcloud.sms.sdk.version> </properties> <dependencies> <!-- web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--mybatis-plus--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>${mp.version}</version> </dependency> <!--数据库驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql-connector-java.version}</version> </dependency> <!--数据库连接池--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>${druid.version}</version> </dependency> <!--hutool--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>${hutool.version}</version> </dependency> <!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.versin}</version> </dependency> </dependencies> <build> <resources> <resource> <directory>src/main/resources</directory> <!-- <excludes> <exclude>**/*.properties</exclude> <exclude>**/*.xml</exclude> </excludes> --> <includes> <include>**/*.properties</include> <include>**/*.xml</include> <include>**/*.yml</include> </includes> <filtering>false</filtering> </resource> <resource> <directory>src/main/java</directory> <includes> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> </resources> </build> </project>配置文件如下:主要是数据库和mybaits-plus的配置(其实可以不用这个配置文件,在这只是为了项目能够独立运行起来)#服务配置 server: port: 8080 #spring相关配置 spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/cx-xn?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=CONVERT_TO_NULL&useSSL=false&serverTimezone=CTT&nullCatalogMeansCurrent=true username: 数据库账户 password: 数据库密码 servlet: multipart: max-request-size: 100MB max-file-size: 100MB jackson: time-zone: GMT+8 date-format: yyyy-MM-dd HH:mm:ss.SSS locale: zh_CN serialization: # 格式化输出 indent_output: false #mybaits相关配置 mybatis-plus: mapper-locations: classpath*:top/wp/cx/**/mapping/*.xml, classpath:/META-INF/modeler-mybatis-mappings/*.xml configuration: map-underscore-to-camel-case: true cache-enabled: true lazy-loading-enabled: true multiple-result-sets-enabled: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: banner: false db-config: id-type: assign_id table-underline: true enable-sql-runner: true configuration-properties: prefix: blobType: BLOB boolValue: TRUE启动入口(可以不用写,启动入口存在目的是让项目可以自己跑起来)package top.wp.cx; import cn.hutool.log.StaticLog; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class CXApplication { public static void main(String[] args) { SpringApplication.run(CXApplication.class, args); StaticLog.info(">>> " + CXApplication.class.getSimpleName() + " 启动成功!"); } }测试:entity、resultpackage top.wp.cx.modular.test.entity; import com.baomidou.mybatisplus.annotation.IdType; import com.baomidou.mybatisplus.annotation.TableId; import com.baomidou.mybatisplus.annotation.TableName; import lombok.Data; @Data @TableName("test") public class Test { /** * 主键 */ @TableId(type = IdType.ASSIGN_ID) private Integer id; /** * 账号 */ private String name; } package top.wp.cx.modular.test.result; import lombok.Data; @Data public class TestResult { private Integer id; private String name; }测试mapper、xml、service和controllerpackage top.wp.cx.modular.test.mapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import top.wp.cx.modular.test.entity.Test; /** * 系统用户数据范围mapper接口 * * @author xuyuxiang * @date 2020/3/13 15:46 */ //@Mapper public interface TestMapper extends BaseMapper<Test> { } <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="top.wp.cx.modular.test.mapper.TestMapper"> </mapper> package top.wp.cx.modular.test.service; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import org.springframework.stereotype.Service; import top.wp.cx.modular.test.entity.Test; import top.wp.cx.modular.test.mapper.TestMapper; /** * 一个service实现 * * @author yubaoshan * @date 2020/4/9 18:11 */ @Service public class TestService extends ServiceImpl<TestMapper, Test> { } package top.wp.cx.modular.test.controller; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import top.wp.cx.modular.test.entity.Test; import top.wp.cx.modular.test.service.TestService; import javax.annotation.Resource; import java.util.List; /** * 一个示例接口 * * @author yubaoshan * @date 2020/4/9 18:09 */ @RestController @RequestMapping("/test") public class TestController { @Resource private TestService testService; @GetMapping("") public List<Test> testResult(){ return testService.list(); } @GetMapping("/2") public String testResult2(){ return "22"; } }至此项目准备完成,其实就是简单见了一个测试项目,此时如果你按照上面的步骤,写了启动类和配置项信息,项目是可以独立运行的。2-2 项目打包、引入、运行将2-1中的测试项目进行打包:install右键第一个选项此时你的本地maven仓库会出现刚才的项目(当然前提是你的idea配置过本地的maven)新建另外一个项目cx-mainpom文件如下:注意将你刚才的准备测试的项目引入进来<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.1.RELEASE</version> </parent> <groupId>top.wp.cx</groupId> <artifactId>cx-main</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <mysql-connector-java.version>8.0.17</mysql-connector-java.version> <druid.version>1.1.21</druid.version> <mp.version>3.3.2</mp.version> <fastjson.version>1.2.70</fastjson.version> <jwt.version>0.9.1</jwt.version> <hutool.version>5.3.7</hutool.version> <lombok.versin>1.18.12</lombok.versin> <swagger.version>2.9.2</swagger.version> <swagger.bootstrap.ui.version>1.9.6</swagger.bootstrap.ui.version> <easypoi.version>4.2.0</easypoi.version> <jodconverter.version>4.2.0</jodconverter.version> <libreoffice.version>6.4.3</libreoffice.version> <justauth.version>1.15.6</justauth.version> <aliyun.oss.version>3.8.0</aliyun.oss.version> <qcloud.oss.version>5.6.23</qcloud.oss.version> <aliyun.sms.sdk.version>4.4.6</aliyun.sms.sdk.version> <aliyun.sms.esc.version>4.17.6</aliyun.sms.esc.version> <qcloud.sms.sdk.version>3.1.57</qcloud.sms.sdk.version> </properties> <dependencies> <dependency> <groupId>top.wp</groupId> <artifactId>cx-flow</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <!-- web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--mybatis-plus--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>${mp.version}</version> </dependency> <!