搜索到
6
篇与
的结果
-
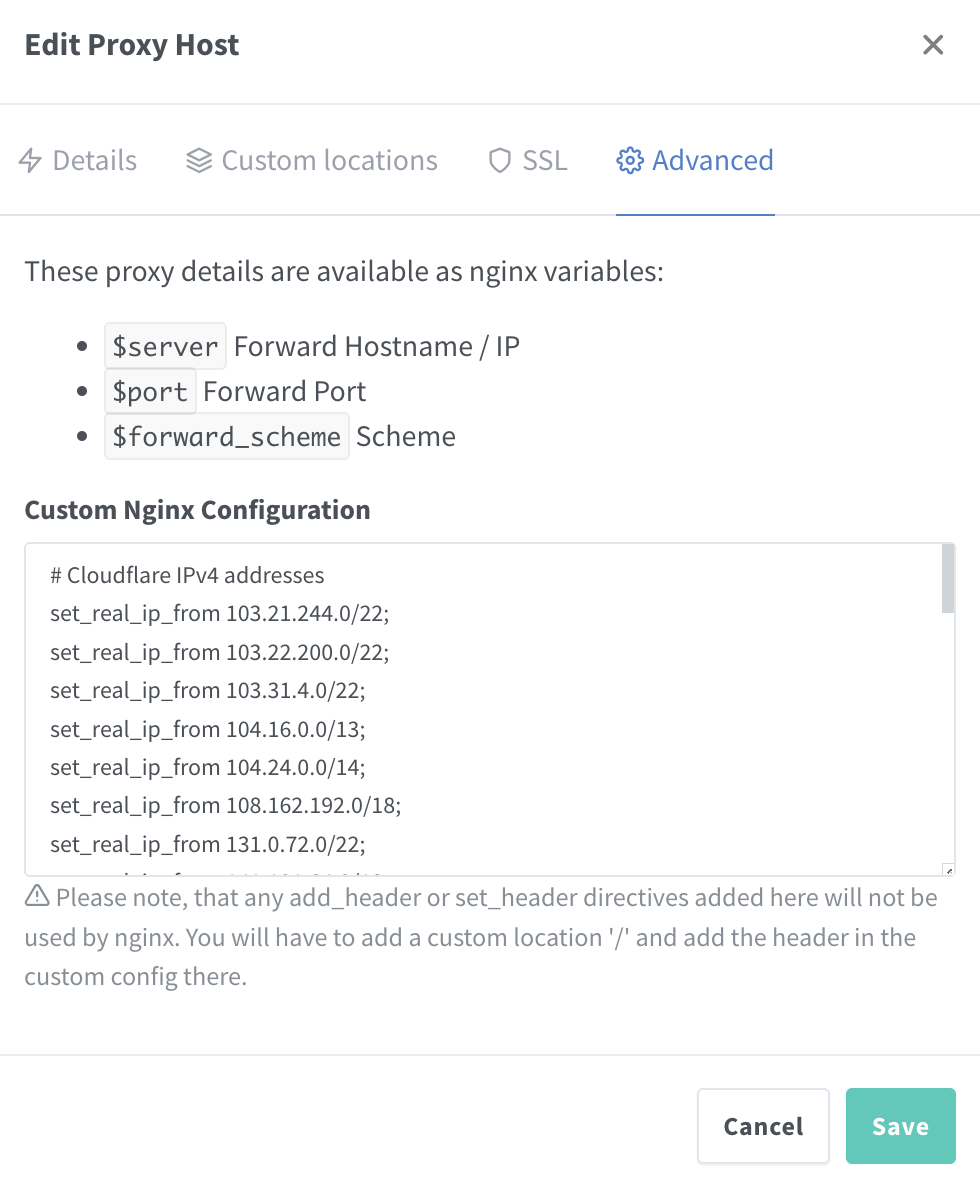
 Cloudflare橙色云启用后 Nginx Proxy Manager的IP白名单和黑名单配置指南 在使用Cloudflare的橙色云(即启用CDN功能)后,许多用户发现Nginx Proxy Manager中的Access Lists(IP地址白名单/黑名单)失效。这通常是因为Cloudflare的代理服务器屏蔽了真实的客户端IP地址,导致Nginx无法直接获取客户端的真实IP,而只能看到Cloudflare的IP地址。本文将介绍如何配置Nginx,以便它能够正确识别和使用Cloudflare传递的真实客户端IP地址,从而确保访问控制列表的正常工作。配置Cloudflare的真实IP头要解决这一问题,首先需要在Nginx中配置,以便它能够识别Cloudflare传递的真实客户端IP地址。Cloudflare通常通过CF-Connecting-IP或X-Forwarded-For头传递真实的客户端IP。以下是具体步骤:在Nginx配置文件中添加以下内容# Cloudflare IPv4 addresses set_real_ip_from 103.21.244.0/22; set_real_ip_from 103.22.200.0/22; set_real_ip_from 103.31.4.0/22; set_real_ip_from 104.16.0.0/13; set_real_ip_from 104.24.0.0/14; set_real_ip_from 108.162.192.0/18; set_real_ip_from 131.0.72.0/22; set_real_ip_from 141.101.64.0/18; set_real_ip_from 162.158.0.0/15; set_real_ip_from 172.64.0.0/13; set_real_ip_from 173.245.48.0/20; set_real_ip_from 188.114.96.0/20; set_real_ip_from 190.93.240.0/20; set_real_ip_from 197.234.240.0/22; set_real_ip_from 198.41.128.0/17; # Cloudflare IPv6 addresses set_real_ip_from 2400:cb00::/32; set_real_ip_from 2606:4700::/32; set_real_ip_from 2803:f800::/32; set_real_ip_from 2405:b500::/32; set_real_ip_from 2405:8100::/32; set_real_ip_from 2a06:98c0::/29; set_real_ip_from 2c0f:f248::/32; real_ip_header CF-Connecting-IP;CloudflareIP 范围 https://www.cloudflare.com/zh-tw/ips/这些IP段是Cloudflare的代理服务器IP地址,通过set_real_ip_from指令,Nginx将信任这些IP地址,并从CF-Connecting-IP头中获取真实的客户端IP。更新Nginx Proxy Manager配置确保Nginx Proxy Manager能够正确使用上述配置。如果Nginx Proxy Manager允许自定义Nginx配置片段,将上述配置片段添加到相应位置。调整访问控制列表确保你的访问控制列表(白名单/黑名单)中的IP地址策略基于真实的客户端IP,而不是Cloudflare的IP地址。实际使用场景访问控制公司A希望只允许公司内部IP地址访问其网站。他们启用了Cloudflare的CDN加速,但发现所有访问请求的IP地址都显示为Cloudflare的代理服务器IP,导致访问控制列表失效。通过上述配置,Nginx能够正确识别真实的客户端IP,从而确保只有公司内部IP地址能够访问网站。日志记录和分析公司B使用Nginx记录访问日志以进行流量分析和安全监控。在启用Cloudflare CDN后,访问日志中显示的IP地址都是Cloudflare的代理服务器IP。通过上述配置,Nginx能够记录真实的客户端IP,从而提供准确的流量分析和安全监控数据。防止DDoS攻击公司C遇到DDoS攻击,攻击流量通过Cloudflare的代理服务器进入,导致Nginx的防护措施失效。通过正确配置Nginx以识别真实的客户端IP,公司C可以更有效地应用防火墙规则,识别并阻止攻击IP,从而提升防护效果。结论通过正确配置 Nginx 以识别 Cloudflare 传递的真实客户端IP地址,可以解决因启用 Cloudflare CDN 功能导致的访问控制列表失效问题。这不仅能确保访问控制列表的正常工作,还能提升日志记录、流量分析和安全防护的准确性。希望本文对你配置 Nginx Proxy Manager 以支持 Cloudflare CDN 功能有所帮助。
Cloudflare橙色云启用后 Nginx Proxy Manager的IP白名单和黑名单配置指南 在使用Cloudflare的橙色云(即启用CDN功能)后,许多用户发现Nginx Proxy Manager中的Access Lists(IP地址白名单/黑名单)失效。这通常是因为Cloudflare的代理服务器屏蔽了真实的客户端IP地址,导致Nginx无法直接获取客户端的真实IP,而只能看到Cloudflare的IP地址。本文将介绍如何配置Nginx,以便它能够正确识别和使用Cloudflare传递的真实客户端IP地址,从而确保访问控制列表的正常工作。配置Cloudflare的真实IP头要解决这一问题,首先需要在Nginx中配置,以便它能够识别Cloudflare传递的真实客户端IP地址。Cloudflare通常通过CF-Connecting-IP或X-Forwarded-For头传递真实的客户端IP。