搜索到
18
篇与
的结果
-
 Linux环境下卸载Oracle数据库并重新安装的详细指南 引言在 Linux 环境下管理和维护 Oracle 数据库是许多系统管理员和数据库管理员的日常工作之一。无论是出于升级、迁移还是解决故障的需要,卸载和重新安装 Oracle数据库 都是一项重要的技能。本文将为您提供一份详尽的指南,帮助您在 Linux 环境下彻底卸载 Oracle数据库,并重新安装。一、准备工作在开始卸载之前,确保您已经备份了所有重要的数据文件和配置信息,以防万一。同时,确保您具有足够的权限(通常是root用户)来执行以下操作。二、停止Oracle服务停止数据库实例使用 SQL Plus 停止数据库实例sqlplus /nolog SQL> connect / as sysdba SQL> shutdown immediate SQL> exit停止Listener服务使用 lsnrctl 命令停止Listenerlsnrctl stop停止HTTP服务如果您的环境中启用了HTTP服务,停止它:service httpd stop三、卸载Oracle软件切换到root用户如果您当前不是 root 用户,请切换到 rootsu - root删除Oracle安装目录删除 Oracle 的安装目录,通常是/u01/app/oraclerm -rf /u01/app/oracle删除相关文件和目录删除与Oracle相关的文件和目录rm /usr/local/bin/dbhome rm /usr/local/bin/oraenv rm /usr/local/bin/coraenv rm /etc/oratab rm /etc/oraInst.loc删除Oracle用户和用户组删除 Oracle 用户和相关的用户组userdel -r oracle groupdel oinstall groupdel dba groupdel oper删除启动服务删除与 Oracle 相关的启动服务chkconfig --del dbora四、清理环境变量编辑 /etc/profile 或 ~/.bash_profile 文件,删除与 Oracle 相关的环境变量设置。五、重新安装Oracle数据库前置条件确保系统满足Oracle的安装要求,如磁盘空间、内存等。安装并配置好Java环境。下载Oracle数据库安装包。创建Oracle用户和用户组groupadd oinstall groupadd dba useradd -g oinstall -G dba oracle设置环境变量编辑 ~/.bash_profile 文件,添加以下内容export ORACLE_BASE=/u01/app/oracle export ORACLE_HOME=$ORACLE_BASE/product/19.0.0/dbhome_1 export ORACLE_SID=ORCL export PATH=$ORACLE_HOME/bin:$PATH安装Oracle数据库解压安装包并运行安装脚本unzip linuxx64_19c_database.zip cd database ./runInstaller按照安装向导的提示完成安装。配置数据库安装完成后,运行 root.sh 脚本/u01/app/oracle/product/19.0.0/dbhome_1/root.sh初始化数据库dbca -silent -createDatabase -templateName General_Purpose.dbc -gdbname ORCL -sid ORCL -responseFile NO_VALUE -characterSet AL32UTF8 -memoryPercentage 40 -emConfiguration LOCAL -pdbName PDBORCL -sysPassword syspassword -systemPassword systempassword六、验证安装启动数据库sqlplus /nolog SQL> connect / as sysdba SQL> startup检查数据库状态SQL> select status from v$instance;七、常见问题及解决方案libaio问题如果在启动数据库时遇到 libaio 相关的错误,安装或重新安装 libaio 库yum install libaio防火墙问题如果无法通过Navicat等工具连接数据库,检查防火墙设置或开放1521端口firewall-cmd --permanent --add-port=1521/tcp firewall-cmd --reload结语通过以上步骤,您应该能够在 Linux 环境下成功卸载并重新安装 Oracle数据库。尽管过程中可能会遇到一些问题,但只要按照指南逐步操作,大多数问题都可以得到解决;希望本文对您有所帮助,祝您工作顺利!
Linux环境下卸载Oracle数据库并重新安装的详细指南 引言在 Linux 环境下管理和维护 Oracle 数据库是许多系统管理员和数据库管理员的日常工作之一。无论是出于升级、迁移还是解决故障的需要,卸载和重新安装 Oracle数据库 都是一项重要的技能。本文将为您提供一份详尽的指南,帮助您在 Linux 环境下彻底卸载 Oracle数据库,并重新安装。一、准备工作在开始卸载之前,确保您已经备份了所有重要的数据文件和配置信息,以防万一。同时,确保您具有足够的权限(通常是root用户)来执行以下操作。二、停止Oracle服务停止数据库实例使用 SQL Plus 停止数据库实例sqlplus /nolog SQL> connect / as sysdba SQL> shutdown immediate SQL> exit停止Listener服务使用 lsnrctl 命令停止Listenerlsnrctl stop停止HTTP服务如果您的环境中启用了HTTP服务,停止它:service httpd stop三、卸载Oracle软件切换到root用户如果您当前不是 root 用户,请切换到 rootsu - root删除Oracle安装目录删除 Oracle 的安装目录,通常是/u01/app/oraclerm -rf /u01/app/oracle删除相关文件和目录删除与Oracle相关的文件和目录rm /usr/local/bin/dbhome rm /usr/local/bin/oraenv rm /usr/local/bin/coraenv rm /etc/oratab rm /etc/oraInst.loc删除Oracle用户和用户组删除 Oracle 用户和相关的用户组userdel -r oracle groupdel oinstall groupdel dba groupdel oper删除启动服务删除与 Oracle 相关的启动服务chkconfig --del dbora四、清理环境变量编辑 /etc/profile 或 ~/.bash_profile 文件,删除与 Oracle 相关的环境变量设置。五、重新安装Oracle数据库前置条件确保系统满足Oracle的安装要求,如磁盘空间、内存等。安装并配置好Java环境。下载Oracle数据库安装包。创建Oracle用户和用户组groupadd oinstall groupadd dba useradd -g oinstall -G dba oracle设置环境变量编辑 ~/.bash_profile 文件,添加以下内容export ORACLE_BASE=/u01/app/oracle export ORACLE_HOME=$ORACLE_BASE/product/19.0.0/dbhome_1 export ORACLE_SID=ORCL export PATH=$ORACLE_HOME/bin:$PATH安装Oracle数据库解压安装包并运行安装脚本unzip linuxx64_19c_database.zip cd database ./runInstaller按照安装向导的提示完成安装。配置数据库安装完成后,运行 root.sh 脚本/u01/app/oracle/product/19.0.0/dbhome_1/root.sh初始化数据库dbca -silent -createDatabase -templateName General_Purpose.dbc -gdbname ORCL -sid ORCL -responseFile NO_VALUE -characterSet AL32UTF8 -memoryPercentage 40 -emConfiguration LOCAL -pdbName PDBORCL -sysPassword syspassword -systemPassword systempassword六、验证安装启动数据库sqlplus /nolog SQL> connect / as sysdba SQL> startup检查数据库状态SQL> select status from v$instance;七、常见问题及解决方案libaio问题如果在启动数据库时遇到 libaio 相关的错误,安装或重新安装 libaio 库yum install libaio防火墙问题如果无法通过Navicat等工具连接数据库,检查防火墙设置或开放1521端口firewall-cmd --permanent --add-port=1521/tcp firewall-cmd --reload结语通过以上步骤,您应该能够在 Linux 环境下成功卸载并重新安装 Oracle数据库。尽管过程中可能会遇到一些问题,但只要按照指南逐步操作,大多数问题都可以得到解决;希望本文对您有所帮助,祝您工作顺利! -
Oracle11.2.0.4打补丁实践 本文介绍如何给Oracle数据库打补丁,数据库版本为Oracle11.2.0.4,单实例,操作系统为CentOS7.9,Linux系统应该都可以。下载升级包因为没有MOS帐号,从网上下载了升级包p30670774_112040_Linux-x86-64.zip:数据库补丁p6880880_112000_Linux-x86-64.zip:opatch升级包百度云链接:https://pan.baidu.com/s/1ZvTQr-gI889mylgzUXkdPw提取码:plhp微云链接:https://share.weiyun.com/k8CbxL3Kopatch 是安装补丁的程序,数据库软件安装完成后,就自带了 opatch ,但是版本太旧了,所以这里下载最新的 opatch ,p6880880_112000_Linux-x86-64.zip 包就是用来升级 opatch 用的。升级opatchopatch 的升级只要将新版本的包解压,覆盖系统原始的文件即可。1.查看原始opatch信息[oracle@node1 ~]$ cd $ORACLE_HOME/OPatch [oracle@node1 OPatch]$ ./opatch version # 查看原始版本 OPatch Version: 11.2.0.3.4 OPatch succeeded.2.查看补丁情况[oracle@node1 OPatch]$ ./opatch lsinventory # 查看补丁情况 Oracle 中间补丁程序安装程序版本 11.2.0.3.4 版权所有 (c) 2012, Oracle Corporation。保留所有权利。 Oracle Home : /home/oracle/app/oracle/product/11.2.0/dbhome_1 Central Inventory : /home/oracle/app/oraInventory from : /home/oracle/app/oracle/product/11.2.0/dbhome_1/oraInst.loc OPatch version : 11.2.0.3.4 OUI version : 11.2.0.4.0 Log file location : /home/oracle/app/oracle/product/11.2.0/dbhome_1/cfgtoollogs/opatch/opatch2020-07-02_16-23-35下午_1.log Lsinventory Output file location : /home/oracle/app/oracle/product/11.2.0/dbhome_1/cfgtoollogs/opatch/lsinv/lsinventory2020-07-02_16-23-35下午.txt ---------------------------------------------------------------------------- 已安装的顶级产品 (1): Oracle Database 11g 11.2.0.4.0 此 Oracle 主目录中已安装 1 个产品。 此 Oracle 主目录中未安装任何中间补丁程序。 ---------------------------------------------------------------------------- OPatch succeeded.3.备份原opatch[oracle@node1 OPatch]$ cd $ORACLE_HOME [oracle@node1 dbhome_1]$ mv OPatch OPatch.bak4.解压新下载的opatch包将下载的 opatch 包上传到 oracle 的home目录,上传完后,解压到 $ORACLE_HOME 下[oracle@node1 dbhome_1]$ cd ~ [oracle@node1 ~]$ unzip p6880880_112000_Linux-x86-64.zip -d $ORACLE_HOME5.检查opatch是否升级成功[oracle@node1 ~]$ cd $ORACLE_HOME/OPatch [oracle@node1 OPatch]$ ./opatch version # 查看版本信息 OPatch Version: 11.2.0.3.21 OPatch succeeded.