搜索到
43
篇与
的结果
-
 200 行 Rust 代码实现简单 CF Workers AI Bot | Rust 学习日记 本文由 High Ping Network 的小伙伴 GenshinMinecraft 进行编撰前言这次主要是用 Rust 重写了之前用 Python3 写的 Cloudflare Workers AI Telegram 机器人一边看着 《Rust 圣经》 一边 Coding,还是挺好玩的当然,因为我是 Rust 新手,所以代码中有问题的地方还请多多包涵请注意,本文会一步步讲解这一 Bot 的实现过程,也算是我学习 Rust 的一个阶段性总结如果你不想看实现过程,请直接翻到本文末尾开干!如何开启一个项目? 那当然是: 新建文件夹!环境环境配置请看 Rust 官方文档 新建文件夹并在终端输入以下命令来初始化一个项目:cargo new [文件夹名字]去 Telegram 申请一个新的 Bot ,保存 Bot Token 以留作备用 (这么简单懒得说了)然后前往这里来创建 Workers AI API 令牌 和 帐户 ID ,也是复制保存备用配置依赖在项目根目录下有个 Cargo.toml ,里面是有关项目信息的内容,在最底下添加如下内容:[dependencies] reqwest = { version = "0.12.4", features = ["json","blocking"] } serde_json = "1.0" teloxide = { version = "0.12", features = ["macros"] } tokio = { version = "1.38.0", features = ["rt-multi-thread", "macros"] } log = "0.4.21" simple_logger = "5.0.0"这里表示了项目需要用到这堆东西,如果之前有用过 Python ,那这玩意就可以理解为 requirements.txt然后删除 src/main.rs 中所有内容,并在开头引用这些库:use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; 这样就算引用完成了!PS: 你可能还需要去终端来安装一下依赖:cargo add reqwest serde_json teloxide log simple_logger常量定义// 初始化全局常量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = "";API_KEY: Workers AI API 令牌USER_ID: 帐户 IDPROMPT: AI 提示词MODEL: 对话使用的大模型,默认是阿里云的通义千问,可以在这里查看支持的模型,更改即可,非必要无需更改TELEGRAM_BOTTOKEN: Telegram Bot Token按照要求将 Workers AI API 令牌 和 帐户 ID 还有 Telegram Bot Token 放入对应的位置中,以便于下面调用如果有需要,也可以根据文档来修改 MODEL 模型和 PROMPT 提示词编写 GPT 请求函数先不着急编写 Bot 主体部分,来看下有关网络请求的调用函数定义// GPT 对话函数,用于请求 API 并返回async fn gpt(question: &str) -> Result<String, String> {}简单介绍一下:这句定义了一个名为 gpt 的异步函数,question 是参数返回值是 String 但是不确定是返回正常结果还是错误信息,这种做法有助于错误处理构建 Headers玩过大模型 API 的都知道,鉴权 (也就是 API_Tokens 这类东西) 一般是放在 Headers 里面的,所以我们要来构建 Headers而 Workers AI 的 API Headers 格式类似这样:Authorization: Bearer {API_TOKEN}于是,就有了下面的代码:// 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), );这里定义了一个变量 headers ,并用 insert 插入两条键值对其中 Authorization 用于存放 API_KEY ,用到了 format!() 宏格式化它的值,运用到了最开始定义的 API_KEY 常量Content-Type 则是表明了发送的数据格式,用于指示资源的MIME类型.parse() : 将字符串转化为 HeaderValue 类型,这是 reqwest 库用来存储 Headers 的类型.unwrap() : 直接获取结果而不进行错误处理 (有错误就退出,不过这段代码没有必要进行错误处理)构建请求体接下来是请求体:let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); 简单易懂,调用 `PROMPT` 和函数参数中的 `question` 即可,简单的 Json [发送请求] 终于可以发送请求了,首先,来初始化一个 HTTP Client: '''rust let client = reqwest::Client::new();随后就可以发送请求了:let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?;这里声明了一个 api 变量,用于存储获取到的数据client.post(): 则是发送 Post 请求的主要语句,URL 中的 Workers AI API 令牌 和 模型 还是一样使用 format!() 来构建headers(headers): 传递 Headers.json(&data): 将 data 转换为 Json 作为请求体.send().await: 这一步就相当于发送请求了,并等待异步操作完成.map_err(|_| "请求出现问题".to_string())?: 错误处理,如果发生问题则直接返回 请求出现问题 而不继续执行,如果出现错误则直接赋值给变量 api.text().await: 将收到的数据转换为文本信息,并等待异步操作完成.map_err(|_| "解析响应体时出错".to_string())?: 作用和上面那个差不多这样就算发送完一个请求并把接收到的信息赋值给 api 了解析 Json经过上面的请求,api 应该是一个 Json 格式的字符串,我们需要在里面提取出需要的答案Json 大概长这样:{ "result": {"response": "我是来自阿里云的超大规模语言模型,我叫通义千问。"}, "success": true, "errors": [], "messages": []}let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string())第一行代码尝试将变量 api 中存储的字符串解析为 JSON 格式,同样的 .map_err() 就不再解释了第一次从 Json 中获取信息返回的是 Option<&Value> 即可能有或可能没有,所以我们使用 .ok_or() 来判断有或无,当有时则直接赋值,没有则返回错误第二次从 Json 中获取信息也一样,不多赘述最后,返回 result 即可编写主程序呼呼,终于等待编写主程序了,不过主要的信息处理程序并不在 main 函数中,main 函数在代码中只起到一个引导的作用async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; }首先定义一个 main 异步函数,这是主程序的入口初始化一个 Log 记录器,这里使用了 simple_logger 库,该库无需繁琐地配置 Log 信息即可做到美观的输出,定义 Log Level 为 Debuginfo!() 宏是用来记录 Log 的,相同的,还有 debug!() warn!() error!() 等,分别记录不同等级的日志,下面不再赘述let bot = Bot::new(TELEGRAM_BOTTOKEN): 定义了一个名为 bot 的 Bot Client,它可以接收消息、发送消息等teloxide::repl:异步函数,可以启动一个 REPL 循环 (简要理解成可以处理新信息的循环即可),传入 Bot 并接受名为 msg 的信息提供给下面的代码。下面的代码即为消息处理程序msg.chat.is_private(): 返回一个布尔值,是否为私聊信息if msg.chat.is_private() {} else {}: 消息处理程序分成了两个部分,即判断是否为私聊 Bot,如果是则执行上半部分代码,否则执行下半部分msg.text(): 返回一个字符串,消息的文本内容因为 msg.text() 的类型为 Option<&str>,即可能有或没有 (没有文本信息的话可能为图片、文件、贴纸等),所以需要使用 match 做判断,如果有文本信息则将 bot 和 msg 传入 matchmsgprivate 或者 matchmsgpublic 函数中 (之后会定义这两个函数)当没有文本消息时候,则 Log Debug 输出总的来说,main 函数主要就是接受信息并交给其他函数处理 (尽管是小项目我个人还是建议不要全堆在 main 函数里面)处理私聊信息私聊信息需要做到:/start 发送帮助信息当直接对话 (不是 / 命令时),直接返回结果/ai 问题 返回问题的结果主要思路是判断消息是否为 / 开头,如果不是则直接返回 GPT 回答,如果是再进行指令判断async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } }先定义一个 text 用于储存文本信息,便于调用 (因为在主函数调用该函数时候已经做过检测,所以这里使用 .unwrap() 并无不妥)随后进行 / 开头命令检测,为否直接调用 replyai 函数 (等会定义),传入 msg, bot, msg.text() (不想处理借用问题,msg 用 .clone() 就好)如果为是,则使用 .splitn() 分割命令,command 为指令部分 (如 /start),argument 为参数部分 (可能没有,所以用 Option<&str>)如果命令开头为 /ai,则传入 replyai 函数;如果开头为 /start,则传入 replystart 函数 (等会定义)如果都不是机器人的指令,则不做处理,输出 Debug 信息处理群组信息这一部分和处理私聊信息差不多,区别只是非指令消息不回复async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }同样的逻辑,只是检测为非指令仅输出 Debug 消息而已AI 回复这里要实现一个函数需要传入 msg、bot、text 信息,调用 gpt 函数并发送回 Telegramasync fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; }定义异步函数不再赘述,需要注意 optiontext: Option<&str> 需要传入的是 Option<&str>,对应着消息处理函数的 argument既然 optiontext 为可能有可能没有的,那就先来检测一下。