以下是具体步骤:在Nginx配置文件中添加以下内容# Cloudflare IPv4 addresses set_real_ip_from 103.21.244.0/22; set_real_ip_from 103.22.200.0/22; set_real_ip_from 103.31.4.0/22; set_real_ip_from 104.16.0.0/13; set_real_ip_from 104.24.0.0/14; set_real_ip_from 108.162.192.0/18; set_real_ip_from 131.0.72.0/22; set_real_ip_from 141.101.64.0/18; set_real_ip_from 162.158.0.0/15; set_real_ip_from 172.64.0.0/13; set_real_ip_from 173.245.48.0/20; set_real_ip_from 188.114.96.0/20; set_real_ip_from 190.93.240.0/20; set_real_ip_from 197.234.240.0/22; set_real_ip_from 198.41.128.0/17; # Cloudflare IPv6 addresses set_real_ip_from 2400:cb00::/32; set_real_ip_from 2606:4700::/32; set_real_ip_from 2803:f800::/32; set_real_ip_from 2405:b500::/32; set_real_ip_from 2405:8100::/32; set_real_ip_from 2a06:98c0::/29; set_real_ip_from 2c0f:f248::/32; real_ip_header CF-Connecting-IP;CloudflareIP 范围 https://www.cloudflare.com/zh-tw/ips/这些IP段是Cloudflare的代理服务器IP地址,通过set_real_ip_from指令,Nginx将信任这些IP地址,并从CF-Connecting-IP头中获取真实的客户端IP。更新Nginx Proxy Manager配置确保Nginx Proxy Manager能够正确使用上述配置。如果Nginx Proxy Manager允许自定义Nginx配置片段,将上述配置片段添加到相应位置。调整访问控制列表确保你的访问控制列表(白名单/黑名单)中的IP地址策略基于真实的客户端IP,而不是Cloudflare的IP地址。实际使用场景访问控制公司A希望只允许公司内部IP地址访问其网站。他们启用了Cloudflare的CDN加速,但发现所有访问请求的IP地址都显示为Cloudflare的代理服务器IP,导致访问控制列表失效。通过上述配置,Nginx能够正确识别真实的客户端IP,从而确保只有公司内部IP地址能够访问网站。日志记录和分析公司B使用Nginx记录访问日志以进行流量分析和安全监控。在启用Cloudflare CDN后,访问日志中显示的IP地址都是Cloudflare的代理服务器IP。通过上述配置,Nginx能够记录真实的客户端IP,从而提供准确的流量分析和安全监控数据。防止DDoS攻击公司C遇到DDoS攻击,攻击流量通过Cloudflare的代理服务器进入,导致Nginx的防护措施失效。通过正确配置Nginx以识别真实的客户端IP,公司C可以更有效地应用防火墙规则,识别并阻止攻击IP,从而提升防护效果。结论通过正确配置 Nginx 以识别 Cloudflare 传递的真实客户端IP地址,可以解决因启用 Cloudflare CDN 功能导致的访问控制列表失效问题。这不仅能确保访问控制列表的正常工作,还能提升日志记录、流量分析和安全防护的准确性。希望本文对你配置 Nginx Proxy Manager 以支持 Cloudflare CDN 功能有所帮助。 -
200 行 Rust 代码实现简单 CF Workers AI Bot | Rust 学习日记 本文由 High Ping Network 的小伙伴 GenshinMinecraft 进行编撰前言这次主要是用 Rust 重写了之前用 Python3 写的 Cloudflare Workers AI Telegram 机器人一边看着 《Rust 圣经》 一边 Coding,还是挺好玩的当然,因为我是 Rust 新手,所以代码中有问题的地方还请多多包涵请注意,本文会一步步讲解这一 Bot 的实现过程,也算是我学习 Rust 的一个阶段性总结如果你不想看实现过程,请直接翻到本文末尾开干!如何开启一个项目? 那当然是: 新建文件夹!环境环境配置请看 Rust 官方文档 新建文件夹并在终端输入以下命令来初始化一个项目:cargo new [文件夹名字]去 Telegram 申请一个新的 Bot ,保存 Bot Token 以留作备用 (这么简单懒得说了)然后前往这里来创建 Workers AI API 令牌 和 帐户 ID ,也是复制保存备用配置依赖在项目根目录下有个 Cargo.toml ,里面是有关项目信息的内容,在最底下添加如下内容:[dependencies] reqwest = { version = "0.12.4", features = ["json","blocking"] } serde_json = "1.0" teloxide = { version = "0.12", features = ["macros"] } tokio = { version = "1.38.0", features = ["rt-multi-thread", "macros"] } log = "0.4.21" simple_logger = "5.0.0"这里表示了项目需要用到这堆东西,如果之前有用过 Python ,那这玩意就可以理解为 requirements.txt然后删除 