--数据库驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql-connector-java.version}</version> </dependency> <!--数据库连接池--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>${druid.version}</version> </dependency> <!--hutool--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>${hutool.version}</version> </dependency> <!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.versin}</version> </dependency> </dependencies> <!--xml打包排除--> <build> <resources> <resource> <directory>src/main/resources</directory> <!-- <excludes> <exclude>**/*.properties</exclude> <exclude>**/*.xml</exclude> </excludes> --> <includes> <include>**/*.properties</include> <include>**/*.xml</include> <include>**/*.yml</include> </includes> <filtering>false</filtering> </resource> <resource> <directory>src/main/java</directory> <includes> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> </resources> </build> </project>application.yml配置文件 注意xml的扫描#服务配置 server: port: 8081 #spring相关配置 spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/cx-xn?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=CONVERT_TO_NULL&useSSL=false&serverTimezone=CTT&nullCatalogMeansCurrent=true username: root password: root servlet: multipart: max-request-size: 100MB max-file-size: 100MB jackson: time-zone: GMT+8 date-format: yyyy-MM-dd HH:mm:ss.SSS locale: zh_CN serialization: # 格式化输出 indent_output: false #mybaits相关配置 mybatis-plus: #xml文件扫描 mapper-locations: classpath*:top/wp/cx/**/mapping/*.xml, classpath:/META-INF/modeler-mybatis-mappings/*.xml configuration: map-underscore-to-camel-case: true cache-enabled: true lazy-loading-enabled: true multiple-result-sets-enabled: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: banner: false db-config: id-type: assign_id table-underline: true enable-sql-runner: true configuration-properties: prefix: blobType: BLOB boolValue: TRUE启动入口,注意spring和mapper扫描package top.wp.cx.main; import cn.hutool.log.StaticLog; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.ComponentScan; @SpringBootApplication @ComponentScan(basePackages = {"top.wp.cx.modular.test"}) // spring扫描 @MapperScan(basePackages = {"top.wp.cx.modular.test.**.mapper"}) // mybatis扫描mapper public class CXApplication { public static void main(String[] args) { SpringApplication.run(CXApplication.class, args); StaticLog.info(">>> " + CXApplication.class.getSimpleName() + " 启动成功!"); } }此时启动cx-main的项目,访问2-1的测试controller能访问成功证明配置正确。
-
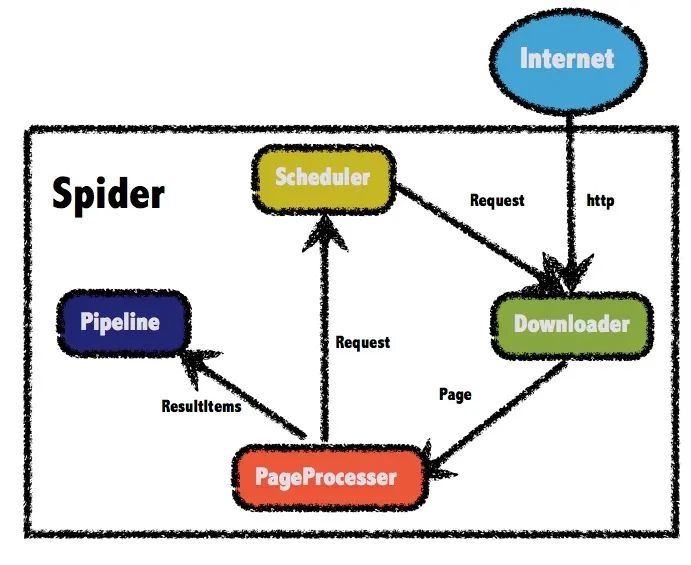