现在版本为 11.2.0.3.21,说明升级成功数据库打补丁1.关闭监听、数据库[oracle@node1 OPatch]$ lsnrctl stop # 关闭监听 [oracle@node1 ~]$ sqlplus / as sysdba SQL> shutdown immediate SQL> quit2.解压补丁包将下载的补丁包上传到 oracle home目录,并解压[oracle@node1 ~]$ cd ~ [oracle@node1 ~]$ unzip p30670774_112040_Linux-x86-64.zip3.校验冲突[oracle@node1 ~]$ cd 30670774/ [oracle@node1 30670774]$ $ORACLE_HOME/OPatch/opatch prereq CheckConflictAgainstOHWithDetail -ph ./ Oracle 临时补丁程序安装程序版本 11.2.0.3.21 版权所有 (c) 2020, Oracle Corporation。保留所有权利。 PREREQ session Oracle 主目录 :/home/oracle/app/oracle/product/11.2.0/dbhome_1 主产品清单:/home/oracle/app/oraInventory 来自 :/home/oracle/app/oracle/product/11.2.0/dbhome_1/oraInst.loc OPatch 版本 :11.2.0.3.21 OUI 版本 :11.2.0.4.0 日志文件位置:/home/oracle/app/oracle/product/11.2.0/dbhome_1/cfgtoollogs/opatch/opatch2020-07-02_16-54-06下午_1.log Invoking prereq "checkconflictagainstohwithdetail" Prereq "checkConflictAgainstOHWithDetail" passed. OPatch succeeded.由于这个测试库之前并没有打补丁,所以这里就没有补丁冲突的问题,如果这里显示有冲突,再去网MOS上查找相关解决方案。4.执行打补丁[oracle@node1 30670774]$ $ORACLE_HOME/OPatch/opatch apply这里要输入3次y和一次回车,打补丁的过程耗是比较久的,耐心等待5.检查打补丁情况[oracle@node1 30670774]$ $ORACLE_HOME/OPatch/opatch lsinventory # 检查打补丁情况这里会列出系统已打的补丁情况6.启动数据库,并运行sql文件[oracle@node1 30670774]$ cd $ORACLE_HOME/rdbms/admin [oracle@node1 30670774]$ sqlplus / as sysdba SQL> startup SQL> @catbundle.sql psu apply SQL> quit7.启动监听[oracle@node1 admin]$ lsnrctl start至此数据库打补丁已经全部完成回退数据库补丁数据库在做变更时,需要考虑回退方案,接下来介绍如何回退数据库补丁1.关闭监听、数据库[oracle@node1 ~]$ lsnrctl stop # 关闭监听 [oracle@node1 ~]$ sqlplus / as sysdba SQL> shutdown immediate SQL> quit2.回退补丁[oracle@node1 ~]$ $ORACLE_HOME/OPatch/opatch rollback -id 30670774这里要回复一次y,回退过程比较耗时,需耐心等待3.启动数据库,并运行sql文件[oracle@node1 ~]$ cd $ORACLE_HOME/rdbms/admin [oracle@node1 admin]$ sqlplus / as sysdba SQL> startup SQL> @catbundle_PSU_ORCL_ROLLBACK.sql # 这里的ORCL为实例名称 SQL> quit4.检查回退情况[oracle@node1 admin]$ $ORACLE_HOME/OPatch/opatch lsinventory # 检查打补丁情况 Oracle 临时补丁程序安装程序版本 11.2.0.3.21 版权所有 (c) 2020, Oracle Corporation。保留所有权利。 Oracle 主目录 :/home/oracle/app/oracle/product/11.2.0/dbhome_1 主产品清单:/home/oracle/app/oraInventory 来自 :/home/oracle/app/oracle/product/11.2.0/dbhome_1/oraInst.loc OPatch 版本 :11.2.0.3.21 OUI 版本 :11.2.0.4.0 日志文件位置:/home/oracle/app/oracle/product/11.2.0/dbhome_1/cfgtoollogs/opatch/opatch2020-07-02_18-24-48下午_1.log Lsinventory Output file location : /home/oracle/app/oracle/product/11.2.0/dbhome_1/cfgtoollogs/opatch/lsinv/lsinventory2020-07-02_18-24-48下午.txt -------------------------------------------------------------------------------- Local Machine Information:: Hostname: localhost ARU platform id: 226 ARU platform description:: Linux x86-64 已安装的顶级产品 (1): Oracle Database 11g 11.2.0.4.0 此 Oracle 主目录中已安装 1 个产品。 此 Oracle 主目录中未安装任何临时补丁程序。 -------------------------------------------------------------------------------- OPatch succeeded.可以看到,补丁已经被卸载了5.启动监听[oracle@node1 admin]$ lsnrctl start这样补丁回退就结束了总结本文介绍了单实例数据库打补丁的步骤,仅做参考,实际应以补丁包中的readme为准。
-
4款MYSQL实用脚本工具, 再也不怕写烂SQL了!!! 工具mysqltuner.pltuning-primer.shpt-variable-advisorpt-qurey-digest对于正在运行的mysql,性能如何,参数设置的是否合理,账号设置的是否存在安全隐患,你是否了然于胸呢?俗话说工欲善其事,必先利其器,定期对你的MYSQL数据库进行一个体检,是保证数据库安全运行的重要手段,因为,好的工具是使你的工作效率倍增!今天和大家分享几个mysql 优化的工具,你可以使用它们对你的mysql进行一个体检,生成awr报告,让你从整体上把握你的数据库的性能情况。mysqltuner.pl是mysql一个常用的数据库性能诊断工具,主要检查参数设置的合理性包括日志文件、存储引擎、安全建议及性能分析。针对潜在的问题,给出改进的建议。是mysql优化的好帮手。在上一版本中,MySQLTuner支持MySQL / MariaDB / Percona Server的约300个指标。项目地址:https://github.com/major/MySQLTuner-perl下载wget https://raw.githubusercontent.com/major/MySQLTuner-perl/master/mysqltuner.pl使用[root@localhost ~]# ./mysqltuner.pl --socket /var/lib/mysql/mysql.sock >> MySQLTuner 1.7.4 - Major Hayden <major@mhtx.net> >> Bug reports, feature requests, and downloads at http://mysqltuner.com/ >> Run with '--help' for additional options and output filtering [--] Skipped version check for MySQLTuner script Please enter your MySQL administrative login: root Please enter your MySQL administrative password: [OK] Currently running supported MySQL version 5.7.23 [OK] Operating on 64-bit architecture报告分析1)重要关注[!!](中括号有叹号的项)例如[!!] Maximum possible memory usage: 4.8G (244.13% of installed RAM),表示内存已经严重用超了。2)关注最后给的建议 “Recommendations ”。tuning-primer.shmysql的另一个优化工具,针于mysql的整体进行一个体检,对潜在的问题,给出优化的建议。项目地址:https://github.com/BMDan/tuning-primer.sh目前,支持检测和优化建议的内容如下:慢查询日志最大连接数工人线程密钥缓冲区[仅限MyISAM]查询缓存排序缓冲区加盟临时表表(开放和定义)缓存表锁定表扫描(read_buffer)[仅限MyISAM]InnoDB状态下载wget https://launchpad.net/mysql-tuning-primer/trunk/1.6-r1/+download/tuning-primer.sh使用[root@localhost ~]#./tuning-primer.sh -- MYSQL PERFORMANCE TUNING PRIMER -- - By: Matthew Montgomery -报告分析重点查看有红色告警的选项,根据建议结合自己系统的实际情况进行修改,例如:pt-variable-advisorpt-variable-advisor 可以分析MySQL变量并就可能出现的问题提出建议。项目地址:https://www.percona.com/downloads/percona-toolkit/LATEST/安装[root@localhost ~]#wget https://www.percona.com/downloads/percona-toolkit/3.0.13/binary/redhat/7/x86_64/percona-toolkit-3.0.13-re85ce15-el7-x86_64-bundle.tar [root@localhost ~]#yum install percona-toolkit-3.0.13-1.el7.x86_64.rpm使用pt-variable-advisor 是 pt 工具集的一个子工具,主要用来诊断你的参数设置是否合理。[root@localhost ~]# pt-variable-advisor localhost --socket /var/lib/mysql/mysql.sock报告分析重点关注有WARN的信息的条目,例如:pt-qurey-digestpt-query-digest 主要功能是从日志、进程列表和tcpdump分析MySQL查询。使用pt-query-digest 主要用来分析 mysql 的慢日志,与 mysqldumpshow 工具相比,py-query_digest 工具的分析结果更具体,更完善。[root@localhost ~]# pt-query-digest /var/lib/mysql/slowtest-slow.log常见用法分析1)直接分析慢查询文件:pt-query-digest /var/lib/mysql/slowtest-slow.log > slow_report.log2)分析最近12小时内的查询:pt-query-digest --since=12h /var/lib/mysql/slowtest-slow.log > slow_report2.log3)分析指定时间范围内的查询:pt-query-digest /var/lib/mysql/slowtest-slow.log --since '2017-01-07 09:30:00' --until '2017-01-07 10:00:00'> > slow_report3.log4)分析指含有select语句的慢查询pt-query-digest --filter '$event->{fingerprint} =~ m/^select/i' /var/lib/mysql/slowtest-slow.log> slow_report4.log5)针对某个用户的慢查询pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' /var/lib/mysql/slowtest-slow.log> slow_report5.log6)查询所有所有的全表扫描或full join的慢查询pt-query-digest --filter '(($event->{Full_scan} || "") eq "yes") ||(($event->{Full_join} || "") eq "yes")' /var/lib/mysql/slowtest-slow.log> slow_report6.log报告分析第一部分:总体统计结果Overall:总共有多少条查询Time range:查询执行的时间范围unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询total:总计min:最小max:最大avg:平均95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值median:中位数,把所有值从小到大排列,位置位于中间那个数第二部分:查询分组统计结果Rank:所有语句的排名,默认按查询时间降序排列,通过--order-by指定Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)Response:总的响应时间time:该查询在本次分析中总的时间占比calls:执行次数,即本次分析总共有多少条这种类型的查询语句R/Call:平均每次执行的响应时间V/M:响应时间Variance-to-mean的比率Item:查询对象第三部分:每一种查询的详细统计结果ID:查询的ID号,和上图的Query ID对应Databases:数据库名Users:各个用户执行的次数(占比)Query_time distribution :查询时间分布, 长短体现区间占比。Tables:查询中涉及到的表Explain:SQL语句