使用 match,当有值时赋值给 text;无值时输出 warn 信息并回复给用户,提示请查看 /start 指令,并退出检测成功后,调用 gpt 函数,也是使用 match。如果正常则赋值给 answer,有错误则输出 error 信息输出几条 info 信息,随后就可以将结果发送回 Telegram 了 (GPT 返回内容多使用 Markdown 格式,所以这里指定使用 MarkdownV2 格式发送)就这么简单,主要的代码还是错误处理,不然没有必要写这么多Start 回复最最最最简单的一部分,传入 bot 和 msg 即可async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; }定义一个字符串,作为帮助信息info 输出基本信息发送帮助信息完整代码 use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; // 初始化全局变量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = ""; // GPT 对话函数,用于请求 API 并返回 async fn gpt(question: &str) -> Result<String, String> { // 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), ); // 初始化问题 let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); // 初始化 Client let client = reqwest::Client::new(); // 请求 CF API let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?; // 解析 Json let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string()) } // 主函数 #[tokio::main] async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; } // GPT 回复函数 async fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; } // start 回复函数 async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; } // 私聊检测 async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } } // 非私聊 async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }保存后 执行下面指令即可编译运行:cargo build --release ./target/release/RUST总结这次主要是了解了 Rust 的基本语法,更深层次的还尚未触及到,对于代码中解释有误或代码有问题的请多多谅解
200 行 Rust 代码实现简单 CF Workers AI Bot | Rust 学习日记 本文由 High Ping Network 的小伙伴 GenshinMinecraft 进行编撰前言这次主要是用 Rust 重写了之前用 Python3 写的 Cloudflare Workers AI Telegram 机器人一边看着 《Rust 圣经》 一边 Coding,还是挺好玩的当然,因为我是 Rust 新手,所以代码中有问题的地方还请多多包涵请注意,本文会一步步讲解这一 Bot 的实现过程,也算是我学习 Rust 的一个阶段性总结如果你不想看实现过程,请直接翻到本文末尾开干!如何开启一个项目? 那当然是: 新建文件夹!环境环境配置请看 Rust 官方文档 新建文件夹并在终端输入以下命令来初始化一个项目:cargo new [文件夹名字]去 Telegram 申请一个新的 Bot ,保存 Bot Token 以留作备用 (这么简单懒得说了)然后前往这里来创建 Workers AI API 令牌 和 帐户 ID ,也是复制保存备用配置依赖在项目根目录下有个 Cargo.toml ,里面是有关项目信息的内容,在最底下添加如下内容:[dependencies] reqwest = { version = "0.12.4", features = ["json","blocking"] } serde_json = "1.0" teloxide = { version = "0.12", features = ["macros"] } tokio = { version = "1.38.0", features = ["rt-multi-thread", "macros"] } log = "0.4.21" simple_logger = "5.0.0"这里表示了项目需要用到这堆东西,如果之前有用过 Python ,那这玩意就可以理解为 requirements.txt然后删除 src/main.rs 中所有内容,并在开头引用这些库:use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; 这样就算引用完成了!PS: 你可能还需要去终端来安装一下依赖:cargo add reqwest serde_json teloxide log simple_logger常量定义// 初始化全局常量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = "";API_KEY: Workers AI API 令牌USER_ID: 帐户 IDPROMPT: AI 提示词MODEL: 对话使用的大模型,默认是阿里云的通义千问,可以在这里查看支持的模型,更改即可,非必要无需更改TELEGRAM_BOTTOKEN: Telegram Bot Token按照要求将 Workers AI API 令牌 和 帐户 ID 还有 Telegram Bot Token 放入对应的位置中,以便于下面调用如果有需要,也可以根据文档来修改 MODEL 模型和 PROMPT 提示词编写 GPT 请求函数先不着急编写 Bot 主体部分,来看下有关网络请求的调用函数定义// GPT 对话函数,用于请求 API 并返回async fn gpt(question: &str) -> Result<String, String> {}简单介绍一下:这句定义了一个名为 gpt 的异步函数,question 是参数返回值是 String 但是不确定是返回正常结果还是错误信息,这种做法有助于错误处理构建 Headers玩过大模型 API 的都知道,鉴权 (也就是 API_Tokens 这类东西) 一般是放在 Headers 里面的,所以我们要来构建 Headers而 Workers AI 的 API Headers 格式类似这样:Authorization: Bearer {API_TOKEN}于是,就有了下面的代码:// 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), );这里定义了一个变量 headers ,并用 insert 插入两条键值对其中 Authorization 用于存放 API_KEY ,用到了 format!() 宏格式化它的值,运用到了最开始定义的 API_KEY 常量Content-Type 则是表明了发送的数据格式,用于指示资源的MIME类型.parse() : 将字符串转化为 HeaderValue 类型,这是 reqwest 库用来存储 Headers 的类型.unwrap() : 直接获取结果而不进行错误处理 (有错误就退出,不过这段代码没有必要进行错误处理)构建请求体接下来是请求体:let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); 简单易懂,调用 `PROMPT` 和函数参数中的 `question` 即可,简单的 Json [发送请求] 终于可以发送请求了,首先,来初始化一个 HTTP Client: '''rust let client = reqwest::Client::new();随后就可以发送请求了:let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?;这里声明了一个 api 变量,用于存储获取到的数据client.post(): 则是发送 Post 请求的主要语句,URL 中的 Workers AI API 令牌 和 模型 还是一样使用 format!() 来构建headers(headers): 传递 Headers.json(&data): 将 data 转换为 Json 作为请求体.send().await: 这一步就相当于发送请求了,并等待异步操作完成.map_err(|_| "请求出现问题".to_string())?: 错误处理,如果发生问题则直接返回 请求出现问题 而不继续执行,如果出现错误则直接赋值给变量 api.text().await: 将收到的数据转换为文本信息,并等待异步操作完成.map_err(|_| "解析响应体时出错".to_string())?: 作用和上面那个差不多这样就算发送完一个请求并把接收到的信息赋值给 api 了解析 Json经过上面的请求,api 应该是一个 Json 格式的字符串,我们需要在里面提取出需要的答案Json 大概长这样:{ "result": {"response": "我是来自阿里云的超大规模语言模型,我叫通义千问。"}, "success": true, "errors": [], "messages": []}let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string())第一行代码尝试将变量 api 中存储的字符串解析为 JSON 格式,同样的 .map_err() 就不再解释了第一次从 Json 中获取信息返回的是 Option<&Value> 即可能有或可能没有,所以我们使用 .ok_or() 来判断有或无,当有时则直接赋值,没有则返回错误第二次从 Json 中获取信息也一样,不多赘述最后,返回 result 即可编写主程序呼呼,终于等待编写主程序了,不过主要的信息处理程序并不在 main 函数中,main 函数在代码中只起到一个引导的作用async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; }首先定义一个 main 异步函数,这是主程序的入口初始化一个 Log 记录器,这里使用了 simple_logger 库,该库无需繁琐地配置 Log 信息即可做到美观的输出,定义 Log Level 为 Debuginfo!() 宏是用来记录 Log 的,相同的,还有 debug!() warn!() error!