用 Java 写爬虫 前两天,百度紧随 GPT-4 发布了自己的语言模型文心一言。讲道理,对于国内能够发布这样一个敢于对标CHAT GPT的高质量语言模型,大家应该更多感受到的是赛博朋克与现实生活贴近的真实感,对这个模型应该有着更多的鼓励或赞美。可不知是因为整个发布会搞的过于像没有好好准备的学生毕业答辩PPT,还是它的实际表现并没有那么如人意,大家貌似对文心一言并不那么买账。于是我决定看一下知乎大神们对文心一言的评价,哪想到随便打开一个问题,居然有600多条回答…要是我这一条一条翻完所有回答,估计就得拿出一天来全职摸鱼了,那么有没有什么办法能够最快的分析出对待这个问题大家的综合评价呢?那么今天就让我纱布擦屁股,给大家露一小手,写一个爬虫扒下来所有的回答,再对结果进行一下分析。WebMagic正式开始前,咱们得先搞定工具。虽然python写起爬虫来有天然的框架优势,不过鉴于大家都是搞java的,那么我们今天就用java框架来实现一个爬虫。咱们要使用的工具 WebMagic ,就是一款简单灵活的java爬虫框架,总体架构由下面这几部分构成:Downloader:负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。PageProcessor:负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。Scheduler:负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。Pipeline:负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了输出到控制台和保存到文件两种结果处理方案。在4个主要组件中,除了 PageProcessor 之外,其他3个组件基本都可以复用。而我们实际爬虫中的重点,就是要针对不同网页进行页面元素的分析,进而定制化地开发不同的 PageProcessor 。下面我们开始准备实战,先引入 webmagic 的 core 和 extension 两个依赖,最新0.8.0版本搞里头:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.8.0</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.8.0</version> </dependency>PageProcessor 与 xpath 在正式开始抓取页面前,我们先看看知乎上一个问题的页面是怎么构成的,还是以上面图中那个问题为例,原问题的地址在这里:https://www.zhihu.com/question/589929380我们先做个简单的测试,来获取这个问题的标题,以及对这个问题的描述。通过浏览器的审查元素,可以看到标题是一个h1的标题元素,并且它的class属性是QuestionHeader-title,而问题的描述部分在一个div中,它的class中包含了QuestionRichText。简单分析完了,按照前面说的,我们要对这个页面定制一个 PageProcessor组件 抽取信息,直接上代码。新建一个类实现 PageProcessor接口 ,并实现接口中的 process() 这个方法即可。public class WenxinProcessor implements PageProcessor { private Site site = Site.me() .setRetryTimes(3).setSleepTime(1000); @Override public void process(Page page) { String title = page.getHtml() .xpath("//h1[@class='QuestionHeader-title']/text()").toString(); String question= page.getHtml() .xpath("//div[@class='QuestionRichText']//tidyText()").toString(); System.out.println(title); System.out.println(question); } public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .run(); } }查看运行结果:可以看到,在代码中通过 xpath() 这样一个方法,成功拿到了我们要取的两个元素。其实说白了,这个 xpath 也不是爬虫框架中才有的新玩意,而是一种 XML 路径语言(XML Path Language),是一种用来确定XML文档中某部分位置的语言。它基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。常用的路径表达式包括:表达式描述nodename选取此节点的所有子节点。/从根节点选取。//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。.选取当前节点。..选取当前节点的父节点。@选取属性。在上面的代码中,//h1[@class='QuestionHeader-title']就表示选取一个类型为 h1 的节点,并且它有一个 class 为 QuestionHeader-title 的属性。至于后面的 text() 和 tidyText() 方法,则是用于提取元素中的文本,这些函数不是标准 xpath 中的,而是 webMagic 中特有的新方法,这些函数的使用可以参考文档:http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html看到这,你可能还有个问题,这里对于问题的描述部分没有显示完全,你需要在页面上点一下这个显示全部它才会显示详细的信息。没关系,这里先留个坑,这个问题放在后面解决。获取提问的答案我们完善一下上面的代码,尝试获取问题的解答。按照老套路,还是先分析页面元素再用 xpath 写表达式获取。修改 process 方法:@Override public void process(Page page) { String contentPath= "div[@class='QuestionAnswers-answers']"+ "//div[@class='RichContent RichContent--unescapable']" + "//div[@class='RichContent-inner']"+ "/tidyText()"; List<String> answerList = page.getHtml().xpath(contentPath).all(); for (int i = 0; i < answerList.size(); i++) { System.out.println("第"+(i+1)+"条回答:"); System.out.println(answerList.get(i)+"\n======="); } }在上面的代码中,使用了 xpath 获取页面中具有相同属性的元素,并将它们存入了 List 列表中。看一下运行结果:纳尼?这个问题明明有着689条的回答,为什么我们只爬到了两条答案?如果你经常用知乎来学习摸鱼的话,其实就会知道对于这种有大量回答的问题,页面刚开始只会默认显示很少的几条的消息,随着你不断的下拉页面才会把新的回答显示出来。那么如果我想拿到所有的评论应该怎么做呢?这时候就要引出 webMagic 中另一个神奇的组件 Selenium 了。