src/main.rs 中所有内容,并在开头引用这些库:use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; 这样就算引用完成了!PS: 你可能还需要去终端来安装一下依赖:cargo add reqwest serde_json teloxide log simple_logger常量定义// 初始化全局常量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = "";API_KEY: Workers AI API 令牌USER_ID: 帐户 IDPROMPT: AI 提示词MODEL: 对话使用的大模型,默认是阿里云的通义千问,可以在这里查看支持的模型,更改即可,非必要无需更改TELEGRAM_BOTTOKEN: Telegram Bot Token按照要求将 Workers AI API 令牌 和 帐户 ID 还有 Telegram Bot Token 放入对应的位置中,以便于下面调用如果有需要,也可以根据文档来修改 MODEL 模型和 PROMPT 提示词编写 GPT 请求函数先不着急编写 Bot 主体部分,来看下有关网络请求的调用函数定义// GPT 对话函数,用于请求 API 并返回async fn gpt(question: &str) -> Result<String, String> {}简单介绍一下:这句定义了一个名为 gpt 的异步函数,question 是参数返回值是 String 但是不确定是返回正常结果还是错误信息,这种做法有助于错误处理构建 Headers玩过大模型 API 的都知道,鉴权 (也就是 API_Tokens 这类东西) 一般是放在 Headers 里面的,所以我们要来构建 Headers而 Workers AI 的 API Headers 格式类似这样:Authorization: Bearer {API_TOKEN}于是,就有了下面的代码:// 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), );这里定义了一个变量 headers ,并用 insert 插入两条键值对其中 Authorization 用于存放 API_KEY ,用到了 format!() 宏格式化它的值,运用到了最开始定义的 API_KEY 常量Content-Type 则是表明了发送的数据格式,用于指示资源的MIME类型.parse() : 将字符串转化为 HeaderValue 类型,这是 reqwest 库用来存储 Headers 的类型.unwrap() : 直接获取结果而不进行错误处理 (有错误就退出,不过这段代码没有必要进行错误处理)构建请求体接下来是请求体:let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); 简单易懂,调用 `PROMPT` 和函数参数中的 `question` 即可,简单的 Json [发送请求] 终于可以发送请求了,首先,来初始化一个 HTTP Client: '''rust let client = reqwest::Client::new();随后就可以发送请求了:let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?;这里声明了一个 api 变量,用于存储获取到的数据client.post(): 则是发送 Post 请求的主要语句,URL 中的 Workers AI API 令牌 和 模型 还是一样使用 format!() 来构建headers(headers): 传递 Headers.json(&data): 将 data 转换为 Json 作为请求体.send().await: 这一步就相当于发送请求了,并等待异步操作完成.map_err(|_| "请求出现问题".to_string())?: 错误处理,如果发生问题则直接返回 请求出现问题 而不继续执行,如果出现错误则直接赋值给变量 api.text().await: 将收到的数据转换为文本信息,并等待异步操作完成.map_err(|_| "解析响应体时出错".to_string())?: 作用和上面那个差不多这样就算发送完一个请求并把接收到的信息赋值给 api 了解析 Json经过上面的请求,api 应该是一个 Json 格式的字符串,我们需要在里面提取出需要的答案Json 大概长这样:{ "result": {"response": "我是来自阿里云的超大规模语言模型,我叫通义千问。"}, "success": true, "errors": [], "messages": []}let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string())第一行代码尝试将变量 api 中存储的字符串解析为 JSON 格式,同样的 .map_err() 就不再解释了第一次从 Json 中获取信息返回的是 Option<&Value> 即可能有或可能没有,所以我们使用 .ok_or() 来判断有或无,当有时则直接赋值,没有则返回错误第二次从 Json 中获取信息也一样,不多赘述最后,返回 result 即可编写主程序呼呼,终于等待编写主程序了,不过主要的信息处理程序并不在 main 函数中,main 函数在代码中只起到一个引导的作用async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; }首先定义一个 main 异步函数,这是主程序的入口初始化一个 Log 记录器,这里使用了 simple_logger 库,该库无需繁琐地配置 Log 信息即可做到美观的输出,定义 Log Level 为 Debuginfo!() 宏是用来记录 Log 的,相同的,还有 debug!() warn!() error!