() 等,分别记录不同等级的日志,下面不再赘述let bot = Bot::new(TELEGRAM_BOTTOKEN): 定义了一个名为 bot 的 Bot Client,它可以接收消息、发送消息等teloxide::repl:异步函数,可以启动一个 REPL 循环 (简要理解成可以处理新信息的循环即可),传入 Bot 并接受名为 msg 的信息提供给下面的代码。下面的代码即为消息处理程序msg.chat.is_private(): 返回一个布尔值,是否为私聊信息if msg.chat.is_private() {} else {}: 消息处理程序分成了两个部分,即判断是否为私聊 Bot,如果是则执行上半部分代码,否则执行下半部分msg.text(): 返回一个字符串,消息的文本内容因为 msg.text() 的类型为 Option<&str>,即可能有或没有 (没有文本信息的话可能为图片、文件、贴纸等),所以需要使用 match 做判断,如果有文本信息则将 bot 和 msg 传入 matchmsgprivate 或者 matchmsgpublic 函数中 (之后会定义这两个函数)当没有文本消息时候,则 Log Debug 输出总的来说,main 函数主要就是接受信息并交给其他函数处理 (尽管是小项目我个人还是建议不要全堆在 main 函数里面)处理私聊信息私聊信息需要做到:/start 发送帮助信息当直接对话 (不是 / 命令时),直接返回结果/ai 问题 返回问题的结果主要思路是判断消息是否为 / 开头,如果不是则直接返回 GPT 回答,如果是再进行指令判断async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } }先定义一个 text 用于储存文本信息,便于调用 (因为在主函数调用该函数时候已经做过检测,所以这里使用 .unwrap() 并无不妥)随后进行 / 开头命令检测,为否直接调用 replyai 函数 (等会定义),传入 msg, bot, msg.text() (不想处理借用问题,msg 用 .clone() 就好)如果为是,则使用 .splitn() 分割命令,command 为指令部分 (如 /start),argument 为参数部分 (可能没有,所以用 Option<&str>)如果命令开头为 /ai,则传入 replyai 函数;如果开头为 /start,则传入 replystart 函数 (等会定义)如果都不是机器人的指令,则不做处理,输出 Debug 信息处理群组信息这一部分和处理私聊信息差不多,区别只是非指令消息不回复async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }同样的逻辑,只是检测为非指令仅输出 Debug 消息而已AI 回复这里要实现一个函数需要传入 msg、bot、text 信息,调用 gpt 函数并发送回 Telegramasync fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; }定义异步函数不再赘述,需要注意 optiontext: Option<&str> 需要传入的是 Option<&str>,对应着消息处理函数的 argument既然 optiontext 为可能有可能没有的,那就先来检测一下。使用 match,当有值时赋值给 text;无值时输出 warn 信息并回复给用户,提示请查看 /start 指令,并退出检测成功后,调用 gpt 函数,也是使用 match。如果正常则赋值给 answer,有错误则输出 error 信息输出几条 info 信息,随后就可以将结果发送回 Telegram 了 (GPT 返回内容多使用 Markdown 格式,所以这里指定使用 MarkdownV2 格式发送)就这么简单,主要的代码还是错误处理,不然没有必要写这么多Start 回复最最最最简单的一部分,传入 bot 和 msg 即可async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; }定义一个字符串,作为帮助信息info 输出基本信息发送帮助信息完整代码 use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; // 初始化全局变量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = ""; // GPT 对话函数,用于请求 API 并返回 async fn gpt(question: &str) -> Result<String, String> { // 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), ); // 初始化问题 let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); // 初始化 Client let client = reqwest::Client::new(); // 请求 CF API let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?; // 解析 Json let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string()) } // 主函数 #[tokio::main] async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; } // GPT 回复函数 async fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; } // start 回复函数 async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; } // 私聊检测 async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } } // 非私聊 async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }保存后 执行下面指令即可编译运行:cargo build --release ./target/release/RUST总结这次主要是了解了 Rust 的基本语法,更深层次的还尚未触及到,对于代码中解释有误或代码有问题的请多多谅解 -
Maven异常:was cached in the local repository, resolution will not be reattempted until the update mvn打包时遇到异常,使用 -X 参数输出详细的日志(mvn -X package),异常信息如下:Failure to find cn.com.xxx... in https://maven.aliyun.com/repository/public was cached in the local repository, resolution will not be reattempted until the update interval of aliyunmaven has elapsed or updates are forced基本情况导致报错的依赖为私有的jar,是手动放置到本地仓库的。镜像仓库配置了阿里云的。可能原因 由于第一次构建项目时没事先放置本地依赖,Maven会尝试从远程下载依赖,找不到依赖就会导致构建失败,并会在依赖的目录下新建了 .lastUpdated 文件。在这之后,手动放置了依赖。第二次进行构建,Maven默认会使用本地缓存的库来编译工程,当发现 .lastUpdated 时,则会认为该依赖异常,最终导致构建失败。解决方案 尝试删除仓库中的.lastUpdated文件,先进入到仓库根目录,再执行如下命令Window环境for /r %i in (*.lastUpdated) do del %ifor /r %i in (_remote.repositories) do del %iLinux环境find . -name "*.lastUpdated" | xargs rm -frfind . -name "_remote.repositories" | xargs rm -fr
-
后端如何做到无感刷新Token? 前言为什么需要无感刷新Token?自动刷新token前端token续约疑问及思考为什么需要无感刷新Token?最近浏览到一个文章里面的提问,是这样的: 当我在系统页面上做业务操作的时候会出现突然闪退的情况,然后跳转到登录页面需要重新登录系统,系统使用了Redis做缓存来存储用户ID,和用户的token信息,这是什么问题呢?解答: 突然闪退,一般都是由于你的token过期的问题,导致身份失效。解决方案: 自动刷新tokentoken续约思路 如果Token即将过期,你在验证用户权限的同时,为用户生成一个新的Token并返回给客户端,客户端需要更新本地存储的Token,还可以做定时任务来刷新Token,可以不生成新的Token,在快过期的时候,直接给Token增加时间自动刷新token自动刷新token是属于后端的解决方案,由后端来检查一个Token的过期时间是否快要过期了,如果快要过期了,就往请求头中重新放一个token,然后前端那边做拦截,拿到请求头里面的新的token,如果这个新的token和老的token不一致,直接将本地的token更换接下来拿代码举例子先引入依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.5.1</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.33</version> </dependency> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9.1</version> </dependency>这是一个生成token的例子import io.jsonwebtoken.Claims; import io.jsonwebtoken.JwtBuilder; import io.jsonwebtoken.Jwts; import io.jsonwebtoken.SignatureAlgorithm; import javax.crypto.SecretKey; import javax.crypto.spec.SecretKeySpec; import java.util.Base64; import java.util.Date; import java.util.UUID; public class JwtUtil { // 有效期为 public static final Long JWT_TTL = 60 * 60 * 1000 * 24;// 60 * 60 * 1000 * 24 一个小时 // 设置秘钥明文 --- 自己改就行 public static final String JWT_KEY = "qx"; // 