Selenium简单来说, selenium 是一个用于 Web应用程序 测试的工具, selenium 测试可以直接运行在浏览器中,就像真正的用户在操作一样,并且目前主流的大牌浏览器一般都支持这项技术。所以在爬虫中,我们可以通过编写模仿用户操作的 selenium脚本 ,模拟进行一部分用互操作,比如点击事件或屏幕滚动等等。WebMagic-Selenium 需要依赖于 WebDriver ,所以我们先进行本地 WebDriver 的安装操作。安装WebDriver 查看自己电脑上 Chrome 版本,可以点击 设置 -> 关于chrome 查看,也可以直接在地址栏输入 chrome://settings/help :可以看到版本号,然后需要下载对应版本的 WebDriver ,下载地址:http://chromedriver.storage.googleapis.com/index.html打开后,可以看到各个版本,选择与本地浏览器最接近的版本:点击进入后,根据我们的系统选择对应版本下载即可。下载完成后,解压到本地目录中,之后在使用 selenium模块 中会使用到。这个文件建议放在 chrome安装目录 下,否则之后在代码中可能会报一个 WebDriverException: unknown error: cannot find Chrome binary 找不到 chrome文件的错误 。修改Selenium源码webMagic 中已经封装了 selenium模块 的代码,但官方版本的代码有些地方需要修改,我们下载源码后要自己简单改动一下然后重新编译。我这下载了 0.8.1-SNAPSHOT 版本的代码,官方 git 地址:https://github.com/code4craft/webmagic修改配置文件地址,在 WebDriverPool 将 selenium配置文件 路径写死了,需要改变配置路径:// 修改前 // private static final String DEFAULT_CONFIG_FILE = "/data/webmagic/webmagic-selenium/config.ini"; // 修改后 private static final String DEFAULT_CONFIG_FILE = "selenium.properties";在 resources目录 下添加配置文件 selenium.properties :# What WebDriver to use for the tests driver=chrome # PhantomJS specific config (change according to your installation) chrome_driver_loglevel=DEBUGjs模拟页面操作修改 SeleniumDownloader 的 download()方法 ,在代码中的这个位置,作者很贴心的给我们留了一行注释:意思就是,你可以在这添加鼠标事件或者干点别的什么东西了。我们在这添加页面向下滚动这一模拟事件,每休眠 2s 就向下滚动一下页面,一共下拉 20 次://模拟下拉,刷新页面 for (int i=0; i < 20; i++){ System.out.println("休眠2s"); try { //滚动到最底部 ((JavascriptExecutor)webDriver) .executeScript("window.scrollTo(0,document.body.scrollHeight)"); //休眠,等待加载页面 Thread.sleep(2000); //往回滚一点,否则不加载 ((JavascriptExecutor)webDriver) .executeScript("window.scrollBy(0,-300)"); } catch (InterruptedException e) { e.printStackTrace(); } }修改完成后本地打个包,注意还要修改一下版本号,改成和发行版的不同即可,我这里改成了 0.8.1.1-SNAPSHOT 。mvn clean install调用回到之前的爬虫项目,引入我们自己打好的包:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-selenium</artifactId> <version>0.8.1.1-SNAPSHOT</version> </dependency>修改之前的主程序启动时的代码,添加 Downloader 组件, SeleniumDownloader 构造方法的参数中传入我们下好的 chrome 的 webDriver 的可执行文件的地址:public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }进行测试,可以看到在拉动了40秒窗口后,获取到的答案条数是100条:通过适当地添加下拉页面的循环的次数,我们就能够获取到当前问题下的全部回答了。另外,在启动爬虫后我们会看到 webDriver 弹出了一个 chrome 的窗口,在这个窗口中有一个提示: Chrome 正受到自动测试软件的控制,并且可以看到页面不断的自动下拉情况:如果不想要这个弹窗的话,可以修改 selenium模块 的代码进行隐藏。修改 WebDriverPool 的 configure()方法 ,找到这段代码:if (driver.equals(DRIVER_CHROME)) { mDriver = new ChromeDriver(sCaps); }添加一个隐藏显示的选项,并且在修改完成后,重新打包一下。if (driver.equals(DRIVER_CHROME)) { ChromeOptions options=new ChromeOptions(); options.setHeadless(true); mDriver = new ChromeDriver(options); }获取问题详细描述不知道大家还记不记得在前面还留了一个坑,我们现在获取到的对问题的描述是不全的,需要点一下这个按钮才能显示完全。同样,这个问题也可以用 selenium 来解决,在我们下拉页面前,加上这么一个模拟点击事件,就可以获得对问题的详细描述了:((JavascriptExecutor)webDriver) .executeScript("document.getElementsByClassName('Button QuestionRichText-more')[0].click()");看一下执行结果,已经可以拿到完整内容了:Pipeline到这里,虽然要爬的数据获取到了,但是要进行分析的话,还需要进行持久化操作。