() 等,分别记录不同等级的日志,下面不再赘述let bot = Bot::new(TELEGRAM_BOTTOKEN): 定义了一个名为 bot 的 Bot Client,它可以接收消息、发送消息等teloxide::repl:异步函数,可以启动一个 REPL 循环 (简要理解成可以处理新信息的循环即可),传入 Bot 并接受名为 msg 的信息提供给下面的代码。下面的代码即为消息处理程序msg.chat.is_private(): 返回一个布尔值,是否为私聊信息if msg.chat.is_private() {} else {}: 消息处理程序分成了两个部分,即判断是否为私聊 Bot,如果是则执行上半部分代码,否则执行下半部分msg.text(): 返回一个字符串,消息的文本内容因为 msg.text() 的类型为 Option<&str>,即可能有或没有 (没有文本信息的话可能为图片、文件、贴纸等),所以需要使用 match 做判断,如果有文本信息则将 bot 和 msg 传入 matchmsgprivate 或者 matchmsgpublic 函数中 (之后会定义这两个函数)当没有文本消息时候,则 Log Debug 输出总的来说,main 函数主要就是接受信息并交给其他函数处理 (尽管是小项目我个人还是建议不要全堆在 main 函数里面)处理私聊信息私聊信息需要做到:/start 发送帮助信息当直接对话 (不是 / 命令时),直接返回结果/ai 问题 返回问题的结果主要思路是判断消息是否为 / 开头,如果不是则直接返回 GPT 回答,如果是再进行指令判断async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } }先定义一个 text 用于储存文本信息,便于调用 (因为在主函数调用该函数时候已经做过检测,所以这里使用 .unwrap() 并无不妥)随后进行 / 开头命令检测,为否直接调用 replyai 函数 (等会定义),传入 msg, bot, msg.text() (不想处理借用问题,msg 用 .clone() 就好)如果为是,则使用 .splitn() 分割命令,command 为指令部分 (如 /start),argument 为参数部分 (可能没有,所以用 Option<&str>)如果命令开头为 /ai,则传入 replyai 函数;如果开头为 /start,则传入 replystart 函数 (等会定义)如果都不是机器人的指令,则不做处理,输出 Debug 信息处理群组信息这一部分和处理私聊信息差不多,区别只是非指令消息不回复async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }同样的逻辑,只是检测为非指令仅输出 Debug 消息而已AI 回复这里要实现一个函数需要传入 msg、bot、text 信息,调用 gpt 函数并发送回 Telegramasync fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; }定义异步函数不再赘述,需要注意 optiontext: Option<&str> 需要传入的是 Option<&str>,对应着消息处理函数的 argument既然 optiontext 为可能有可能没有的,那就先来检测一下。使用 match,当有值时赋值给 text;无值时输出 warn 信息并回复给用户,提示请查看 /start 指令,并退出检测成功后,调用 gpt 函数,也是使用 match。如果正常则赋值给 answer,有错误则输出 error 信息输出几条 info 信息,随后就可以将结果发送回 Telegram 了 (GPT 返回内容多使用 Markdown 格式,所以这里指定使用 MarkdownV2 格式发送)就这么简单,主要的代码还是错误处理,不然没有必要写这么多Start 回复最最最最简单的一部分,传入 bot 和 msg 即可async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; }定义一个字符串,作为帮助信息info 输出基本信息发送帮助信息完整代码 use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; // 初始化全局变量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = ""; // GPT 对话函数,用于请求 API 并返回 async fn gpt(question: &str) -> Result<String, String> { // 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), ); // 初始化问题 let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); // 初始化 Client let client = reqwest::Client::new(); // 请求 CF API let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?; // 解析 Json let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string()) } // 主函数 #[tokio::main] async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; } // GPT 回复函数 async fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; } // start 回复函数 async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; } // 私聊检测 async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } } // 非私聊 async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }保存后 执行下面指令即可编译运行:cargo build --release ./target/release/RUST总结这次主要是了解了 Rust 的基本语法,更深层次的还尚未触及到,对于代码中解释有误或代码有问题的请多多谅解