-
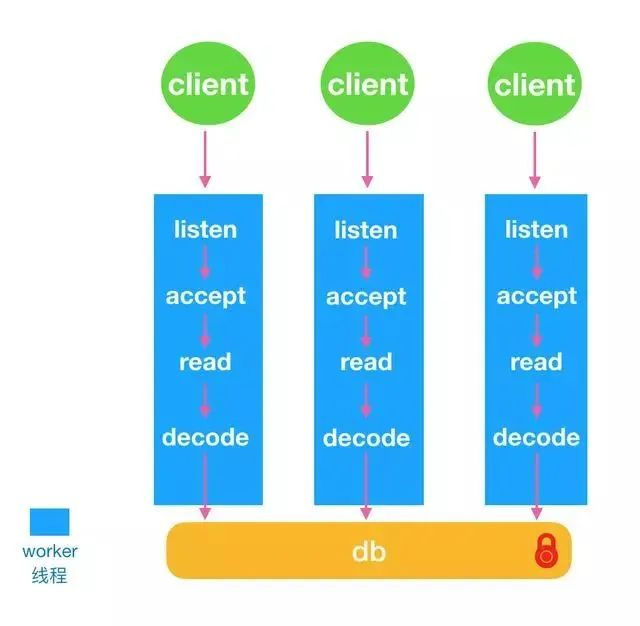
超越Redis,新一代Redis Plus来了,性能炸裂! 线程模型链接管理锁机制Active-Replica今天给大家介绍的是 KeyDB ,KeyDB项目是从redis fork出来的分支。众所周知redis是一个单线程的kv内存存储系统,而KeyDB在100%兼容redis API的情况下将redis改造成多线程。上次也跟大家说了,项目地址是:https://github.com/EQ-Alpha/KeyDB线程模型KeyDB 将 redis 原来的主线程拆分成了 主线程 和 worker线程 。每个worker线程都是io线程,负责监听端口,accept请求,读取数据和解析协议。如图所示:KeyDB使用了SO_REUSEPORT特性,多个线程可以绑定监听同个端口。每个worker线程做了cpu绑核,读取数据也使用了SO_INCOMING_CPU特性,指定cpu接收数据。解析协议之后每个线程都会去操作内存中的数据,由一把全局锁来控制多线程访问内存数据。主线程其实也是一个worker线程,包括了worker线程的工作内容,同时也包括只有主线程才可以完成的工作内容。在worker线程数组中下标为0的就是主线程。主线程的主要工作在实现 serverCron ,包括:处理统计客户端链接管理db数据的resize和reshard处理aofreplication主备同步cluster模式下的任务链接管理在redis中所有链接管理都是在一个线程中完成的。在KeyDB的设计中,每个worker线程负责一组链接,所有的链接插入到本线程的链接列表中维护。链接的产生、工作、销毁必须在同个线程中。每个链接新增一个字段int iel; /* the event loop index we're registered with */用来表示链接属于哪个线程接管。KeyDB维护了三个关键的数据结构做链接管理:clients_pending_write:线程专属的链表,维护同步给客户链接发送数据的队列clients_pending_asyncwrite:线程专属的链表,维护异步给客户链接发送数据的队列clients_to_close:全局链表,维护需要异步关闭的客户链接分成同步和异步两个队列,是因为redis有些联动api,比如pub/sub,pub之后需要给sub的客户端发送消息,pub执行的线程和sub的客户端所在线程不是同一个线程,为了处理这种情况,KeyDB将需要给非本线程的客户端发送数据维护在异步队列中。同步发送的逻辑比较简单,都是在本线程中完成,以下图来说明如何同步给客户端发送数据:如上文所提到的,一个链接的创建、接收数据、发送数据、释放链接都必须在同个线程执行。异步发送涉及到两个线程之间的交互。KeyDB通过管道在两个线程中传递消息:int fdCmdWrite; //写管道 int fdCmdRead; //读管道本地线程需要异步发送数据时,先检查client是否属于本地线程,非本地线程获取到client专属的线程ID,之后给专属的线程管到发送AE_ASYNC_OP::CreateFileEvent的操作,要求添加写socket事件。专属线程在处理管道消息时将对应的请求添加到写事件中,如图所示:redis有些关闭客户端的请求并非完全是在链接所在的线程执行关闭,所以在这里维护了一个全局的异步关闭链表。锁机制KeyDB实现了一套类似spinlock的锁机制,称之为fastlock。fastlock的主要数据结构有:int fdCmdWrite; //写管道 int fdCmdRead; //读管道使用原子操作__atomic_load_2,__atomic_fetch_add,__atomic_compare_exchange来通过比较m_active=m_avail判断是否可以获取锁。fastlock提供了两种获取锁的方式:try_lock:一次获取失败,直接返回lock:忙等,每1024 * 1024次忙等后使用sched_yield 主动交出cpu,挪到cpu的任务末尾等待执行。在KeyDB中将try_lock和事件结合起来,来避免忙等的情况发生。每个客户端有一个专属的lock,在读取客户端数据之前会先尝试加锁,如果失败,则退出,因为数据还未读取,所以在下个epoll_wait处理事件循环中可以再次处理。Active-ReplicaKeyDB实现了多活的机制,每个replica可设置成可写非只读,replica之间互相同步数据。主要特性有:每个replica有个uuid标志,用来去除环形复制新增加rreplay API,将增量命令打包成rreplay命令,带上本地的uuidkey,value加上时间戳版本号,作为冲突校验,如果本地有相同的key且时间戳版本号大于同步过来的数据,新写入失败。采用当前时间戳向左移20位,再加上后44位自增的方式来获取key的时间戳版本号。项目地址:https://github.com/EQ-Alpha/KeyDB
-
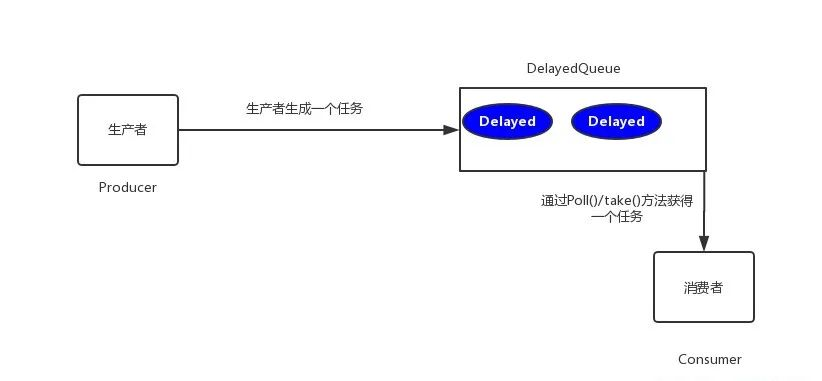
JAVA实现订单 30 分钟未支付则自动取消,我有五种方案! 引言方案分析(1)数据库轮询(2)JDK的延迟队列(3)时间轮算法(4)redis缓存(5)使用消息队列总结引言在开发中,往往会遇到一些关于延时任务的需求。例如:生成订单30分钟未支付,则自动取消;生成订单60秒后,给用户发短信。对上述的任务,我们给一个专业的名字来形容,那就是 延时任务 。那么这里就会产生一个问题,这个 延时任务和定时任务 的区别究竟在哪里呢?一共有如下几点区别:定时任务有明确的触发时间,延时任务没有;定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期;定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务。下面,我们以判断订单是否超时为例,进行方案分析。方案分析(1) 数据库轮询思路 该方案通常是在小型项目中使用,即通过一个线程定时的去扫描数据库,通过订单时间来判断是否有超时的订单,然后进行update或delete等操作。实现 博主当年早期是用 quartz 来实现的(实习那会的事),简单介绍一下 maven 项目引入一个依赖如下所示<dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.2.2</version> </dependency>调用Demo类MyJob如下所示package com.rjzheng.delay1; import org.quartz.JobBuilder; import org.quartz.JobDetail; import org.quartz.Scheduler; import org.quartz.SchedulerException; import org.quartz.SchedulerFactory; import org.quartz.SimpleScheduleBuilder; import org.quartz.Trigger; import org.quartz.TriggerBuilder; import org.quartz.impl.StdSchedulerFactory; import org.quartz.Job; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; public class MyJob implements Job { public void execute(JobExecutionContext context) throws JobExecutionException { System.out.println("要去数据库扫描啦。。。"); } public static void main(String[] args) throws Exception { // 创建任务 JobDetail jobDetail = JobBuilder.newJob(MyJob.class) .withIdentity("job1", "group1").build(); // 创建触发器 每3秒钟执行一次 Trigger trigger = TriggerBuilder .newTrigger() .withIdentity("trigger1", "group3") .withSchedule( SimpleScheduleBuilder.simpleSchedule() .withIntervalInSeconds(3).repeatForever()) .build(); Scheduler scheduler = new StdSchedulerFactory().getScheduler(); // 将任务及其触发器放入调度器 scheduler.scheduleJob(jobDetail, trigger); // 调度器开始调度任务 scheduler.start(); } }运行代码,可发现每隔3秒,输出如下要去数据库扫描啦。。。优缺点 优点: 简单易行,支持集群操作。缺点:(1)对服务器内存消耗大;(2)存在延迟,比如你每隔3分钟扫描一次,那最坏的延迟时间就是3分钟;(3)假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大。(2) JDK的延迟队列思路 该方案是利用 JDK 自带的 DelayQueue 来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入DelayQueue中的对象,是必须实现Delayed接口的。DelayedQueue实现工作流程如下图所示其中poll(): 获取并移除队列的超时元素,没有则返回空;take(): 获取并移除队列的超时元素,如果没有则wait当前线程,直到有元素满足超时条件,返回结果。实现定义一个类OrderDelay实现Delayed,代码如下:package com.rjzheng.delay2; import java.util.concurrent.Delayed; import java.util.concurrent.TimeUnit; public class OrderDelay implements Delayed { private String orderId; private long timeout; OrderDelay(String orderId, long timeout) { this.orderId = orderId; this.timeout = timeout + System.nanoTime(); } public int compareTo(Delayed other) { if (other == this) return 0; OrderDelay t = (OrderDelay) other; long d = (getDelay(TimeUnit.NANOSECONDS) - t .getDelay(TimeUnit.NANOSECONDS)); return (d == 0) ? 0 : ((d < 0) ? -1 : 1); } // 返回距离你自定义的超时时间还有多少 public long getDelay(TimeUnit unit) { return unit.convert(timeout - System.nanoTime(), TimeUnit.NANOSECONDS); } void print() { System.out.println(orderId+"编号的订单要删除啦。。。。"); } }运行的测试Demo为,我们设定延迟时间为3秒。