在前面的 webMagic 的架构图中,介绍过 Pipeline组件 主要负责结果的处理,所以我们再优化一下代码,添加一个 Pipeline 负责数据的持久化。由于数据量也不是非常大,这里我选择了直接存入 ElasticSearch 中,同时也方便我们进行后续的分析操作, ES组件 我使用的是 esclientrhl ,为了方便我还是把项目整个扔到了 spring 里面。定制一个 Pipeline 也很简单,实现 Pipeline接口 并实现里面的 process()接口 就可以了,通过构造方法传入 ES 持久化层组件:@Slf4j @AllArgsConstructor public class WenxinPipeline implements Pipeline { private final ZhihuRepository zhihuRepository; @Override public void process(ResultItems resultItems, Task task) { Map<String, Object> map = resultItems.getAll(); String title = map.get("title").toString(); String question = map.get("question").toString(); List<String> answer = (List<String>) map.get("answer"); ZhihuEntity zhihuEntity; for (String an : answer) { zhihuEntity = new ZhihuEntity(); zhihuEntity.setTitle(title); zhihuEntity.setQuestion(question); zhihuEntity.setAnswer(an); try { zhihuRepository.save(zhihuEntity); } catch (Exception e) { e.printStackTrace(); } } } }把 selenium 向下拉取页面的次数改成200后,通过接口启动程序:@GetMapping("wenxin") public void wenxin() { new Thread(() -> { Request request = new Request("https://www.zhihu.com/question/589929380"); WenxinProcessor4 wenxinProcessor = new WenxinProcessor4(); Spider.create(wenxinProcessor) .addRequest(request) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }).start(); }运行完成后,查询一下 ES 中的数据,可以看到,实际爬取到了673条回答。另外,我们可以在一个爬虫程序中传入多个页面地址,只要页面元素具有相同的规则,那么它们就能用相同的爬虫逻辑处理,在下面的代码中,我们一次性传入多个页面:Spider.create(new WenxinProcessor4()) .addUrl(new String[]{"https://www.zhihu.com/question/589941496", "https://www.zhihu.com/question/589904230","https://www.zhihu.com/question/589938328"}) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run();一顿忙活下来,最终扒下来1300多条数据。分析数据落到了 ES 里后,那我们就可以根据关键字进行分析了,我们先选择10个负面方向的词语进行查询,可以看到查到了403条数据,将近占到了总量的三分之一。再从各种回答中选择10个正向词语查询,结果大概只有负面方向的一半左右:不得不说,这届网友真的是很严厉…Proxy代理说到爬虫,其实还有一个绕不过去的东西,那就是代理。像咱们这样的小打小闹,爬个百八十条数据虽然没啥问题,但是如果要去爬取大量数据或是用于商业,还是建议使用一下代理,一方面能够隐藏我们的IP地址起到保护自己的作用,另一方面动态IP也能有效的应对一些反爬策略。个人在使用中,比较推荐的是隧道代理。简单的来说,如果你购买了IP服务的话,用普通代理方式的话需要你去手动请求接口获取IP地址,再到代码中动态修改。而使用隧道代理的话,就不需要自己提取代理IP了,每条隧道自动提取并使用代理IP转发用户请求,这样我们就可以专注于业务了。虽然网上也有免费的代理能够能用,但要不然就是失效的太快,要不就是很容易被网站加入黑名单,所以如果追求性能的话还是买个专业点的代理比较好,虽然可能价格不那么便宜就是了。最后附上源码下载地址源码地址:https://github.com/trunks2008/zhihu-spider
-
面试官:从 MySQL 读取 百万 数据进行处理,应该怎么做?问倒一大片! 背景大数据量操作的场景大致如下:数据迁移数据导出批量处理数据在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。但有些情况不需要分页的方式查询数据或分很大一页查询数据时,如果一下子将数据全部加载出来到内存中,很可能会发生 OOM(内存溢出) ;而且查询会很慢,因为框架耗费大量的时间和内存去把数据库查询的结果封装成我们想要的对象(实体类)。举例:在业务系统需要从 MySQL 数据库里读取 100万 数据行进行处理,应该怎么做? 做法通常如下:常规查询:一次性读取 100万 数据到 JVM 内存中,或者分页读取流式查询:建立长连接,利用服务端游标,每次读取一条加载到 JVM 内存(多次获取,一次一行)游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据(多次获取,一次多行)常规查询默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于 MySQL 网络协议的设计,因此更易于实现。举例:假设单表 100万 数据量,一般会采用分页的方式查询:@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); }注:该示例使用的 MybatisPlus。该方式比较简单,如果在不考虑 LIMIT 深分页优化情况下,估计你的数据库服务器就噶皮了,或者你能等上几十分钟或几小时,甚至几天时间检索数据。