-
优选 Cloudflare 官方 / 中转 IP Cloudflare 官方的 IP 很好理解,就是各个边缘节点的 IP。哪怕在全球大部分地方使用了 Anycast 技术, 但不同 IP 在中国大陆的访问体验还是有很大差别。小站收集了很多使用官方 IP 的网站,我们可以通过 DNS 记录查询的方式得到这些 IP,并通过本地测速或者拨测的方式进行筛选。#来源:https://blog.misaka.rest/2023/08/12/pick-cf-best-domain/ #引用时删去部分无效域名 time.cloudflare.com shopify.com time.is icook.hk icook.tw ip.sb japan.com malaysia.com russia.com singapore.com skk.moe www.visa.com www.visa.com.sg www.visa.com.hk www.visa.com.tw www.visa.co.jp www.visakorea.com www.gco.gov.qa www.gov.se www.gov.ua www.digitalocean.com www.csgo.com www.shopify.com www.whoer.net www.whatismyip.com www.ipget.net www.hugedomains.com www.udacity.com www.4chan.org www.okcupid.com www.glassdoor.com www.udemy.com www.baipiao.eu.org alejandracaiccedo.com log.bpminecraft.com www.boba88slot.com gur.gov.ua www.zsu.gov.ua www.iakeys.com edtunnel-dgp.pages.dev www.d-555.com fbi.gov www.sean-now.com download.yunzhongzhuan.com whatismyipaddress.com www.ipaddress.my www.pcmag.com www.ipchicken.com www.iplocation.net iplocation.io www.who.int www.wto.org #其他选择,都是官方 IP 优选 jp.byun.eu.org un.goasa.top emby2.misakaf.org也有大佬做好了一个优选的结果,可以根据需要即取即用:https://stock.hostmonit.com/CloudFlareYes至于中转 IP,其实就是第二层「反向代理」,通过反代 Cloudflare 边缘节点提供服务。中转 IP 大都是个人自用,获取它们的方法大都是大批量的端口扫描,具体细节这里就不再展开了。也是因此,中转 IP 存活的时间都十分短暂,对于网站加速来说,除非自己拿服务器搭建反向代理,否则几乎没有使用价值。使用方法在域名解析里设置国内运营商线路 CNAME解析 到各个优选地址。
-
Cloudflare WARP 教程:给 VPS 额外添加“原生” IPv4/IPv6 双栈网络出口 前言Cloudflare WARP (简称 WARP) 是 Cloudflare 提供的一项基于 WireGuard 的网络流量安全及加速服务,能够让你通过连接到 Cloudflare 的边缘节点实现隐私保护及链路优化。早年有很多小伙伴拿来当梯子工具来直接使用,应该很熟悉了。不过由于 WireGuard 数据传输使用的 UDP 协议,中国大陆的网络运营商会对其进行 QoS ,加上很多节点的 IP 被封锁,现在可以说几乎处于不可用的状态了。而对于自由网络的地区来说则没有这些限制,加上有开发者制作的开源工具可以生成通用的 WireGuard 配置文件,这使得我们可以在安装了某科学的上网工具的国外 VPS 上部署它,并实现一些骚操作。本篇是相关知识科普和纯手动部署教程,小伙伴们可边学习边折腾。如果想直接部署可以使用本站全网独家首发的 Cloudflare WARP 一键安装脚本 。WARP 的使用场景和局限性使用场景:WARP 网络出入口均为双栈 (IPv4+IPv6),因此单栈 VPS 云服务器可以连接到 WARP 网络来获取额外的网络连通性支持:IPv6 Only VPS 可获得 IPv4 网络的访问能力,不再局限于 NAT64/DNS64 的束缚,能自定义任意 DNS 解析服务器,这对使用某科学的上网工具有奇效。IPv4 Only VPS 可获得 IPv6 网络的访问能力,比如可作为 IPv6 Only VPS 的 SSH 跳板。WARP 的 IPv6 网络的质量比 HE IPv6 Tunnel Broker 及 VPS 自带的都要好,很少绕路,可作为本机 IPv6 网络的替代。WARP 对外访问网络的出口 IP 被很多网站视为真实用户,获得原生 IP 或私人家庭住宅 IP 的效果,可以解除某些网站基于 IP 的封锁限制:解锁 Netflix 非自制剧 (几乎失效,原因详见《为什么 WARP 解锁 Netflix 失效了?》)解决 Google 搜索流量异常频繁跳出人机身份验证的问题解决无法打开 Google Scholar (谷歌学术) 403 访问限制的问题解决 Google 的 IP 定位漂移到中国(送中),无法使用 YouTube Premium 的问题解锁 ChatGPT 访问限制(Access denied/1020)的问题 (仅限已开放服务的地区)。注意:实际使用不稳定,且有封号的风险。建议使用可安全访问并解锁 ChatGPT 的 VPS。