用于生成uuid,用来标识唯一 public static String getUUID(){ String uuid = UUID.randomUUID().toString().replaceAll("-", "");//token用UUID来代替 return uuid; } /** id : 标识唯一 subject : 我们想要加密存储的数据 ttl : 我们想要设置的过期时间 */ // 生成token jwt加密 subject token中要存放的数据(json格式) public static String createJWT(String subject) { JwtBuilder builder = getJwtBuilder(subject, null, getUUID());// 设置过期时间 return builder.compact(); } // 生成token jwt加密 public static String createJWT(String subject, Long ttlMillis) { JwtBuilder builder = getJwtBuilder(subject, ttlMillis, getUUID());// 设置过期时间 return builder.compact(); } // 创建token jwt加密 public static String createJWT(String id, String subject, Long ttlMillis) { JwtBuilder builder = getJwtBuilder(subject, ttlMillis, id);// 设置过期时间 return builder.compact(); } private static JwtBuilder getJwtBuilder(String subject, Long ttlMillis, String uuid) { SignatureAlgorithm signatureAlgorithm = SignatureAlgorithm.HS256; SecretKey secretKey = generalKey(); long nowMillis = System.currentTimeMillis(); Date now = new Date(nowMillis); if(ttlMillis==null){ ttlMillis=JwtUtil.JWT_TTL; } long expMillis = nowMillis + ttlMillis; Date expDate = new Date(expMillis); return Jwts.builder() .setId(uuid) //唯一的ID .setSubject(subject) // 主题 可以是JSON数据 .setIssuer("sg") // 签发者 .setIssuedAt(now) // 签发时间 .signWith(signatureAlgorithm, secretKey) //使用HS256对称加密算法签名, 第二个参数为秘钥 .setExpiration(expDate); } // 生成加密后的秘钥 secretKey public static SecretKey generalKey() { byte[] encodedKey = Base64.getDecoder().decode(JwtUtil.JWT_KEY); SecretKey key = new SecretKeySpec(encodedKey, 0, encodedKey.length, "AES"); return key; } // jwt解密 public static Claims parseJWT(String jwt) throws Exception { SecretKey secretKey = generalKey(); return Jwts.parser() .setSigningKey(secretKey) .parseClaimsJws(jwt) .getBody(); } }写个单元测试,测试一下@Test void test() throws Exception { String token = JwtUtil.createJWT("1735209949551763457"); System.out.println("Token: " + token); Date tokenExpirationDate = getTokenExpirationDate(token); System.out.println(tokenExpirationDate); System.out.println(tokenExpirationDate.toString()); long exp = tokenExpirationDate.getTime(); long cur = System.currentTimeMillis(); System.out.println(exp); System.out.println(cur); System.out.println(exp - cur); } // 解析令牌并获取过期时间 public static Date getTokenExpirationDate(String token) { try { SecretKey secretKey = generalKey(); Claims claims = Jwts.parser() .setSigningKey(secretKey) .parseClaimsJws(token) .getBody(); return claims.getExpiration(); } catch (ExpiredJwtException | SignatureException e) { throw new RuntimeException("Invalid token", e); } }可以看到我们的 exp 过期时间的毫秒数为 1703651262000可以看到我们的 cur 当前时间的毫秒数为 1703564863035我们将两者相减得到的值为 86398965ms,我们可以算一下一天的毫秒数是多少 1000 60 60 * 24 ms = 86400000ms这样我们就能够拿到token的过期时间tokenExpirationDate了我们就可以通过在校验token的时候,如果token校验通过了,此时我们拿到该token的过期时间,以(过期时间 - 当前时间)进行判断如果说 (过期时间 - 当前时间) 小于约定的值,那么我们就重新根据token里面的信息,重新创建一个token,将新的token放到请求头中返回给前端,前端去进行本地存储更新token前端token续约token的续约偏向于前端的解决方案,即由前端来进行token的过期时间的判断,首先前后端需要对接商量好一个token续约的接口,当前端发现这个token快要过期的时候,向后端发送该token,然后后端将该token的过期时间延长。「前端采用的是双Token的方式,access-token 和 refresh-token即 AT 和 RT」「而对于纯后端的方式,就是只有access-token这一个token」「那么问题来了 AT 和 RT 到底有什么区别?为什么需要RT?」「在前端实现方案来说,RT是用来在AT即将过期的时候,用RT获取最新的token」我解释一下我的观点:AT的暴露机会更多,每个请求都要携带,所以设置的过期时间短一点,「减少劫持风险」RT只会暴露在auth服务中用来刷新at,设置的过期时间长一点,「增加便利性。」AT 和 RT 是为了网络传输安全,网络传输中,容易暴露 AT,因为 AT 时间短,暴露后风险系数才低「这种是标准的安全处理,其实已经无需探讨他的合理性,就好像 https 之于 http 一样」疑问及思考要是前端有一个表单页面,长时间不进行请求的发送,此时用户填写完表单了,再点击提交的时候,后端返回401了,怎么办?也就是说,虽然你后端可以无感刷新Token,但是你后端无感刷新Token的前提是:前端得发请求,如果用户长时间不进行页面的交互,即没有进行任何业务逻辑的跳转什么的,就单纯的往表单上面填东西,什么请求也没发的情况下,后端是无法感知Token过期的这种情况怎么解决? 对于纯后端的解决方案,我是这样想的让前端在表单填写内容的时候做处理,如果提交返回的是401,那么前端就需要获取表单存在本地存储 然后跳转登录页,登录成功后,返回这个页面,然后从本地存储取出来再回显到表单上面。对于前端的解决方案,我是这样想的对于后端来说就是AT过期了,而对于前端来说就是AT和RT都过期了,怎么处理?需要监听refresh token的过期时间,在接近过期的时候向后端发起请求来刷新refresh token 或者是定期刷新一下refresh token和后端的解决方案一样,前端做一个类似草稿箱的功能对表单等元素进行保存
-
动态更改 Spring 定时任务 Cron 表达式 在 SpringBoot 项目中,我们可以通过 @EnableScheduling 注解开启调度任务支持,并通过 @Scheduled 注解快速地建立一系列定时任务。@Scheduled 支持下面三种配置执行时间的方式:cron(expression):根据Cron表达式来执行。fixedDelay(period):固定间隔时间执行,无论任务执行长短,两次任务执行的间隔总是相同的。fixedRate(period):固定频率执行,从任务启动之后,总是在固定的时刻执行,如果因为执行时间过长,造成错过某个时刻的执行(晚点),则任务会被立刻执行。最常用的应该是第一种方式,基于Cron表达式的执行模式,因其相对来说更加灵活。可变与不可变默认情况下,@Scheduled 注解标记的定时任务方法在初始化之后,是不会再发生变化的。 Spring 在初始化 bean 后,通过后处理器拦截所有带有 @Scheduled 注解的方法,并解析相应的的注解参数,放入相应的定时任务列表等待后续统一执行处理。到定时任务真正启动之前,我们都有机会更改任务的执行周期等参数。换言之,我们既可以通过 application.properties 配置文件配合 @Value 注解的方式指定任务的 Cron 表达式,亦可以通过 CronTrigger 从数据库或者其他任意存储中间件中加载并注册定时任务。这是 Spring 提供给我们的可变的部分。但是我们往往要得更多。能否在定时任务已经在执行过的情况下,去动态更改 Cron 表达式,甚至禁用某个定时任务呢?很遗憾,默认情况下,这是做不到的,任务一旦被注册和执行,用于注册的参数便被固定下来,这是不可变的部分。创造与毁灭既然创造之后不可变,那就毁灭之后再重建吧。于是乎,我们的思路便是,在注册期间保留任务的关键信息,并通过另一个定时任务检查配置是否发生变化,如果有变化,就把“前任”干掉,取而代之。如果没有变化,就保持原样。