package com.rjzheng.delay2; import java.util.ArrayList; import java.util.List; import java.util.concurrent.DelayQueue; import java.util.concurrent.TimeUnit; public class DelayQueueDemo { public static void main(String[] args) { // TODO Auto-generated method stub List<String> list = new ArrayList<String>(); list.add("00000001"); list.add("00000002"); list.add("00000003"); list.add("00000004"); list.add("00000005"); DelayQueue<OrderDelay> queue = new DelayQueue<OrderDelay>(); long start = System.currentTimeMillis(); for(int i = 0;i<5;i++){ //延迟三秒取出 queue.put(new OrderDelay(list.get(i), TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS))); try { queue.take().print(); System.out.println("After " + (System.currentTimeMillis()-start) + " MilliSeconds"); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }输出如下:00000001编号的订单要删除啦。。。。 After 3003 MilliSeconds 00000002编号的订单要删除啦。。。。 After 6006 MilliSeconds 00000003编号的订单要删除啦。。。。 After 9006 MilliSeconds 00000004编号的订单要删除啦。。。。 After 12008 MilliSeconds 00000005编号的订单要删除啦。。。。 After 15009 MilliSeconds可以看到都是延迟3秒,订单被删除。优缺点 优点: 效率高,任务触发时间延迟低。缺点:(1) 服务器重启后,数据全部消失,怕宕机;(2) 集群扩展相当麻烦;(3) 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常;(4) 代码复杂度较高。(3) 时间轮算法思路 先上一张时间轮的图(这图到处都是啦)时间轮算法可以类比于时钟,如上图箭头(指针)按某一个方向按固定频率轮动,每一次跳动称为一个 tick。这样可以看出定时轮由个3个重要的属性参数,ticksPerWheel(一轮的tick数),tickDuration(一个tick的持续时间)以及 timeUnit(时间单位),例如当ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和现实中的始终的秒针走动完全类似了。如果当前指针指在1上面,我有一个任务需要4秒以后执行,那么这个执行的线程回调或者消息将会被放在5上。那如果需要在20秒之后执行怎么办,由于这个环形结构槽数只到8,如果要20秒,指针需要多转2圈。位置是在2圈之后的5上面(20 % 8 + 1)。实现 我们用Netty的HashedWheelTimer来实现 给Pom加上下面的依赖:<dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.1.24.Final</version> </dependency>测试代码HashedWheelTimerTest,如下所示:package com.rjzheng.delay3; import io.netty.util.HashedWheelTimer; import io.netty.util.Timeout; import io.netty.util.Timer; import io.netty.util.TimerTask; import java.util.concurrent.TimeUnit; public class HashedWheelTimerTest { static class MyTimerTask implements TimerTask{ boolean flag; public MyTimerTask(boolean flag){ this.flag = flag; } public void run(Timeout timeout) throws Exception { // TODO Auto-generated method stub System.out.println("要去数据库删除订单了。。。。"); this.flag =false; } } public static void main(String[] argv) { MyTimerTask timerTask = new MyTimerTask(true); Timer timer = new HashedWheelTimer(); timer.newTimeout(timerTask, 5, TimeUnit.SECONDS); int i = 1; while(timerTask.flag){ try { Thread.sleep(1000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println(i+"秒过去了"); i++; } } }输出如下:1秒过去了 2秒过去了 3秒过去了 4秒过去了 5秒过去了 要去数据库删除订单了。。。。 6秒过去了优缺点 优点: 效率高,任务触发时间延迟时间比delayQueue低,代码复杂度比delayQueue低。缺点:(1) 服务器重启后,数据全部消失,怕宕机;(2) 集群扩展相当麻烦;(3) 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常。(4) redis缓存思路一 利用 redis 的 zset ,zset是一个有序集合,每一个元素(member)都关联了一个score,通过score排序来取集合中的值。zset常用命令添加元素:ZADD key score member [[score member] [score member] ...]按顺序查询元素:ZRANGE key start stop [WITHSCORES]查询元素score:ZSCORE key member移除元素:ZREM key member [member ...]测试如下: # 添加单个元素 redis> ZADD page_rank 10 google.com (integer) 1 # 添加多个元素 redis> ZADD page_rank 9 baidu.com 8 bing.com (integer) 2 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # 查询元素的score值 redis> ZSCORE page_rank bing.com "8" # 移除单个元素 redis> ZREM page_rank google.com (integer) 1 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9"那么如何实现呢?我们将订单超时时间戳与订单号分别设置为 score 和 member ,系统扫描第一个元素判断是否超时,具体如下图所示:实现一package com.rjzheng.delay4; import java.util.Calendar; import java.util.Set; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.Tuple; public class AppTest { private static final String ADDR = "127.0.0.1"; private static final int PORT = 6379; private static JedisPool jedisPool = new JedisPool(ADDR, PORT); public static Jedis getJedis() { return jedisPool.getResource(); } //生产者,生成5个订单放进去 public void productionDelayMessage(){ for(int i=0;i<5;i++){ //延迟3秒 Calendar cal1 = Calendar.getInstance(); cal1.add(Calendar.SECOND, 3); int second3later = (int) (cal1.getTimeInMillis() / 1000); AppTest.getJedis().zadd("OrderId", second3later,"OID0000001"+i); System.out.println(System.currentTimeMillis()+"ms:redis生成了一个订单任务:订单ID为"+"OID0000001"+i); } } //消费者,取订单 public void consumerDelayMessage(){ Jedis jedis = AppTest.getJedis(); while(true){ Set<Tuple> items = jedis.zrangeWithScores("OrderId", 0, 1); if(items == null || items.isEmpty()){ System.out.println("当前没有等待的任务"); try { Thread.sleep(500); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } continue; } int score = (int) ((Tuple)items.toArray()[0]).getScore(); Calendar cal = Calendar.getInstance(); int nowSecond = (int) (cal.getTimeInMillis() / 1000); if(nowSecond >= score){ String orderId = ((Tuple)items.toArray()[0]).getElement(); jedis.zrem("OrderId", orderId); System.out.println(System.currentTimeMillis() +"ms:redis消费了一个任务:消费的订单OrderId为"+orderId); } } } public static void main(String[] args) { AppTest appTest =new AppTest(); appTest.productionDelayMessage(); appTest.consumerDelayMessage(); } }此时对应输出如下:1525086085261ms:redis生成了一个订单任务:订单ID为OID00000010 1525086085263ms:redis生成了一个订单任务:订单ID为OID00000011 1525086085266ms:redis生成了一个订单任务:订单ID为OID00000012 1525086085268ms:redis生成了一个订单任务:订单ID为OID00000013 1525086085270ms:redis生成了一个订单任务:订单ID为OID00000014 1525086088000ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525086088001ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525086088002ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525086088003ms:redis消费了一个任务:消费的订单OrderId为OID00000013 1525086088004ms:redis消费了一个任务:消费的订单OrderId为OID00000014 当前没有等待的任务 当前没有等待的任务 当前没有等待的任务可以看到,几乎都是3秒之后,消费订单。然而,这一版存在一个致命的硬伤,在高并发条件下,多消费者会取到同一个订单号,我们上测试代码 ThreadTest 。