局限性:WARP 是以 NAT 的方式去访问外部网络,网络出口 IP 由 Cloudflare 根据地区随机分配且为多人共用,只能用于对外网络访问,不能从外部访问 VPS 。可以理解为连上了由 Cloudflare 提供的大内网。TIPS: 如果是需要可从外部访问 VPS 的公网 IPv6 地址可使用 HE IPv6 Tunnel Broker 解决,而 IPv4 地址只能加钱找商家买。滥用严重。WARP 一直有着各种滥用和不规范使用的情况,比如注册僵尸账号、暴力发包网络攻击,随着时间的推移已经被很多 IP 评级机构列为不可信状态,大量 IP 段已经被拉黑。未来解除 IP 封锁限制的作用会越来越少,反而越来越多的网站对其设访问限制。IP 万人骑。WARP 多人共用一个网络出口 IP 是相当大的量级,在热门地区几万甚至十几万人共用一个 IP 都是有可能的。很多网站会设单 IP 访问频率限制来阻止网络攻击、防止资源滥用。所以使用 WARP 访问有严格限制的网站被屏蔽、无法注册、甚至封号未来可能会是常态。随着使用人数的增加减速效果越来越明显,尤其在网络高峰时段,热门地区甚至到了几乎不可用的状态。WARP 设置教程安装 WireGuard既然 WARP 基于 WireGuard ,那么我们首先就需要安装 WireGuard 。使用一键脚本来安装:bash <(curl -fsSL git.io/warp.sh) wg使用 wgcf 生成 WireGuard 配置文件ViRb3/wgcf 是 Cloudflare WARP 的 非官方 CLI 工具 ,它可以模拟 WARP 客户端注册账号,并生成通用的 WireGuard 配置文件。安装 wgcfcurl -fsSL git.io/wgcf.sh | sudo bash注册 WARP 账户 (将生成 wgcf-account.toml 文件保存账户信息)wgcf register生成 WireGuard 配置文件 (wgcf-profile.conf)wgcf generate生成的两个文件记得备份好,尤其是 wgcf-profile.conf ,万一未来工具失效、重装系统后可能还用得着。编辑 WireGuard 配置文件将配置文件中的节点域名 engage.cloudflareclient.com 解析成 IP。不过一般都是以下两个结果:162.159.192.1 2606:4700:d0::a29f:c001这样做是因为后面的操作要根据 VPS 所配备的网络协议的不同去选择要连接 WARP 的节点是 IPv4 或 IPv6 协议。IPv4 Only 服务器添加 WARP IPv6 网络支持将配置文件中的 engage.cloudflareclient.com 替换为 162.159.192.1 ,并删除 AllowedIPs = 0.0.0.0/0 。即配置文件中 [Peer] 部分为:[Peer] PublicKey = bmXOC+F1FxEMF9dyiK2H5/1SUtzH0JuVo51h2wPfgyo= AllowedIPs = ::/0 Endpoint = 162.159.192.1:2408原理:AllowedIPs = ::/0 参数使得 IPv6 的流量均被 WireGuard 接管,让 IPv6 的流量通过 WARP IPv4 节点以 NAT 的方式访问外部 IPv6 网络。此外配置文件中默认的 DNS 是 1.1.1.1,博主实测其延迟虽然很低,但因为缺少了 ECS 功能所以解析结果并不理想。由于它将替换掉系统中的 DNS 设置 (/etc/resolv.conf),建议小伙伴们请根据实际情况来进行替换,或者直接删除 DNS 这行。以下配置供参考:DNS = 8.8.8.8,8.8.4.4,2001:4860:4860::8888,2001:4860:4860::8844IPv6 Only 服务器添加 WARP IPv4 网络支持将配置文件中的 engage.cloudflareclient.com 替换为 [2606:4700:d0::a29f:c001] ,并删除 AllowedIPs = ::/0 。即配置文件中 [Peer] 部分为:[Peer] PublicKey = bmXOC+F1FxEMF9dyiK2H5/1SUtzH0JuVo51h2wPfgyo= AllowedIPs = 0.0.0.0/0 Endpoint = [2606:4700:d0::a29f:c001]:2408原理:AllowedIPs = 0.0.0.0/0 参数使得 IPv4 的流量均被 WireGuard 接管,让 IPv4 的流量通过 WARP IPv6 节点以 NAT 的方式访问外部 IPv4 网络。此外配置文件中默认的 DNS 是 1.1.1.1,由于是 IPv4 地址,故查询请求会经由 WARP 节点发出。由于它将替换掉系统中的 DNS 设置 (/etc/resolv.conf),为了防止当节点发生故障时 DNS 请求无法发出,建议替换为 IPv6 地址的 DNS 优先,或者直接删除 DNS 这行。以下配置供参考:DNS = 2001:4860:4860::8888,2001:4860:4860::8844,8.8.8.8,8.8.4.4WARP 双栈全局网络置换WARP 双栈全局网络是指 IPv4 和 IPv6 都通过 WARP 网络的出口对外进行网络访问,实际上默认生成的 WireGuard 配置文件就是这个效果。不过默认的配置文件没有外部对本机 IP 访问的相关路由规则,一旦直接使用 VPS 就会直接失联,所以我们还需要对配置文件进行修改。路由规则需要添加在配置文件的 [Interface] 和 [Peer] 之间的位置,以下是路由规则示例:[Interface] ... PostUp = ip -4 rule add from <替换IPv4地址> lookup main PostDown = ip -4 rule delete from <替换IPv4地址> lookup main PostUp = ip -6 rule add from <替换IPv6地址> lookup main PostDown = ip -6 rule delete from <替换IPv6地址> lookup main [Peer] ...TIPS: 包含<>(尖括号)的部分一起替换掉,这只是为了看起来明显。