先对任务做个简单的抽象,方便统一的识别和管理:public interface IPollableService { /** * 执行方法 */ void poll(); /** * 获取周期表达式 * * @return CronExpression */ default String getCronExpression() { return null; } /** * 获取任务名称 * * @return 任务名称 */ default String getTaskName() { return this.getClass().getSimpleName(); } }最重要的便是 getCronExpression() 方法,每个定时服务实现可以自己控制自己的表达式,变与不变,自己说了算。至于从何处获取,怎么获取,请诸君自行发挥了。接下来,就是实现任务的动态注册:@Configuration @EnableAsync @EnableScheduling public class SchedulingConfiguration implements SchedulingConfigurer, ApplicationContextAware { private static final Logger log = LoggerFactory.getLogger(SchedulingConfiguration.class); private static ApplicationContext appCtx; private final ConcurrentMap<String, ScheduledTask> scheduledTaskHolder = new ConcurrentHashMap<>(16); private final ConcurrentMap<String, String> cronExpressionHolder = new ConcurrentHashMap<>(16); private ScheduledTaskRegistrar taskRegistrar; public static synchronized void setAppCtx(ApplicationContext appCtx) { SchedulingConfiguration.appCtx = appCtx; } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { setAppCtx(applicationContext); } @Override public void configureTasks(ScheduledTaskRegistrar taskRegistrar) { this.taskRegistrar = taskRegistrar; } /** * 刷新定时任务表达式 */ public void refresh() { Map<String, IPollableService> beanMap = appCtx.getBeansOfType(IPollableService.class); if (beanMap.isEmpty() || taskRegistrar == null) { return; } beanMap.forEach((beanName, task) -> { String expression = task.getCronExpression(); String taskName = task.getTaskName(); if (null == expression) { log.warn("定时任务[{}]的任务表达式未配置或配置错误,请检查配置", taskName); return; } // 如果策略执行时间发生了变化,则取消当前策略的任务,并重新注册任务 boolean unmodified = scheduledTaskHolder.containsKey(beanName) && cronExpressionHolder.get(beanName).equals(expression); if (unmodified) { log.info("定时任务[{}]的任务表达式未发生变化,无需刷新", taskName); return; } Optional.ofNullable(scheduledTaskHolder.remove(beanName)).ifPresent(existTask -> { existTask.cancel(); cronExpressionHolder.remove(beanName); }); if (ScheduledTaskRegistrar.CRON_DISABLED.equals(expression)) { log.warn("定时任务[{}]的任务表达式配置为禁用,将被不会被调度执行", taskName); return; } CronTask cronTask = new CronTask(task::poll, expression); ScheduledTask scheduledTask = taskRegistrar.scheduleCronTask(cronTask); if (scheduledTask != null) { log.info("定时任务[{}]已加载,当前任务表达式为[{}]", taskName, expression); scheduledTaskHolder.put(beanName, scheduledTask); cronExpressionHolder.put(beanName, expression); } }); } }重点是保存 ScheduledTask 对象的引用,它是控制任务启停的关键。而表达式“-”则作为一个特殊的标记,用于禁用某个定时任务。当然,禁用后的任务通过重新赋予新的 Cron 表达式,是可以“复活”的。完成了上面这些,我们还需要一个定时任务来动态监控和刷新定时任务配置:@Component public class CronTaskLoader implements ApplicationRunner { private static final Logger log = LoggerFactory.getLogger(CronTaskLoader.class); private final SchedulingConfiguration schedulingConfiguration; private final AtomicBoolean appStarted = new AtomicBoolean(false); private final AtomicBoolean initializing = new AtomicBoolean(false); public CronTaskLoader(SchedulingConfiguration schedulingConfiguration) { this.schedulingConfiguration = schedulingConfiguration; } /** * 定时任务配置刷新 */ @Scheduled(fixedDelay = 5000) public void cronTaskConfigRefresh() { if (appStarted.get() && initializing.compareAndSet(false, true)) { log.info("定时调度任务动态加载开始>>>>>>"); try { schedulingConfiguration.refresh(); } finally { initializing.set(false); } log.info("定时调度任务动态加载结束<<<<<<"); } } @Override public void run(ApplicationArguments args) { if (appStarted.compareAndSet(false, true)) { cronTaskConfigRefresh(); } } }当然,也可以把这部分代码直接整合到 SchedulingConfiguration 中,但是为了方便扩展,这里还是将执行与触发分离了。毕竟除了通过定时任务触发刷新,还可以在界面上通过按钮手动触发刷新,或者通过消息机制回调刷新。这一部分就请大家根据实际业务情况来自由发挥了。验证我们创建一个原型工程和三个简单的定时任务来验证下,第一个任务是执行周期固定的任务,假设它的Cron表达式永远不会发生变化,像这样:@Service public class CronTaskBar implements IPollableService { @Override public void poll() { System.out.println("Say Bar"); } @Override public String getCronExpression() { return "0/1 * * * * ?"; } }第二个任务是一个经常更换执行周期的任务,我们用一个随机数发生器来模拟它的善变:@Service public class CronTaskFoo implements IPollableService { private static final Random random = new SecureRandom(); @Override public void poll() { System.out.println("Say Foo"); } @Override public String getCronExpression() { return "0/" + (random.nextInt(9) + 1) + " * * * * ?"; } }第三个任务就厉害了,它仿佛就像一个电灯的开关,在启用和禁用中反复横跳:@Service public class CronTaskUnavailable implements IPollableService { private String cronExpression = "-"; private static final Map<String, String> map = new HashMap<>(); static { map.put("-", "0/1 * * * * ?"); map.put("0/1 * * * * ?", "-"); } @Override public void poll() { System.out.println("Say Unavailable"); } @Override public String getCronExpression() { return (cronExpression = map.get(cronExpression)); } }如果上面的步骤都做对了,日志里应该能看到类似这样的输出:定时调度任务动态加载开始>>>>>> 定时任务[CronTaskBar]的任务表达式未发生变化,无需刷新 定时任务[CronTaskFoo]已加载,当前任务表达式为[0/6 * * * * ?] 定时任务[CronTaskUnavailable]的任务表达式配置为禁用,将被不会被调度执行 定时调度任务动态加载结束<<<<<< Say Bar Say Bar Say Foo Say Bar Say Bar Say Bar 定时调度任务动态加载开始>>>>>> 定时任务[CronTaskBar]的任务表达式未发生变化,无需刷新 定时任务[CronTaskFoo]已加载,当前任务表达式为[0/3 * * * * ?] 定时任务[CronTaskUnavailable]已加载,当前任务表达式为[0/1 * * * * ?] 定时调度任务动态加载结束<<<<<< Say Unavailable Say Bar Say Unavailable Say Bar Say Foo Say Unavailable Say Bar Say Unavailable Say Bar Say Unavailable Say Bar小结我们在上文通过定时刷新和重建任务的方式来实现了动态更改 Cron 表达式的需求,能够满足大部分的项目场景,而且没有引入 quartzs 等额外的中间件,可以说是十分的轻量和优雅了。当然,如果各位看官有更好的方法,还请不吝赐教。