package com.rjzheng.delay4; import java.util.concurrent.CountDownLatch; public class ThreadTest { private static final int threadNum = 10; private static CountDownLatch cdl = new CountDownLatch(threadNum); static class DelayMessage implements Runnable{ public void run() { try { cdl.await(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } AppTest appTest =new AppTest(); appTest.consumerDelayMessage(); } } public static void main(String[] args) { AppTest appTest =new AppTest(); appTest.productionDelayMessage(); for(int i=0;i<threadNum;i++){ new Thread(new DelayMessage()).start(); cdl.countDown(); } } }输出如下所示:1525087157727ms:redis生成了一个订单任务:订单ID为OID00000010 1525087157734ms:redis生成了一个订单任务:订单ID为OID00000011 1525087157738ms:redis生成了一个订单任务:订单ID为OID00000012 1525087157747ms:redis生成了一个订单任务:订单ID为OID00000013 1525087157753ms:redis生成了一个订单任务:订单ID为OID00000014 1525087160009ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525087160011ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525087160012ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525087160022ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525087160023ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525087160029ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525087160038ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525087160045ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525087160048ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525087160053ms:redis消费了一个任务:消费的订单OrderId为OID00000013 1525087160064ms:redis消费了一个任务:消费的订单OrderId为OID00000013 1525087160065ms:redis消费了一个任务:消费的订单OrderId为OID00000014 1525087160069ms:redis消费了一个任务:消费的订单OrderId为OID00000014 当前没有等待的任务 当前没有等待的任务 当前没有等待的任务 当前没有等待的任务显然,出现了多个线程消费同一个资源的情况。解决方案(1) 用分布式锁,但是用分布式锁,性能下降了,该方案不细说;(2) 对ZREM的返回值进行判断,只有大于0的时候,才消费数据,于是将 consumerDelayMessage() 方法里的。if(nowSecond >= score){ String orderId = ((Tuple)items.toArray()[0]).getElement(); jedis.zrem("OrderId", orderId); System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId); }修改为:if(nowSecond >= score){ String orderId = ((Tuple)items.toArray()[0]).getElement(); Long num = jedis.zrem("OrderId", orderId); if( num != null && num>0){ System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId); } }在这种修改后,重新运行ThreadTest类,发现输出正常了。思路二 该方案使用 redis 的 Keyspace Notifications ,中文翻译就是键空间机制,就是利用该机制可以在key失效之后,提供一个回调,实际上是redis会给客户端发送一个消息。是需要 redis版本2.8以上 。实现二 在 redis.conf 中,加入一条配置:notify-keyspace-events Ex运行代码如下:package com.rjzheng.delay5; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPubSub; public class RedisTest { private static final String ADDR = "127.0.0.1"; private static final int PORT = 6379; private static JedisPool jedis = new JedisPool(ADDR, PORT); private static RedisSub sub = new RedisSub(); public static void init() { new Thread(new Runnable() { public void run() { jedis.getResource().subscribe(sub, "__keyevent@0__:expired"); } }).start(); } public static void main(String[] args) throws InterruptedException { init(); for(int i =0;i<10;i++){ String orderId = "OID000000"+i; jedis.getResource().setex(orderId, 3, orderId); System.out.println(System.currentTimeMillis()+"ms:"+orderId+"订单生成"); } } static class RedisSub extends JedisPubSub { @Override public void onMessage(String channel, String message) { System.out.println(System.currentTimeMillis()+"ms:"+message+"订单取消"); } } }输出如下:1525096202813ms:OID0000000订单生成 1525096202818ms:OID0000001订单生成 1525096202824ms:OID0000002订单生成 1525096202826ms:OID0000003订单生成 1525096202830ms:OID0000004订单生成 1525096202834ms:OID0000005订单生成 1525096202839ms:OID0000006订单生成 1525096205819ms:OID0000000订单取消 1525096205920ms:OID0000005订单取消 1525096205920ms:OID0000004订单取消 1525096205920ms:OID0000001订单取消 1525096205920ms:OID0000003订单取消 1525096205920ms:OID0000006订单取消 1525096205920ms:OID0000002订单取消可以明显看到3秒过后,订单取消了。ps: redis的pub/sub 机制存在一个硬伤,官网内容如下:原: Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.翻: Redis的发布/订阅目前是即发即弃(fire and forget)模式的,因此无法实现事件的可靠通知。也就是说,如果发布/订阅的客户端断链之后又重连,则在客户端断链期间的所有事件都丢失了。因此,方案二不是太推荐。当然,如果你对可靠性要求不高,可以使用。优缺点 优点:(1) 由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性;(2) 做集群扩展相当方便;(3) 时间准确度高。缺点: (1) 需要额外进行redis维护。(5) 使用消息队列我们可以采用 RabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列:(1)RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter(2)lRabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能,具体的,我改天再写一篇文章,这里再讲下去,篇幅太长。优缺点优点: 高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。缺点:本身的易用度要依赖于rabbitMq的运维。因为要引用rabbitMq,所以复杂度和成本变高。总结本文总结了目前互联网中,绝大部分的延时任务的实现方案。希望大家在工作中能够有所收获。
-
Centos 7.9 离线安装 ORACLE 19C 本文涉及的安装包从以下百度网盘地址可获取:链接:https://pan.baidu.com/s/1XD_64B7awDjvkqcGXwWRqA提取码:42ow一、基础环境配置1、关闭系统防火墙systemctl stop firewalld systemctl disable firewalld2、关闭selinuxvim /etc/selinux/config SELINUX=disabled3、准备安装oracle安装所需依赖说明:下载安装oracle时所需依赖的rpm包,然后制作本地yum源进行安装rpm依赖包下载地址:https://pan.baidu.com/s/1zg6DUG0BTxY7H63lj78CrA 提取码:2ucbbase.zip放在/root路径下解压unzip base.zip创建离线yum源:备份原有repo文件 ,建个bakup文件夹把原路径下的文件放进去创建local.repo文件echo "[local]" > /etc/yum.repos.d/local.repo echo "name=local" >> /etc/yum.repos.d/local.repo echo "enable=1" >> /etc/yum.repos.d/local.repo echo "baseurl=file:///root/base" >> /etc/yum.repos.d/local.repo echo "gpgcheck=0" >> /etc/yum.repos.d/local.repoyum clean all4、安装oracle-database-preinstall 链接:https://pan.baidu.com/s/11TGhQ8H95umuV5PRUrfEcw 提取码:3yruyum -y localinstall oracle-database-preinstall-19c-1.0-1.el7.x86_64.rpm可能会出现如下报错:解决上面报错: 1.可以从以下网站缺少的依赖软件包:https://rpmfind.net/linux/rpm2html/search.php?query=kernel-headers&submit=Search+...&system=centos&arch=2.使用rpm命令手工安装缺少的依赖软件包rpm -i glibc-devel-2.17-317.el7.x86_64.rpm 二、安装Oracle 19c1、安装Oracle 19c 下载地址:https://www.oracle.com/database/technologies/oracle-database-software-downloads.htmlyum -y localinstall oracle-database-ee-19c-1.0-1.x86_64.rpm初始化Oracle数据库: 如需,可修改/etc/init.d/oracledb_ORCLCDB-19c,比如,CDB模式,实例ID等等。/etc/init.d/oracledb_ORCLCDB-19c configure配置环境变量: 切换用户su - oracle vim /home/oracle/.bash_profile加入以下内容:export ORACLE_HOME=/opt/oracle/product/19c/dbhome_1 export PATH=$PATH:/opt/oracle/product/19c/dbhome_1/bin export ORACLE_SID=ORCLCDB登陆oracle数据库(需要退出oracle用户重新登录):exit su - oracle sqlplus / as sysdba修改密码:alter user system identified by 123456;重新登录: ========================ORACLE19C的sqlnet.ora配置:/opt/oracle/product/19c/dbhome_1/network/adminNAMES.DIRECTORY_PATH= (TNSNAMES, ONAMES, HOSTNAME) SQLNET.AUTHENTICATION_SERVICES=(ALL) SQLNET.ALLOWED_LOGON_VERSION_SERVER=8 SQLNET.ALLOWED_LOGON_CLIENT=8 SQLNET.INBOUND_CONNECT_TIMEOUT=0 SQLNET.EXPIRE_TIME=10以上配置可解决兼容低版本客户端、客户端超时卡慢、dblink等问题,重启监听后生效lsnrctl stop lsnrctl start其中兼容低版本客户端的,在用户已经创建的情况下要再修改一次密码才能生效。表空间文件放置的文件夹需要对oracle用户授权:chown oracle:oinstall /data chown oracle:oinstall -R /data chmod 777 -R /data启动oraclelsnrctl start su - oracle sqlplus / as sysdba startup
-
-