替换配置中的 IP 地址部分为 VPS 的公网 IP 地址,如果 IDC 提供的是 VPC 内网方案则需要替换为内网 IP 。像 AWS 、Azure 、Google Cloud 、Oracle Cloud 等大厂都是 VPC 内网方案,内网地址一般会在网页面板有提供。如果不确定是哪种网络方案,输入 ip a | grep <公网IP地址> 看是否有显示,没有那么就说明是 VPC 内网方案。启用 WireGuard 网络接口将 WireGuard 配置文件复制到 /etc/wireguard/ 并命名为 wgcf.conf 。sudo cp wgcf-profile.conf /etc/wireguard/wgcf.conf开启网络接口(命令中的 wgcf 对应的是配置文件 wgcf.conf 的文件名前缀)。sudo wg-quick up wgcf执行执行 ip a 命令,此时能看到名为 wgcf 的网络接口,类似于下面这张图:执行以下命令检查是否连通。同时也能看到正在使用的是 Cloudflare 的网络。# IPv4 Only VPS curl -6 ip.p3terx.com # IPv6 Only VPS curl -4 ip.p3terx.com测试完成后关闭相关接口,因为这样配置只是临时性的。sudo wg-quick down wgcf正式启用 WireGuard 网络接口# 启用守护进程 sudo systemctl start wg-quick@wgcf # 设置开机启动 sudo systemctl enable wg-quick@wgcf其它操作和说明DNS 优化和 IPv4/IPv6 优先级设置TIPS: 以下设置仅针对操作系统 DNS ,代理软件应单独设置内置的 DNS 和 IP 分流策略,具体参考相关软件文档中的 DNS 和路由部分。原因参见《优先级设置在特殊场景中的局限性》章节。当访问的网站是双栈且服务器也是双栈,默认情况下 IPv6 优先级高于 IPv4,应用程序优先使用 IPv6 地址。理论上应该是如下情况:IPv4 Only 服务器优先通过新增的 WARP IPv6 网络去访问外部网络。IPv6 Only 服务器优先通过原来的 IPv6 网络去访问外部网络。然而 WARP 的情况有点特殊,可能与 WireGuard 的路由规则有关,所以现实的情况可能是:IPv4 Only 服务器优先通过原来的 IPv4 网络去访问外部网络。IPv6 Only 服务器优先通过原来的 IPv6 网络去访问外部网络。如果你对于这个设定不满意,可以根据实际的需求手动去设置 IPv4 与 IPv6 的优先级。设置 IPv4 优先编辑 /etc/gai.conf 文件,在末尾添加下面这行配置:precedence ::ffff:0:0/96 100一键添加命令如下:# IPv4 优先 grep -qE '^[ ]*precedence[ ]*::ffff:0:0/96[ ]*100' /etc/gai.conf || echo 'precedence ::ffff:0:0/96 100' | sudo tee -a /etc/gai.conf设置 IPv6 优先编辑 /etc/gai.conf 文件,在末尾添加下面这行配置:label 2002::/16 2一键添加命令如下:# IPv6 优先 grep -qE '^[ ]*label[ ]*2002::/16[ ]*2' /etc/gai.conf || echo 'label 2002::/16 2' | sudo tee -a /etc/gai.confCloudflare WARP 网速测试使用 speedtest.net 提供的 CLI 工具测试通过 WARP 访问外部网络的极限网速。安装 Speedtest CLIcurl -fsSL git.io/speedtest-cli.sh | sudo bash执行 speedtest 命令测速。博主随便拿了一个吃灰的 LXC 小鸡进行测试,发现即使用的是 wireguard-go 其网速依然很猛,几轮测试下来速度都在 500M 上下。可以预见的是这个速度应该远未达到 WARP 的极限,不过随着这篇教程的发布,之后是否还是这么理想就不得而知了。写在最后Cloudflare 一直以来为广大人民群众免费提供优秀的网络服务,希望大家善待它,不要肆意滥用。
-
利用CloudFlare+Gmail实现自有域名临时邮箱服务,无需服务器即可拥有无限个邮箱 前言之前本博客有介绍过几种搭建自有域名的邮局功能,但是现在免费提供服务的QQ邮箱的域名邮箱,阿里云的企业邮箱都不免费了,也介绍过forsaken-mail自搭建的方式,但要求有服务器和服务商要开放25端口,门槛还是有点高,今天介绍一种人人都能玩的方法。这个方法,一来不需要部署服务器,二来比临时邮箱更多了永久能接收邮件;综合来看,这种方式实现域名邮箱,比部署forsaken-mail更优方案,只要一个域名就能拥有无限个邮箱,非常适合自己需要多邮箱地址的应用场景。比如无限注册ChatGPT。原理主要利用的是 CloudFlare 域名提供的电子邮件路由功能,配合 Gmail 实现收发,从面达到无限账号的域名邮局服务,可以当成临时邮箱使用。要求CloudFlare有一域名Gmail邮箱过程主要分两个过程,一个 接收 ,一个 发送 。接收第一步,在CloudFlare上进入对应的域名点击电子邮件——电子邮件路由——开始使用 添加自定义地址和目标位置——创建并继续,要多少自己创建多少第二步,验证邮箱登录你的谷歌邮箱,会有一封验证邮件,证明你目标邮箱是你自己的 点击 Verify email address ,完成验证第三步,添加DNS记录回到 CloudFlare 后台可以看到已经准备好了,我们只要点击 “添加记录并启用” ,就能自动完成 DNS 记录的操作了可以看到我的一个域名邮箱已经完成了,你需要多少账号,就在 自定义地址 添加便可,会统一转发到 目标地址 ,即是可以 N对1 。