-
开源流程引擎三巨头:activiti、flowable、camunda,最推荐使用哪个? 市场上比较有名的开源流程引擎有 osworkflow、jbpm、activiti、flowable、camunda 。其中: Jbpm4、Activiti、Flowable、camunda 四个框架同宗同源,祖先都是 Jbpm4 ,开发者只要用过其中一个框架,基本上就会用其它三个。低代码平台、办公自动化(OA)、BPM平台、工作流系统均需要流程引擎功能,对于市场上如此多的开源流程引擎,哪个功能和性能好,该如何选型呢?一、主流开源流程引擎介绍1、OsworkflowOsworkflow是一个轻量化的流程引擎,基于状态机机制,数据库表很少,Osworkflow提供的工作流构成元素有:步骤(step)、条件(conditions)、循环(loops)、分支(spilts)、合并(joins)等,但不支持会签、跳转、退回、加签等这些操作,需要自己扩展开发,有一定难度,如果流程比较简单,osworkflow是很好的选择,但该开源组件已过时,长时间没有版本升级了。官方网站:http://www.opensymphony.com/osworkflow/2、JBPMJBPM由JBoss公司开发,目前最高版本JPBM7,不过从JBPM5开始已经跟之前不是同一个产品了,JBPM5的代码基础不是JBPM4,而是从Drools Flow重新开始,基于Drools Flow技术在国内市场上用的很少,所以不建议选择jBPM5以后版本。jBPM4诞生的比较早,后来JBPM4创建者Tom Baeyens离开JBoss后,加入Alfresco后很快推出了新的基于jBPM4的开源工作流系统Activiti,另外JBPM以hibernate作为数据持久化ORM也已不是主流技术,现在时间节点选择流程引擎,JBPM不是最佳选择。官方网站:https://www.jbpm.org/3、Activitiactiviti由Alfresco软件开发,目前最高版本activiti 7。activiti的版本比较复杂,有activiti5、activiti6、activiti7几个主流版本,选型时让人晕头转向,有必要先了解一下activiti这几个版本的发展历史。activiti5和activiti6的核心leader是Tijs Rademakers,由于团队内部分歧,在2017年时Tijs Rademakers离开团队,创建了后来的flowable,activiti6以及activiti5代码已经交接给了 Salaboy团队。activiti6以及activiti5的代码官方已经暂停维护了,Salaboy团队目前在开发activiti7框架,activiti7内核使用的还是activiti6,并没有为引擎注入更多的新特性,只是在activiti之外的上层封装了一些应用。结论是activiti谨慎选择。官方网站:https://www.activiti.org/4、flowableflowable基于activiti6衍生出来的版本,flowable目前最新版本是v6.6.0,开发团队是从activiti中分裂出来的,修复了一众activiti6的bug,并在其基础上研发了DMN支持,BPEL支持等等,相对开源版,其商业版的功能会更强大。以flowable6.4.1版本为分水岭,大力发展其商业版产品,开源版本维护不及时,部分功能已经不再开源版发布,比如表单生成器(表单引擎)、历史数据同步至其他数据源、ES等。 Flowable 是一个使用 Java 编写的轻量级业务流程引擎,使用 Apache V2 license 协议开源。2016 年 10 月,Activiti 工作流引擎的主要开发者离开 Alfresco 公司并在 Activiti 分支基础上开启了 Flowable 开源项目。基于 Activiti v6 beta4 发布的第一个 Flowable release 版本为6.0。Flowable 项目中包括 BPMN(Business Process Model and Notation)引擎、CMMN(Case Management Model and Notation)引擎、DMN(Decision Model and Notation)引擎、表单引擎(Form Engine)等模块。官方网站:https://flowable.com/open-source/5、CamundaCamunda基于activiti5,所以其保留了PVM,最新版本Camunda7.15,保持每年发布2个小版本的节奏,开发团队也是从activiti中分裂出来的,发展轨迹与flowable相似,同时也提供了商业版,不过对于一般企业应用,开源版本也足够了, 强烈推荐camunda流程引擎,功能和性能表现稳定。 选择camunda的理由:1)通过压力测试验证Camunda BPMN引擎性能和稳定性更好。2)功能比较完善,除了BPMN,Camunda还支持企业和社区版本中的CMMN(案例管理)和DMN(决策自动化)。Camunda不仅带有引擎,还带有非常强大的工具,用于建模,任务管理,操作监控和用户管理,所有这些都是开源的。官方网站:https://docs.camunda.org/manual/7.15/introduction/二、flowable与Camunda对比分析1、功能方面对比由于Flowable与Camunda好多功能都是类似的,因此在这里重点罗列差异化的功能camunda支持流程实例的迁移,比如同一个流程有多个实例,多个流程版本,不同流程实例运行在不同的版本中,camunda支持任意版本的实例迁移到指定的流程版本中,并可以在迁移的过程中支持从哪个节点开始。camunda基于PVM技术,所以用户从Activii5迁移到camunda基本上毫无差异。flowable没有pvm了,所以迁移工作量更大(实例的迁移,流程定义的迁移、定时器的迁移都非常麻烦)。camunda对于每一个CMD命令类都提供了权限校验机制,flowable没有。camunda继续每一个API都有批处理的影子,flowable几乎没有。比如批量挂起流程、激活流程等,使用camunda可以直接使用API操作,使用Flowable则只能自己去查询集合,然后循环遍历集合并操作。camunda很多API均支持批处理,在批量处理的时候可以指定是异步方式操作或者是同步方式操作。异步的话定时器会去执行。Flowable没有异步批处理的机制。比如批量异步删除所有的历史数据。camunda启动实例的时候支持从哪个节点开始,而不是仅仅只能从开始节点运转实例。Flowable仅仅只能从开始节点运转实例。camunda支持任意节点的跳转,可以跳转到连线也可以跳转到节点,并且在跳转的过程中支持是否触发目标节点的监听器。flowable没有改原生API需用户去扩展。camunda支持双异步机制,第一个异步即节点可以异步执行,第二个异步方式是:完成异步任务后,还可以继续异步去执行任务后面的连线。所以称之为双异步机制,flowable只有第一种异步方式。camunda支持多种脚本语言,这些脚本语言可以在连线上进行条件表达式的配置,开箱即用。比如python、ruby、groovy、JUEL。flowable仅仅支持JUEL、groovy。开箱即用的意思就是如果想用python直接引入jython包就可以用了,不需要额外配置。camunda支持外部任务,比如我们有时候想在一个节点中执行调用第三方的API或者完成一些特定的逻辑操作,就可以使用外部任务,外部任务有两种表,并支持第三方系统定期来抓取并锁定外部任务,然后执行业务完毕之后,完成外部任务,流程实例继续往下执行。外部任务的好处就是解决了分布式事物的问题。在flowable中我们可以使用httpTask任务,我个人更倾向于camunda外部任务,因为这个外部任务有外部系统决定什么时候完成,httpTask是不等待任务,实例走到这个节点之后,调用一个api就直接往下跑了,外部任务不会继续往下跑,有外部系统去决定啥时候往下跑。camunda支持为用户定制一些个性化的偏好查找API,比如张三每次查询任务的时候,一般固定点击某某三个查询条件过滤数据,使用camunda就可以将这三个查询条件进行持久化,下次张三来了,就可以直接根据他的偏好进行数据的过滤,类似机器学习。camunda支持历史数据的批量删除或者批量迁移到其他介质,比如批量迁移到es,flowable没有该机制。camunda支持在高并发部署流程的时候,是否使用锁机制,flowable没有该机制。camunda支持单引擎多组合、多引擎多库。flowable仅仅支持单引擎多组合。camunda支持流程实例跨流程定义跳转,flowable没有该机制。camunda支持分布式定时器,flowable没有该机制。flowable支持nosql,camunda只有nosql的解决方案。camunda支持优化流程,以及了解流程引擎的瓶颈所在和每个环节的耗时,flowable没有该机制。camunda修改了流程模板xml解析方式,相比flowable性能更好。camunda在解析流程模板xml的时候,去除了activiti5的双解析机制,相对而言耗时时间更短。flowable没有了pvm所以规避了双解析机制。camunda可以在任意节点添加任意的属性,flowable原生API没有,需要自己扩展。camunda框架没有为流程生成图片的API(所有流程图展示以及高亮均在前端动态计算),activiti5/6/flowable5/flowable6有图片生成以及高亮的API.camunda可以在节点中定义定时作业的优先级,也可以在流程中进行全局优先级的定义。当节点没有定义优先级的时候可以使用全局的优先级字段。activiti5/6/flowable5/flowable6没有改功能。camunda可以再流程中定义流程的tag标记,activiti5/6/flowable5/flowable6没有改功能。camunda/activiti5/6/flowable5/flowable6 均不支持国产数据库,比如人大金仓 和 达梦。flowable6支持LDAP,openLDAP,camunda不支持。activiti5不支持。2、性能方面对比笔者通过flowable和camunda多组对比测试,camunda性能比flowablet提升最小10%,最大39%,而且camunda无报错,flowable有报错,camunda在高并发场景下稳定性更好。性能测试详细文章见:https://lowcode.blog.csdn.net/article/details/109030329三、选型推荐推荐大家使用 camunda(流程引擎)+ bpmn-js(流程设计器) 组合,笔者在公司项目中经过实战验证, camunda 在功能方面比 flowable、activiti 流程引擎强大,性能和稳定性更突出。