流式查询流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 100万 条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。MyBatis 流式查询接口 MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:Cursor 是可关闭的;Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed():用于判断查询结果是否全部取完。getCurrentIndex():返回已经获取了多少条数据使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理为什么要用流式查询? 如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了 sharding-sphere 的代码不难发现,除了 group by 与 order by 字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。游标查询对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。这种处理方式比常规查询要快很多。当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。Mybatis 的处理加了两个注解: @Options 和 @ResultType@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { // 方式一 多次获取,一次多行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000) Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); // 方式二 一次获取,一次一行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000) @ResultType(BigDataSearchEntity.class) void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler); }@OptionsResultSet.FORWORD_ONLY:结果集的游标只能向下滚动ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变fetchSize:每次获取量@ResultType@ResultType(BigDataSearchEntity.class):转换成返回实体类型注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。注意: 虽然上面的代码中都有 @Options 但实际操作却有不同:方式一是多次查询,一次返回多条;方式二是一次查询,一次返回一条;原因: Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。非流式查询和流式查询区别:非流式查询:内存会随着查询记录的增长而近乎直线增长。流式查询:内存会保持稳定,不会随着记录的增长而增长。其内存大小取决于批处理大小BATCH_SIZE的设置,该尺寸越大,内存会越大。所以BATCH_SIZE应该根据业务情况设置合适的大小。另外要切记每次处理完一批结果要记得释放存储每批数据的临时容器,即上文中的 gxids.clear() ;
-
Docker部署 Mysql、redis、Rabbitmq、Vue、Java 项目 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux 或 Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。本文主要讲解如何在Linux环境下使用 Docker 部署前后端分离项目,其中涉及到使用 Docker 安装本人项目相关的一些环境 ,例如mysql、rabbitmq、redis,基于CenterOS7.0。Docker 环境安装1.安装 Docker 客户端# step 1: 安装必要的一些系统工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # Step 2: 添加软件源信息 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # Step 3: 更新并安装 Docker-CE sudo yum makecache fast sudo yum -y install docker-ce # Step 4: 开启Docker服务 sudo service docker start2.配置镜像加速器sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://sq2b0kv9.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker安装 PortainerPortainer 是一个轻量级 Web 端的 Docker 管理 UI,Portainer 够轻松地管理不同的 Docker 环境(Docker 主机或集群)。Portainer 的部署和使用十分简单。Portainer 可以部署为 Linux 容器或 Windows 本机容器,也支持其他平台。Portainer 允许您管理所有 Docker 资源(容器、映像、卷、网络等)!它与独立的 Docker 引擎和 Docker 集群模式兼容。1.安装# 拉取官方镜像 docker pull portainer/portainer # 运行镜像到容器 docker run -d -p 9000:9000\ --restart=always\ -v /var/run/docker.sock:/var/run/docker.sock\ -m 20M --oom-kill-disable --memory-swap=-1\ --name portainer\ portainer/portainer2.访问页面访问地址:http://localhost:9000,第一次打开需要设置用户名、密码,docker 模式我一般选择 Local 本机模式。通过此工具我们可以更加简便的对镜像和容器进行操作和管理。