第四步,测试可以成功接收到邮件。 至此:域名邮箱的接收功能已完成发送如果你只是接收邮件,这一步可以不需要理会了,如果你也有发送邮件的需求,那接着下接的步骤。利用的是 Gmail SMTP Server ,提示免费的发送电子邮件服务,不限制域名,每天可使用 500封 发送Email服务第一步,添加其他电子邮件地址设置——账号和导入——添加其他电子邮件地址 名称:就是你发邮件给别人显示的名称 电子邮件地址:就是你希望对方接收到你邮件时显示的地址,我使用上面的sosel@corlalcloud.link第二步,设置STMPSMTP服务器:smtp.gmail.com 用户名:你谷歌邮箱地址 密码:你谷歌密码(应用专用密码) TLS:是 我这里不成功,以下错误提示 身份验证失败。请检查您的用户名/密码。 服务器返回错误: "535-5.7.8 Username and Password not accepted. Learn more at 535 5.7.8 https://support.google.com/mail/?p=BadCredentials em9-20020a17090b014900b002612150d958sm9709788pjb.16 - gsmtp , code: 535"解决办法 添加两步认证,使用专用密码登录 生成专用密码 设置——账号和导入——更改账号设置——“更改密码”为专用密码第三步,验证邮箱地址验证邮件 ,这时候由于我们接收那一步已经设置了邮件转了到Gmail.所以直接在Gmail收件箱就能查看到sosel@coralcloud.link的验证邮件或者验证码。第四步,测试测试域名邮箱地址发送 发送时候选择域名邮箱作为发件人,接收端显示也是域名邮箱的地址 至此:发件人也用上了域名邮箱地址了
-
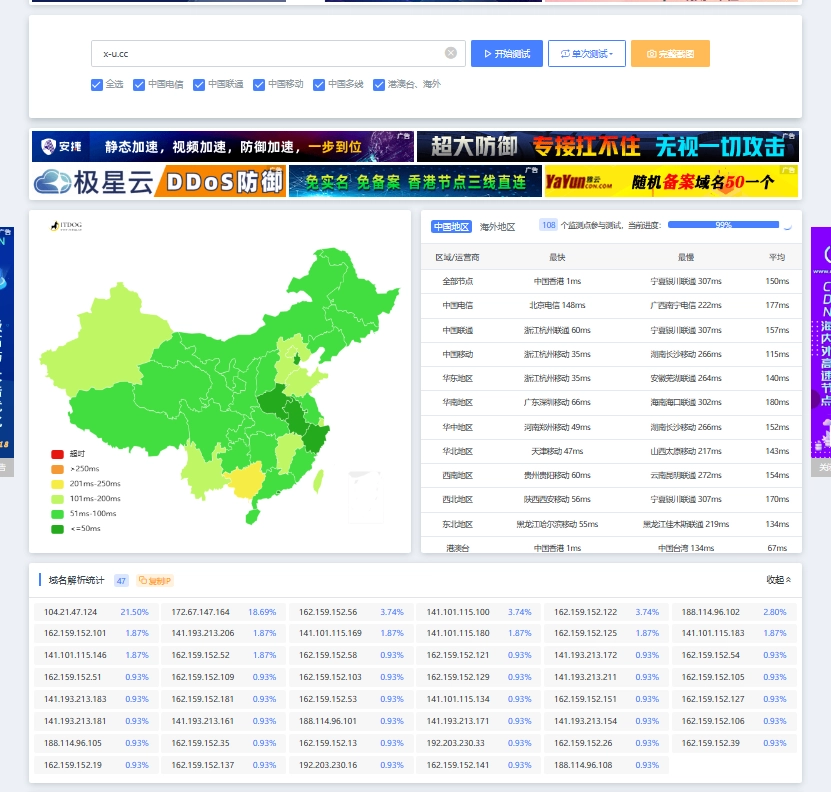
Cloudflare加速解析服务-优化大陆访问速度 前言Cloudfalre 加速解析是由 心有网络 向中国大陆用户提供的公共优化服务接入服务节点: cf.13d7s.site接入使用方式类似于其它CDN的CNAME接入,可以为中国大陆用户访问Cloudflare网络节点大幅度加速,累计加速节点60+,其中移动网络为最快,联通最慢。开始前的温馨提示(看一下)1、教程使用阿里云域名演示2、教程过程会cloudflare和阿里云来回切换,所以大家不要以为我教程过程中切换页面之前的页面就把之前的页面关闭了3、教程是在别的地方看见的,原文说的比较简单,我这里会很详细。4、域名商要支持分区解析(大概意思就是能选路,国内网络怎么访问,国外网络怎么访问),推荐阿里云Aliyun、腾讯云DNSpod,如果你的域名不是这两家,末尾我会演示一下在其他地方的域名使用他们的域名解析的5、本教程十分详细,不用担心自己是小白就看不懂(基本是一个教程一个图那种)教程登陆 cloudflare(官网有点卡,耐心等一下,有能力可以挂梯子):https://dash.cloudflare.com/ 有账号我们直接登录,没有账号我们直接注册一个登录。(这里如果我们是第一次弄的话邮箱地址一定要写清楚,后面验证域名的时候会给我们发邮件)登录之后我们添加我们的网站。我这里网站是x-u.cc一进来就会让我们选择服务,这里我们有钱的话可以去买,不想花钱的话我们直接往下面翻,我这里选择白嫖服务这里的话是提示我们域名之前的解析记录,看一下没有问题的话就继续了。(这里如果我们没有解析记录话我们添加一下,然后继续)(记住这里一定要选代理,不代理的话他不会给我们套CDN)然后这里有一大推东西(大概意思就是我们把DNS服务器改成他的),我们不用管,往下找到第四步。这里是我们要修改dns服务器的值我们现在终于可以去打开我们的阿里云了,多开一个页面,登录阿里云:阿里云-计算,为了无法计算的价值 (aliyun.com)登录阿里云之后,我们点击控制台,找到域名:这里我们点x-u.cc,不要去点解析然后进入这个页面,点击修改dns服务器然后修改我们的DNS服务器,这里我其实已经修改好了,但是为了照顾小白,我这里还是再弄一下。这里可以填写两个dns服务,我们直接把之前的cloudflare页面的dns服务值复制过来然后我们DNS就修改好了阿里云这边改好了之后我们切回我们的cloudflare点击下一步了。这里我们选稍后完成进入到这里之后我们等一哈,cloudflare会给我们一个成功的邮件(基本十几秒就到了)。邮箱一到,表示我们已经成功了现在我们去使用itdog测试一下:https://itdog.cn/这里大家其实只会有几个ip,也没有我这么绿,这是因为我之前已经弄好了导致的。好的,目前为止我们已经完成3/2的进度了,马上就可以和我一样快了(滑稽)现在我们切回我们之前阿里云的dns页面,继续修改我们的dns服务器添加dns服务器到能填写4个地址然后我们这里前面两个写上我们阿里云的地址:dns1.hichina.comdns2.hichina.com然后3和4我们写上cloudflare的地址这里我们可以直接复制粘贴到3和4的输入框中:这里会发现我第三个框是红色的,然后确定也是灰色的,这里说明我们第三个框有点问题(一般都是前面有多的空格或者后面有多的空格)我们把多余的空格删除就行了接下来我们点击域名解析:这里我们添加解析:注意:国内(我们需要添加三条解析(中国移动、中国电信、中国联通))我们CNAME解析值是:cf.13d7s.site境外我们CNAME解析值是:你的域名+.cdn.cloudflare.net(比如我是@解析,那我的解析值就是x-u.cc,我的域名值就是x-u.cc.cdn.cloudflare.net,如果我是www解析,那我域名值就是www.x-u.cc.cdn.cloudflare.net)好的,我们现在就已经完成了我们所有过程,我们现在打开itdog看看是否有变化。https://itdog.cn/