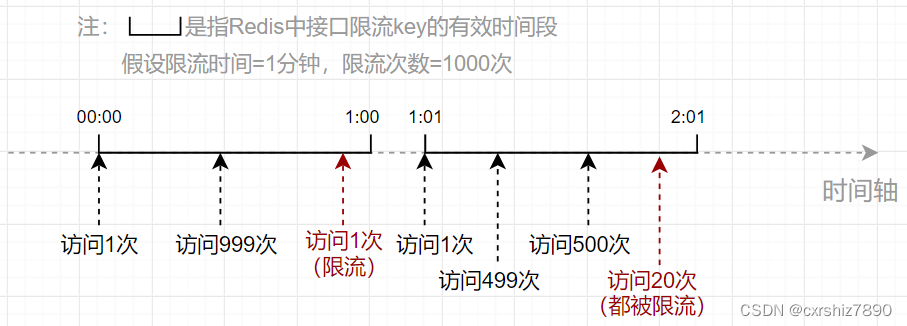
SpringBoot 项目使用 Redis 对用户 IP 进行接口限流 一、思路使用接口限流的主要目的在于提高系统的稳定性,防止接口被恶意打击(短时间内大量请求)。比如要求某接口在1分钟内请求次数不超过1000次,那么应该如何设计代码呢?下面讲两种思路,如果想看代码可直接翻到后面的代码部分。1.1 固定时间段(旧思路)1.1.1 思路描述 该方案的思路是:使用Redis记录固定时间段内某用户IP访问某接口的次数,其中:Redis的key:用户IP + 接口方法名Redis的value:当前接口访问次数。当用户在近期内第一次访问该接口时,向Redis中设置一个包含了用户IP和接口方法名的key,value的值初始化为1(表示第一次访问当前接口)。同时,设置该key的过期时间(比如为60秒)。之后,只要这个key还未过期,用户每次访问该接口都会导致value自增1次。用户每次访问接口前,先从Redis中拿到当前接口访问次数,如果发现访问次数大于规定的次数(如超过1000次),则向用户返回接口访问失败的标识。1.1.2 思路缺陷 该方案的缺点在于,限流时间段是固定的。比如要求某接口在1分钟内请求次数不超过1000次,观察以下流程:可以发现,00:59和01:01之间仅仅间隔了2秒,但接口却被访问了1000+999=1999次,是限流次数(1000次)的2倍!所以在该方案中,限流次数的设置可能不起作用,仍然可能在短时间内造成大量访问。1.2 滑动窗口(新思路)1.2.1 思路描述 为了避免出现方案1中由于键过期导致的短期访问量增大的情况,我们可以改变一下思路,也就是把固定的时间段改成动态的:假设某个接口在10秒内只允许访问5次。用户每次访问接口时,记录当前用户访问的时间点(时间戳),并计算前10秒内用户访问该接口的总次数。如果总次数大于限流次数,则不允许用户访问该接口。这样就能保证在任意时刻用户的访问次数不会超过1000次。如下图,假设用户在0:19时间点访问接口,经检查其前10秒内访问次数为5次,则允许本次访问。假设用户0:20时间点访问接口,经检查其前10秒内访问次数为6次(超出限流次数5次),则不允许本次访问。1.2.2 Redis部分的实现1)选用何种 Redis 数据结构首先是需要确定使用哪个Redis数据结构。用户每次访问时,需要用一个key记录用户访问的时间点,而且还需要利用这些时间点进行范围检查。为何选择 zSet 数据结构为了能够实现范围检查,可以考虑使用Redis中的zSet有序集合。添加一个zSet元素的命令如下:ZADD [key] [score] [member]它有一个关键的属性score,通过它可以记录当前member的优先级。于是我们可以把score设置成用户访问接口的时间戳,以便于通过score进行范围检查。key则记录用户IP和接口方法名,至于member设置成什么没有影响,一个member记录了用户访问接口的时间点。因此member也可以设置成时间戳。3)zSet 如何进行范围检查(检查前几秒的访问次数)思路是,把特定时间间隔之前的member都删掉,留下的member就是时间间隔之内的总访问次数。然后统计当前key中的member有多少个即可。① 把特定时间间隔之前的member都删掉。zSet有如下命令,用于删除score范围在[min~max]之间的member:Zremrangebyscore [key] [min] [max]假设限流时间设置为5秒,当前用户访问接口时,获取当前系统时间戳为currentTimeMill,那么删除的score范围可以设置为:min = 0 max = currentTimeMill - 5 * 1000相当于把5秒之前的所有member都删除了,只留下前5秒内的key。② 统计特定key中已存在的member有多少个。zSet有如下命令,用于统计某个key的member总数: ZCARD [key]统计的key的member总数,就是当前接口已经访问的次数。如果该数目大于限流次数,则说明当前的访问应被限流。二、代码实现主要是使用注解 + AOP的形式实现。2.1 固定时间段思路使用了lua脚本。参考:https://blog.csdn.net/qq_43641418/article/details/1277644622.1.1 限流注解@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface RateLimiter { /** * 限流时间,单位秒 */ int time() default 5; /** * 限流次数 */ int count() default 10; }2.1.2 定义lua脚本 在 resources/lua 下新建 limit.lua :-- 获取redis键 local key = KEYS[1] -- 获取第一个参数(次数) local count = tonumber(ARGV[1]) -- 获取第二个参数(时间) local time = tonumber(ARGV[2]) -- 获取当前流量 local current = redis.call('get', key); -- 如果current值存在,且值大于规定的次数,则拒绝放行(直接返回当前流量) if current and tonumber(current) > count then return tonumber(current) end -- 如果值小于规定次数,或值不存在,则允许放行,当前流量数+1 (值不存在情况下,可以自增变为1) current = redis.call('incr', key); -- 如果是第一次进来,那么开始设置键的过期时间。 if tonumber(current) == 1 then redis.call('expire', key, time); end -- 返回当前流量 return tonumber(current)2.1.3 注入Lua执行脚本 关键代码是 limitScript() 方法@Configuration public class RedisConfig { @Bean public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) { RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setConnectionFactory(connectionFactory); // 使用Jackson2JsonRedisSerialize 替换默认序列化(默认采用的是JDK序列化) Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); redisTemplate.setKeySerializer(jackson2JsonRedisSerializer); redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); redisTemplate.setHashKeySerializer(jackson2JsonRedisSerializer); redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer); return redisTemplate; } /** * 解析lua脚本的bean */ @Bean("limitScript") public DefaultRedisScript<Long> limitScript() { DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(); redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/limit.lua"))); redisScript.setResultType(Long.class); return redisScript; } }2.1.3 定义Aop切面类@Slf4j @Aspect @Component public class RateLimiterAspect { @Autowired private RedisTemplate redisTemplate; @Autowired private RedisScript<Long> limitScript; @Before("@annotation(rateLimiter)") public void doBefore(JoinPoint point, RateLimiter rateLimiter) throws Throwable { int time = rateLimiter.time(); int count = rateLimiter.count(); String combineKey = getCombineKey(rateLimiter.type(), point); List<String> keys = Collections.singletonList(combineKey); try { Long number = (Long) redisTemplate.execute(limitScript, keys, count, time); // 当前流量number已超过限制,则抛出异常 if (number == null || number.intValue() > count) { throw new RuntimeException("访问过于频繁,请稍后再试"); } log.info("[limit] 限制请求数'{}',当前请求数'{}',缓存key'{}'", count, number.intValue(), combineKey); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException("服务器限流异常,请稍候再试"); } } /** * 把用户IP和接口方法名拼接成 redis 的 key * @param point 切入点 * @return 组合key */ private String getCombineKey(JoinPoint point) { StringBuilder sb = new StringBuilder("rate_limit:"); ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); sb.append( Utils.getIpAddress(request) ); MethodSignature signature = (MethodSignature) point.getSignature(); Method method = signature.getMethod(); Class<?> targetClass = method.getDeclaringClass(); // keyPrefix + "-" + class + "-" + method return sb.append("-").append( targetClass.getName() ) .append("-").append(method.getName()).toString(); } }2.2 滑动窗口思路2.2.1 限流注解@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface RateLimiter { /** * 限流时间,单位秒 */ int time() default 5; /** * 限流次数 */ int count() default 10; }2.2.2 定义Aop切面类@Slf4j @Aspect @Component public class RateLimiterAspect { @Autowired private RedisTemplate redisTemplate; /** * 实现限流(新思路) * @param point * @param rateLimiter * @throws Throwable */ @SuppressWarnings("unchecked") @Before("@annotation(rateLimiter)") public void doBefore(JoinPoint point, RateLimiter rateLimiter) throws Throwable { // 在 {time} 秒内仅允许访问 {count} 次。 int time = rateLimiter.time(); int count = rateLimiter.count(); // 根据用户IP(可选)和接口方法,构造key String combineKey = getCombineKey(rateLimiter.type(), point); // 限流逻辑实现 ZSetOperations zSetOperations = redisTemplate.opsForZSet(); // 记录本次访问的时间结点 long currentMs = System.currentTimeMillis(); zSetOperations.add(combineKey, currentMs, currentMs); // 这一步是为了防止member一直存在于内存中 redisTemplate.expire(combineKey, time, TimeUnit.SECONDS); // 移除{time}秒之前的访问记录(滑动窗口思想) zSetOperations.removeRangeByScore(combineKey, 0, currentMs - time * 1000); // 获得当前窗口内的访问记录数 Long currCount = zSetOperations.zCard(combineKey); // 限流判断 if (currCount > count) { log.error("[limit] 限制请求数'{}',当前请求数'{}',缓存key'{}'", count, currCount, combineKey); throw new RuntimeException("访问过于频繁,请稍后再试!"); } } /** * 把用户IP和接口方法名拼接成 redis 的 key * @param point 切入点 * @return 组合key */ private String getCombineKey(JoinPoint point) { StringBuilder sb = new StringBuilder("rate_limit:"); ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); sb.append( Utils.getIpAddress(request) ); MethodSignature signature = (MethodSignature) point.getSignature(); Method method = signature.getMethod(); Class<?> targetClass = method.getDeclaringClass(); // keyPrefix + "-" + class + "-" + method return sb.append("-").append( targetClass.getName() ) .append("-").append(method.getName()).toString(); } }