登录页 面板页 安装 mysql# docker search mysql 可通过此命令查看可用版本 # 拉取mysql镜像,默认会拉取最新版本,我这里加上版本号 docker pull mysql:8.0.0 # 查看镜像是否拉取成功 docker images # 在/home/docker/mysql目录下创建mysql挂载目录 mkdir {data,logs,conf} # 运行容器 docker run -d -p 3306:3306 -v /home/docker/mysql/my.cnf:/etc/mysql/conf.d/mysqld.cnf -v /home/docker/mysql/data:/var/lib/mysql -v /home/docker/mysql/logs:/var/log/mysql -e MYSQL_ROOT_PASSWORD=12345 --name mysql_test mysql:8.0.0说明:--name:容器名-e:配置信息,此处配置 mysql 的 root 用户登陆密码-d:后台运行容器,保证在退出终端后容器继续运行-p:端口映射,此处映射 主机 3306 端口 到 容器的 3306 端口-v:挂载目录此处需要注意不要直接挂载容器中的 mysql 配置文件目录,可能会将容器内的配置文件目录清空。个人建议将容器中的 my.cnf 文件复制出来进行选择性的修改,再挂载 mysql.cnf 文件即可。docker cp :用于容器与主机之间的数据拷贝。# 语法 docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|- # 实例 docker cp 96f7f14e99ab:/etc/mysql/conf.d/mysqld.cnf /home/docker/mysql/my.cnf安装 redis因为 redis 默认配置只能够本地连接,不能进行远程访问,使用 Redis 客户端工具连接都会报错,因此需要手动挂载 redis 配置文件。# /home/docker/redis目录下新增挂载文件夹 mkdir {data,conf} # 下载最新版本的Redis镜像 docker pull redis # 新增redis配置文件 cd /home/docker/redis/conf touch redis.conf vim redis.conf添加以下内容#bind 127.0.0.1 protected-mode no appendonly yes requirepass 123456说明:bind 127.0.0.1 ,注释掉这部分,这是限制 redis 只能本地访问protected-mode:默认 yes,开启保护模式,限制为本地访问appendonly:redis 持久化(可选)requirepass:设置访问密码为 123456运行容器docker run --name myredis -p 6379:6379 -v /home/docker/redis/data:/data -v /home/docker/redis/conf/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf说明:--name:容器名称-p :表示将服务器的 6379(冒号前的 6379)端口映射到 docker 的 6379(冒号后的 6379)端口-d :表示以后台服务的形式运行 redis-v :挂载宿主机目录redis redis-server /etc/redis/redis.conf:表示运行 redis 服务器程序,并且指定运行时的配置文件经过以上步骤,便可以通过 redis 客户端工具进行连接,如果连接不上,检查安全组和服务器防火墙端口是否开放安装 rabbitmq# 拉取带图形化管理界面的镜像 docker pull rabbitmq:3.7.7-management # 根据下载的镜像创建和启动容器 docker run -d --name rabbitmq3.7.7 -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq --hostname myRabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin df80af9ca0c9说明:-d:后台运行容器;--name:指定容器名;-p:指定服务运行的端口(5672:应用访问端口;15672:控制台 Web 端口号);-v:映射目录或文件;--hostname :主机名(RabbitMQ 的一个重要注意事项是它根据所谓的 “节点名称” 存储数据,默认为主机名);-e:指定环境变量;(RABBITMQ_DEFAULT_VHOST:默认虚拟机名;RABBITMQ_DEFAULT_USER:默认的用户名;RABBITMQ_DEFAULT_PASS:默认用户名的密码)Rabbitmq 访问地址:http://localhost:15672 至此,基本的运行环境都安装完毕,下面就是关键的打包步骤了。Vue 前端项目打包将 dist 下的所有文件目录拷贝到 SpringBoot 后端项目的 resources\static 目录下,static 目录需要新建。如果你的项目中用到了 shiro 或者 spring security 等安全框架,需要对静态资源放行。以上配置完成后,先在本地运行,再用 maven 进行打包。将 jar 包上传到服务器后,就要开始制作自己的镜像了,首先在与 jar 包同目录下新建 Dockerfile 文件。# 新建Dockerfile文件 touch Dockerfile # 编写Dockerfile文件 vim Dockerfile加入以下内容# Docker image for springboot file run # VERSION 0.0.1 FROM java:8 # VOLUME 指定了临时文件目录为/tmp。 # 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp VOLUME /tmp # 将jar包添加到容器中并更名为app.jar ADD demo-01.jar app.jar # 运行jar包 RUN bash -c 'touch /app.jar' ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]执行 docker build -t [镜像名称] . ,至此镜像文件就制作完成了。docker images查看镜像是否存在。最后一步,创建并启动容器,docker run --name [容器名称] -d -p 80:8080 [镜像名]。