-
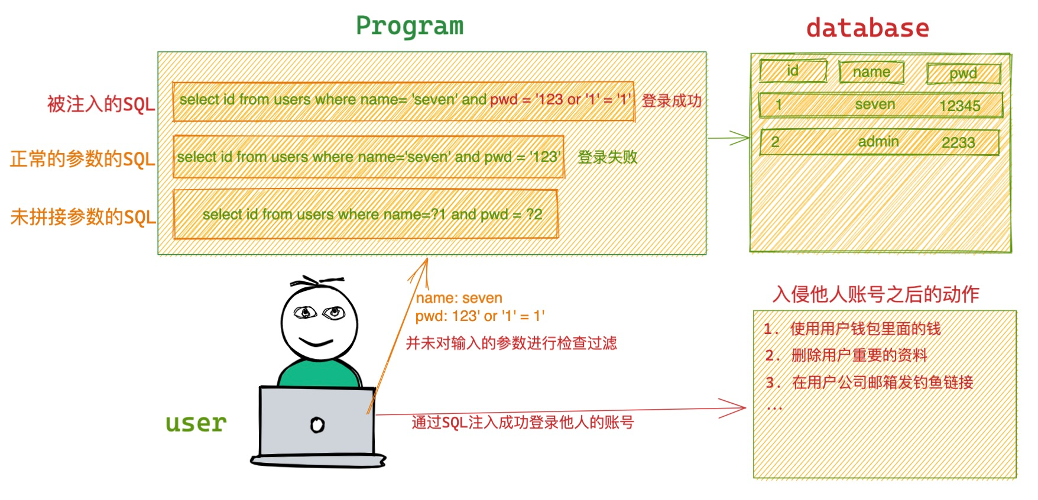
SQL注入介绍看这一篇就够了 SQL注入会引发什么问题?SQL注入 是一种 对数据库的恶意攻击 ,注入进去的恶意指令就会被误认为是正常的SQL指令而执行,因此遭到破坏或是入侵。什么是SQL注入?SQL注入(英语:SQL injection) ,也称SQL注入或SQL注码,是发生于应用程序与数据库层的安全漏洞。简而言之,是在输入的字符串之中注入SQL指令,在设计不良的程序当中忽略了字符检查,那么这些注入进去的恶意指令就会被数据库服务器误认为是正常的SQL指令而执行,因此遭到破坏或是入侵。为什么会发生SQL注入?在设计不良的应用程序中,对用户输入数据的合法性并没有判断或过滤不严导致。如图中所示,没有对客户端用户输入的数据合法性进行检查或过滤,导致客户端用户可以任意构造自己想要的参数,达成SQL注入条件,最终引发严重的后果,如果在账号登录成功SQL注入,那么就可以成功登录他人的账号,使用对他人的账号进行一系列破环手段,比如黑客通过SQL注入成功登录你的微信,可以使用你微信里面的余额,给你的家人朋友发钓鱼链接等等。当然SQL注入的危害远不止可以成功登录他人的账号,还有可能造成的伤害如下资料表中的资料外泄,例如企业及个人 机密资料,账户资料,密码 等;数据结构被黑客探知,得以做进一步攻击(例如 SELECT * FROM sys.tables );数据库服务器被攻击,系统管理员账户被窜改(例如 ALTER LOGIN sa WITH PASSWORD='xxxxxx' );获取系统较高权限后,有可能得以在网页加入恶意链接、恶意代码以及 Phishing 等;经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统(例如 xp_cmdshell "net stop iisadmin" 可停止服务器的 IIS服务 );攻击者利用数据库提供的各种功能操纵文件系统,写入Webshell,最终导致攻击者攻陷系统;破坏硬盘资料,瘫痪全系统(例如 xp_cmdshell "FORMAT C:" );获取系统最高权限后,可针对企业内部的任一管理系统做大规模破坏,甚至让其企业倒闭;网站主页被窜改,导致声誉受到损害。总之作为程序设计者,需要保证程序的健壮性避免被 SQL注入攻击 。如何避免SQL注入?所有的查询语句都使用数据库提供的 参数化查询(Parameterized Query) 接口,参数化的语句使用参数而不是将用户输入变量嵌入到SQL语句中,当前几乎所有的数据库系统都提供了 参数化SQL语句 执行接口,使用此接口可以非常有效的防止 SQL注入攻击 ;set @name := xxx; set @pwd := xxx; select id from users where name = @name and pwd = @pwd在组合SQL字符串时,先针对所传入的参数加入其他字符,对进入数据库的特殊字符('<>&*;)等等进行转义处理;确认每种数据的类型,比如数字型的数据就必须是数字,数据库中的存储字段必须对应为int型;try: pwd = int(param.get("pwd")) except (TypeError, ValueError): return "pwd type must be int"数据长度应该严格规定,能在一定程度上防止比较长的SQL注入语句无法正确执行;name_max_length = 12 if len(param.get("name", "")) > name_max_length: return "name length cannot be greater than 12"网站每个数据层的编码统一,建议全部使用 UTF-8编码 ,上下层编码不一致有可能导致一些过滤模型被绕过;严格限制网站用户的数据库的操作权限,给此用户提供仅仅能够满足其工作的权限,从而最大限度的减少注入攻击对数据库的危害;避免网站显示SQL错误信息,比如类型错误、字段不匹配等,防止攻击者利用这些错误信息进行一些判断。案例这里分析一个案例1.数据库中先创建用户表及数据-- 创建一张用户表 CREATE TABLE `users` ( `id` INT(11) NOT NULL AUTO INCREMENT, `username` VARCHAR(20), `password` VARCHAR(50), PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8; -- 插入数据 INSERT INTO users(username,`password`) VALUES('张三','456123'),('李 四','qqatfv'),('王五','Qwe123'); INSERT INTO users(username,`password`) VALUES('小张','987456'),('小 王','ngjplg'),('小李','!@#$%^'); -- 查看数据 SELECT * FROM users; +----+----------+----------+ | id | username | password | +----+----------+----------+ | 1 | 张三 | 456123 | | 2 | 李四 | qqatfv | | 3 | 王五 | Qwe123 | | 4 | 小张 | 987456 | | 5 | 小王 | ngjplg | | 6 | 小李 | !@#$%^ | +----+----------+----------+ 6 rows in set (0.00 sec)2.编写一个登录程序import pymysql def login(): # 打开数据库连接 db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='12345', db='test', charset='utf8') # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() username = input('请输入用户名:') password = input('请输入密码:') sql = "select * from users where username = '%s' and password = '%s'" % (username, password) print(sql) # 执行SQL语句 cursor.execute(sql) results = cursor.fetchone() if results: print('登录成功') else: print('登录失败') # 关闭数据库连接 db.close()2.1.正常登录>>> login() 请输入用户名:>? 张三 请输入密码:>? 456123 select * from users where username = '张三' and password = '456123' 登录成功, 你好:张三2.2.登录失败>>> login() 请输入用户名:>? 张三 请输入密码:>? 123456 select * from users where username = '张三' and password = '123456' 用户名或密码错误,请重新输入2.3.模拟注入此处我们给SQL注入了一个 or '1' = '1' 的条件,此时不管密码是否正确都可以成功登录login() 请输入用户名:>? 张三 请输入密码:>? 123456' or '1' = '1' select * from users where username = '张三' and password = '123456' or '1' = '1' 登录成功, 你好:张三3.解决方法,采用参数化查询import pymysql def login(): # 打开数据库连接 db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='12345', db='test', charset='utf8') # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() username = input('请输入用户名:') password = input('请输入密码:') sql = "select * from users where username = %s and password = %s" # 执行SQL语句 cursor.execute(sql, (username, password)) results = cursor.fetchone() if results: print('登录成功, 你好:', username) else: print('用户名或密码错误,请重新输入') # 关闭数据库连接 db.close()3.1.正常登录>>> login() 请输入用户名:>? 张三 请输入密码:>? 456123 登录成功, 你好:张三3.2.登录失败>>> login() 请输入用户名:>? 张三 请输入密码:>? 123456 用户名或密码错误,请重新输入3.3.继续模拟注入此处我们给SQL注入了一个 or '1' = '1' 的条件,此时我们使用的是 参数化查询 方式有效的防止了SQL注入login() 请输入用户名:>? 张三 请输入密码:>? 123456' or '1' = '1' 用户名或密码错误,请重新输入
-
Spring Boot + Redis 解决重复提交问题,一定用的到 前言在实际的开发项目中,一个对外暴露的接口往往会面临很多次请求,我们来解释一下幂等的概念:任意多次执行所产生的影响均与一次执行的影响相同。按照这个含义,最终的含义就是 对数据库的影响只能是一次性的,不能重复处理。如何保证其幂等性,通常有以下手段:数据库建立唯一性索引,可以保证最终插入数据库的只有一条数据token机制,每次接口请求前先获取一个token,然后再下次请求的时候在请求的header体中加上这个token,后台进行验证,如果验证通过删除token,下次请求再次判断token悲观锁或者乐观锁,悲观锁可以保证每次for update的时候其他sql无法update数据(在数据库引擎是innodb的时候,select的条件必须是唯一索引,防止锁全表)先查询后判断,首先通过查询数据库是否存在数据,如果存在证明已经请求过了,直接拒绝该请求,如果没有存在,就证明是第一次进来,直接放行。Redis实现自动幂等的原理图:搭建Redis的服务Api1、首先是搭建 Redis 服务器。2、引入 springboot 中到的 redis 的 stater ,或者 Spring 封装的 jedis 也可以,后面主要用到的 api 就是它的 set 方法和 exists 方法,这里我们使用 springboot 的封装好的 redisTemplate/** * redis工具类 */ @Component public class RedisService { @Autowired private RedisTemplate redisTemplate; /** * 写入缓存 * @param key * @param value * @return */ public boolean set(final String key, Object value) { boolean result = false; try { ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue(); operations.set(key, value); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 写入缓存设置时效时间 * @param key * @param value * @return */ public boolean setEx(final String key, Object value, Long expireTime) { boolean result = false; try { ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue(); operations.set(key, value); redisTemplate.expire(key, expireTime, TimeUnit.SECONDS); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 判断缓存中是否有对应的value * @param key * @return */ public boolean exists(final String key) { return redisTemplate.hasKey(key); } /** * 读取缓存 * @param key * @return */ public Object get(final String key) { Object result = null; ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue(); result = operations.get(key); return result; } /** * 删除对应的value * @param key */ public boolean remove(final String key) { if (exists(key)) { Boolean delete = redisTemplate.delete(key); return delete; } return false; } }自定义注解AutoIdempotent自定义一个注解,定义此注解的主要目的是把它添加在需要实现幂等的方法上,凡是某个方法注解了它,都会实现自动幂等。后台利用反射如果扫描到这个注解,就会处理这个方法实现自动幂等,使用元注解 ElementType.METHOD 表示它只能放在方法上, etentionPolicy.RUNTIME 表示它在运行时@Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface AutoIdempotent { }Token创建和检验1、Token服务接口 我们新建一个接口,创建 token 服务,里面主要是两个方法,一个用来创建 token ,一个用来验证 token 。创建 token 主要产生的是一个字符串,检验 token 的话主要是传达 request 对象,为什么要传 request 对象呢?主要作用就是获取 header 里面的 token ,然后检验,通过抛出的 Exception 来获取具体的报错信息返回给前端public interface TokenService { /** * 创建token * @return */ public String createToken(); /** * 检验token * @param request * @return */ public boolean checkToken(HttpServletRequest request) throws Exception; }2、Token的服务实现类 token 引用了 redis 服务,创建 token 采用随机算法工具类生成随机 uuid 字符串,然后放入到 redis 中(为了防止数据的冗余保留,这里设置过期时间为10000秒,具体可视业务而定),如果放入成功,最后返回这个 token 值。 checkToken 方法就是从 header 中获取 token 到值(如果 header 中拿不到,就从 paramter 中获取),如若不存在,直接抛出异常。这个异常信息可以被拦截器捕捉到,然后返回给前端。@Service public class TokenServiceImpl implements TokenService { @Autowired private RedisService redisService; /** * 创建token * * @return */ @Override public String createToken() { String str = RandomUtil.randomUUID(); StrBuilder token = new StrBuilder(); try { token.append(Constant.Redis.TOKEN_PREFIX).append(str); redisService.setEx(token.toString(), token.toString(),10000L); boolean notEmpty = StrUtil.isNotEmpty(token.toString()); if (notEmpty) { return token.toString(); } }catch (Exception ex){ ex.printStackTrace(); } return null; } /** * 检验token * * @param request * @return */ @Override public boolean checkToken(HttpServletRequest request) throws Exception { String token = request.getHeader(Constant.TOKEN_NAME); if (StrUtil.isBlank(token)) {// header中不存在token token = request.getParameter(Constant.TOKEN_NAME); if (StrUtil.isBlank(token)) {// parameter中也不存在token throw new ServiceException(Constant.ResponseCode.ILLEGAL_ARGUMENT, 100); } } if (!redisService.exists(token)) { throw new ServiceException(Constant.ResponseCode.REPETITIVE_OPERATION, 200); } boolean remove = redisService.remove(token); if (!remove) { throw new ServiceException(Constant.ResponseCode.REPETITIVE_OPERATION, 200); } return true; } }拦截器的配置1、Web配置类 实现WebMvcConfigurerAdapter,主要作用就是添加autoIdempotentInterceptor到配置类中,这样我们到拦截器才能生效,注意使用@Configuration注解,这样在容器启动是时候就可以添加进入context中@Configuration public class WebConfiguration extends WebMvcConfigurerAdapter { @Resource private AutoIdempotentInterceptor autoIdempotentInterceptor; /** * 添加拦截器 * @param registry */ @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(autoIdempotentInterceptor); super.addInterceptors(registry); } }2、拦截处理器 主要的功能是拦截扫描到 AutoIdempotent 到注解到方法,然后调用 tokenService 的 checkToken() 方法校验token是否正确,如果捕捉到异常就将异常信息渲染成json返回给前端/** * 拦截器 */ @Component public class AutoIdempotentInterceptor implements HandlerInterceptor { @Autowired private TokenService tokenService; /** * 预处理 * * @param request * @param response * @param handler * @return * @throws Exception */ @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { if (!(handler instanceof HandlerMethod)) { return true; } HandlerMethod handlerMethod = (HandlerMethod) handler; Method method = handlerMethod.getMethod(); //被ApiIdempotment标记的扫描 AutoIdempotent methodAnnotation = method.getAnnotation(AutoIdempotent.class); if (methodAnnotation != null) { try { return tokenService.checkToken(request);// 幂等性校验, 校验通过则放行, 校验失败则抛出异常, 并通过统一异常处理返回友好提示 }catch (Exception ex){ ResultVo failedResult = ResultVo.getFailedResult(101, ex.getMessage()); writeReturnJson(response, JSONUtil.toJsonStr(failedResult)); throw ex; } } //必须返回true,否则会被拦截一切请求 return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { } /** * 返回的json值 * @param response * @param json * @throws Exception */ private void writeReturnJson(HttpServletResponse response, String json) throws Exception{ PrintWriter writer = null; response.setCharacterEncoding("UTF-8"); response.setContentType("text/html; charset=utf-8"); try { writer = response.getWriter(); writer.print(json); } catch (IOException e) { } finally { if (writer != null) writer.close(); } } }测试用例1、模拟业务请求类 首先我们需要通过 /get/token 路径通过 getToken() 方法去获取具体的 token ,然后我们调用 testIdempotence 方法,这个方法上面注解了 @AutoIdempotent ,拦截器会拦截所有的请求,当判断到处理的方法上面有该注解的时候,就会调用 TokenService 中的 checkToken() 方法,如果捕获到异常会将异常抛出调用者,下面我们来模拟请求一下:@RestController public class BusinessController { @Resource private TokenService tokenService; @Resource private TestService testService; @PostMapping("/get/token") public String getToken(){ String token = tokenService.createToken(); if (StrUtil.isNotEmpty(token)) { ResultVo resultVo = new ResultVo(); resultVo.setCode(Constant.code_success); resultVo.setMessage(Constant.SUCCESS); resultVo.setData(token); return JSONUtil.toJsonStr(resultVo); } return StrUtil.EMPTY; } @AutoIdempotent @PostMapping("/test/Idempotence") public String testIdempotence() { String businessResult = testService.testIdempotence(); if (StrUtil.isNotEmpty(businessResult)) { ResultVo successResult = ResultVo.getSuccessResult(businessResult); return JSONUtil.toJsonStr(successResult); } return StrUtil.EMPTY; } }2、使用postman请求 首先访问get/token路径获取到具体到token:利用获取到到token,然后放到具体请求到header中,可以看到第一次请求成功,接着我们请求第二次:第二次请求,返回到是重复性操作,可见重复性验证通过,再多次请求到时候我们只让其第一次成功,第二次就是失败:总结本文介绍了使用 springboot 和 拦截器 、 redis 来优雅的实现接口幂等,对于幂等在实际的开发过程中是十分重要的,因为一个接口可能会被无数的客户端调用,如何保证其不影响后台的业务处理,如何保证其只影响数据一次是非常重要的,它可以防止产生脏数据或者乱数据,也可以减少并发量,实乃十分有益的一件事。而传统的做法是每次判断数据,这种做法不够智能化和自动化,比较麻烦。而今天的这种自动化处理也可以提升程序的伸缩性。