-
SpringBoot 优雅实现超大文件上传,通用方案 前言文件上传是一个老生常谈的话题了,在文件相对比较小的情况下,可以直接把文件转化为字节流上传到服务器,但在文件比较大的情况下,用普通的方式进行上传,这可不是一个好的办法,毕竟很少有人会忍受,当文件上传到一半中断后,继续上传却只能重头开始上传,这种让人不爽的体验。那有没有比较好的上传体验呢,答案有的,就是下边要介绍的几种上传方式详细教程秒传1、什么是秒传通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。2、本文实现的秒传核心逻辑a、利用redis的set方法存放文件上传状态,其中key为文件上传的md5,value为是否上传完成的标志位,b、当标志位true为上传已经完成,此时如果有相同文件上传,则进入秒传逻辑。如果标志位为false,则说明还没上传完成,此时需要在调用set的方法,保存块号文件记录的路径,其中key为上传文件md5加一个固定前缀,value为块号文件记录路径分片上传1、什么是分片上传分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。2、分片上传的场景1、大文件上传2、网络环境环境不好,存在需要重传风险的场景断点续传1、什么是断点续传断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。本文的断点续传主要是针对断点上传场景。2、应用场景断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。3、实现断点续传的核心逻辑在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。4、实现流程步骤a、方案一,常规步骤将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;初始化一个分片上传任务,返回本次分片上传唯一标识;按照一定的策略(串行或并行)发送各个分片数据块;发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。b、方案二、本文实现的步骤前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。5、分片上传/断点上传代码实现a、前端采用百度提供的webuploader的插件,进行分片。因本文主要介绍服务端代码实现,webuploader如何进行分片,具体实现可以查看链接: http://fex.baidu.com/webuploader/getting-started.htmlb、后端用两种方式实现文件写入,一种是用RandomAccessFile,如果对RandomAccessFile不熟悉的朋友,可以查看链接: https://blog.csdn.net/dimudan2015/article/details/81910690另一种是使用MappedByteBuffer,对MappedByteBuffer不熟悉的朋友,可以查看链接进行了解: https://www.jianshu.com/p/f90866dcbffc后端进行写入操作的核心代码a、RandomAccessFile实现方式@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS) @Slf4j public class RandomAccessUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile accessTmpFile = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); accessTmpFile = new RandomAccessFile(tmpFile, "rw"); //这个必须与前端设定的值一致 long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); long offset = chunkSize * param.getChunk(); //定位到该分片的偏移量 accessTmpFile.seek(offset); //写入该分片数据 accessTmpFile.write(param.getFile().getBytes()); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessTmpFile); } return false; } } b、MappedByteBuffer实现方式@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER) @Slf4j public class MappedByteBufferUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile tempRaf = null; FileChannel fileChannel = null; MappedByteBuffer mappedByteBuffer = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); tempRaf = new RandomAccessFile(tmpFile, "rw"); fileChannel = tempRaf.getChannel(); long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); //写入该分片数据 long offset = chunkSize * param.getChunk(); byte[] fileData = param.getFile().getBytes(); mappedByteBuffer = fileChannel .map(FileChannel.MapMode.READ_WRITE, offset, fileData.length); mappedByteBuffer.put(fileData); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.freedMappedByteBuffer(mappedByteBuffer); FileUtil.close(fileChannel); FileUtil.close(tempRaf); } return false; } } c、文件操作核心模板类代码@Slf4j public abstract class SliceUploadTemplate implements SliceUploadStrategy { public abstract boolean upload(FileUploadRequestDTO param); protected File createTmpFile(FileUploadRequestDTO param) { FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class); param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath())); String fileName = param.getFile().getOriginalFilename(); String uploadDirPath = filePathUtil.getPath(param); String tempFileName = fileName + "_tmp"; File tmpDir = new File(uploadDirPath); File tmpFile = new File(uploadDirPath, tempFileName); if (!tmpDir.exists()) { tmpDir.mkdirs(); } return tmpFile; } @Override public FileUploadDTO sliceUpload(FileUploadRequestDTO param) { boolean isOk = this.upload(param); if (isOk) { File tmpFile = this.createTmpFile(param); FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile); return fileUploadDTO; } String md5 = FileMD5Util.getFileMD5(param.getFile()); Map<Integer, String> map = new HashMap<>(); map.put(param.getChunk(), md5); return FileUploadDTO.builder().chunkMd5Info(map).build(); } /** * 检查并修改文件上传进度 */ public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) { String fileName = param.getFile().getOriginalFilename(); File confFile = new File(uploadDirPath, fileName + ".conf"); byte isComplete = 0; RandomAccessFile accessConfFile = null; try { accessConfFile = new RandomAccessFile(confFile, "rw"); //把该分段标记为 true 表示完成 System.out.println("set part " + param.getChunk() + " complete"); //创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127 accessConfFile.setLength(param.getChunks()); accessConfFile.seek(param.getChunk()); accessConfFile.write(Byte.MAX_VALUE); //completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传) byte[] completeList = FileUtils.readFileToByteArray(confFile); isComplete = Byte.MAX_VALUE; for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) { //与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE isComplete = (byte) (isComplete & completeList[i]); System.out.println("check part " + i + " complete?:" + completeList[i]); } } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessConfFile); } boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete); return isOk; } /** * 把上传进度信息存进redis */ private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath, String fileName, File confFile, byte isComplete) { RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class); if (isComplete == Byte.MAX_VALUE) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true"); redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5()); confFile.delete(); return true; } else { if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false"); redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(), uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf"); } return false; } } /** * 保存文件操作 */ public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) { FileUploadDTO fileUploadDTO = null; try { fileUploadDTO = renameFile(tmpFile, fileName); if (fileUploadDTO.isUploadComplete()) { System.out .println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName); //TODO 保存文件信息到数据库 } } catch (Exception e) { log.error(e.getMessage(), e); } finally { } return fileUploadDTO; } /** * 文件重命名 * * @param toBeRenamed 将要修改名字的文件 * @param toFileNewName 新的名字 */ private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) { //检查要重命名的文件是否存在,是否是文件 FileUploadDTO fileUploadDTO = new FileUploadDTO(); if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) { log.info("File does not exist: {}", toBeRenamed.getName()); fileUploadDTO.setUploadComplete(false); return fileUploadDTO; } String ext = FileUtil.getExtension(toFileNewName); String p = toBeRenamed.getParent(); String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName; File newFile = new File(filePath); //修改文件名 boolean uploadFlag = toBeRenamed.renameTo(newFile); fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp()); fileUploadDTO.setUploadComplete(uploadFlag); fileUploadDTO.setPath(filePath); fileUploadDTO.setSize(newFile.length()); fileUploadDTO.setFileExt(ext); fileUploadDTO.setFileId(toFileNewName); return fileUploadDTO; } } 总结在实现分片上传的过程,需要前端和后端配合,比如前后端的上传块号的文件大小,前后端必须得要一致,否则上传就会有问题。其次文件相关操作正常都是要搭建一个文件服务器的,比如使用fastdfs、hdfs等。本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的md5值计算,后端写入的速度还是比较快。如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:https://help.aliyun.com/product/31815.html阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
-
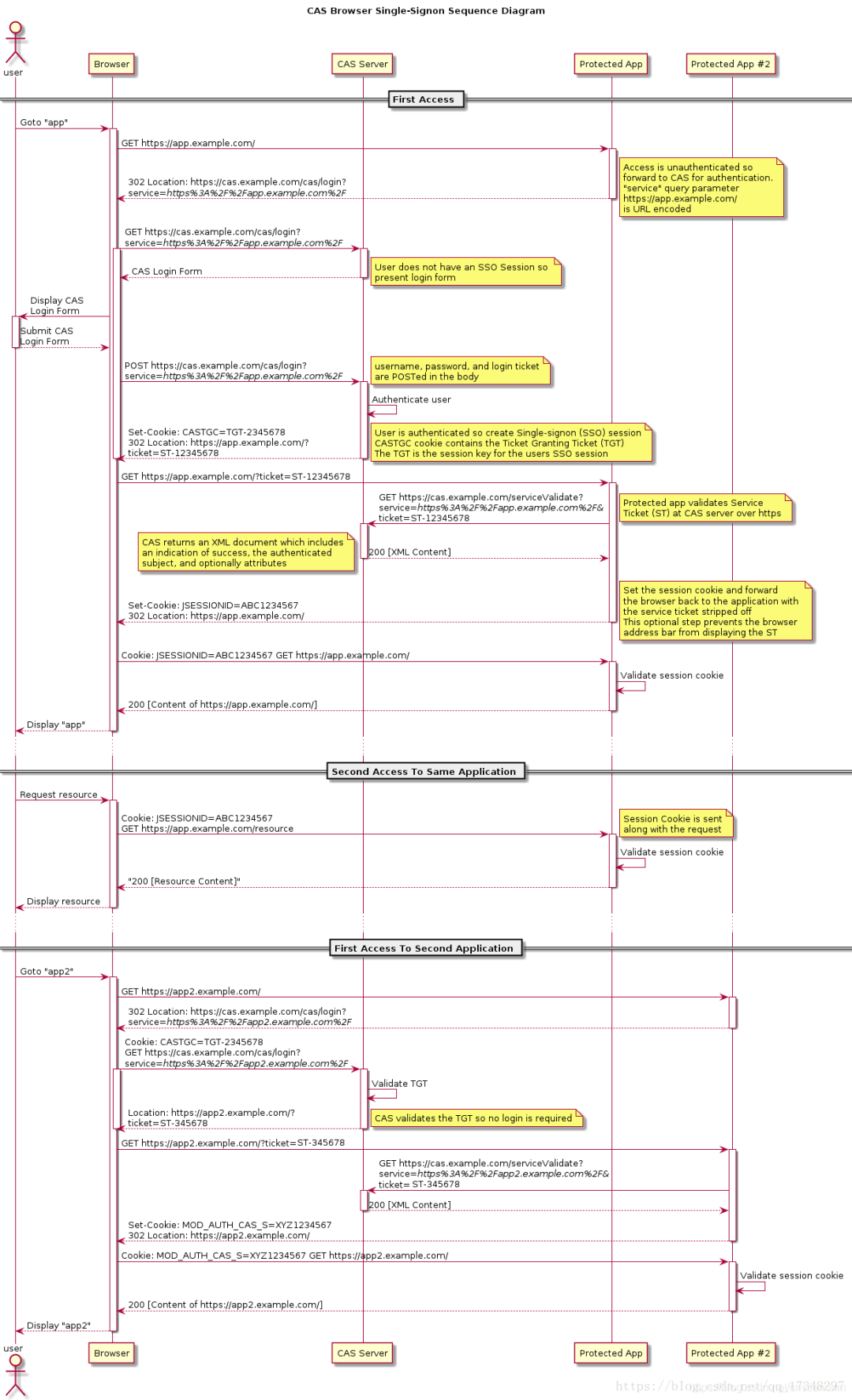
SSO 单点登录和 OAuth2.0 的区别和理解 一、概述SSO 是Single Sign On的缩写,OAuth是Open Authority的缩写,这两者都是使用令牌的方式来代替用户密码访问应用。流程上来说他们非常相似,但概念上又十分不同。SSO大家应该比较熟悉,它将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。OAuth2.0 原理可能比较陌生,但平时用的却很多,比如访问某网站想留言又不想注册时使用了微信授权。以上两者,你在业务系统中都没有账号和密码,账号密码是存放在登录中心或微信服务器中的,这就是所谓的使用令牌代替账号密码访问应用。二、SSO两者有很多相似之处,下面我们来解释一下这个过程。先来讲解SSO,通过SSO对比OAuth2.0,才比较好理解OAuth2.0的原理。SSO的实现有很多框架,比如CAS框架,以下是CAS框架的官方流程图。特别注意:SSO是一种思想,而CAS只是实现这种思想的一种框架而已上面的流程大概为:用户输入网址进入业务系统 Protected App ,系统发现用户未登录,将用户重定向到单点登录系统 CAS Server ,并带上自身地址service参数用户浏览器重定向到单点登录系统,系统检查该用户是否登录,这是SSO(这里是CAS)系统的第一个接口,该接口如果用户未登录,则将用户重定向到登录界面,如果已登录,则设置全局session,并重定向到业务系统用户填写密码后提交登录,注意此时的登录界面是SSO系统提供的,只有SSO系统保存了用户的密码,SSO系统验证密码是否正确,若正确则重定向到业务系统,并带上SSO系统的签发的ticket浏览器重定向到业务系统的登录接口,这个登录接口是不需要密码的,而是带上SSO的ticket,业务系统拿着ticket请求SSO系统,获取用户信息。并设置局部session,表示登录成功返回给浏览器 sessionId (tomcat中叫 JSESSIONID )之后所有的交互用 sessionId 与业务系统交互即可最常见的例子是,我们打开淘宝APP,首页就会有天猫、聚划算等服务的链接,当你点击以后就直接跳过去了,并没有让你再登录一次三、OAuth2.0OAuth2.0 有多种模式,这里讲的是OAuth2.0授权码模式,OAuth2.0的流程跟SSO差不多,在OAuth2中,有授权服务器、资源服务器、客户端这样几个角色,当我们用它来实现SSO的时候是不需要资源服务器这个角色的,有授权服务器和客户端就够了。授权服务器当然是用来做认证的,客户端就是各个应用系统,我们只需要登录成功后拿到用户信息以及用户所拥有的权限即可用户在某网站上点击使用微信授权,这里的某网站就类似业务系统,微信授权服务器就类似单点登录系统之后微信授权服务器返回一个确认授权页面,类似登录界面,这个页面当然是微信的而不是业务系统的用户确认授权,类似填写了账号和密码,提交后微信鉴权并返回一个ticket,并重定向业务系统。业务系统带上ticket访问微信服务器,微信服务器返回正式的token,业务系统就可以使用token获取用户信息了简介一下OAuth2.0的四种模式:授权码(authorization-code)授权码(authorization code)方式,指的是第三方应用先申请一个授权码,然后再用该码获取令牌。这种方式是最常用的流程,安全性也最高,它适用于那些有后端的 Web 应用。授权码通过前端传送,令牌则是储存在后端,而且所有与资源服务器的通信都在后端完成。这样的前后端分离,可以避免令牌泄漏。隐藏式(implicit)有些 Web 应用是纯前端应用,没有后端。这时就不能用上面的方式了,必须将令牌储存在前端。RFC 6749 就规定了第二种方式,允许直接向前端颁发令牌。这种方式没有授权码这个中间步骤,所以称为(授权码)“隐藏式”(implicit)密码式(password)如果你高度信任某个应用,RFC 6749 也允许用户把用户名和密码,直接告诉该应用。该应用就使用你的密码,申请令牌,这种方式称为"密码式"(password)。客户端凭证(client credentials)最后一种方式是凭证式(client credentials),适用于没有前端的命令行应用,即在命令行下请求令牌。简单流程四、说一下几个名词的区别首先,SSO 是一种思想,或者说是一种解决方案,是抽象的,我们要做的就是按照它的这种思想去实现它其次,OAuth2 是用来允许用户授权第三方应用访问他在另一个服务器上的资源的一种协议,它不是用来做单点登录的,但我们可以利用它来实现单点登录。在本例实现SSO的过程中,受保护的资源就是用户的信息(包括,用户的基本信息,以及用户所具有的权限),而我们想要访问这这一资源就需要用户登录并授权,OAuth2服务端负责令牌的发放等操作,这令牌的生成我们采用JWT,也就是说JWT是用来承载用户的Access_Token的最后,Spring Security、Shiro 是用于安全访问的,用来做访问权限控制。
-
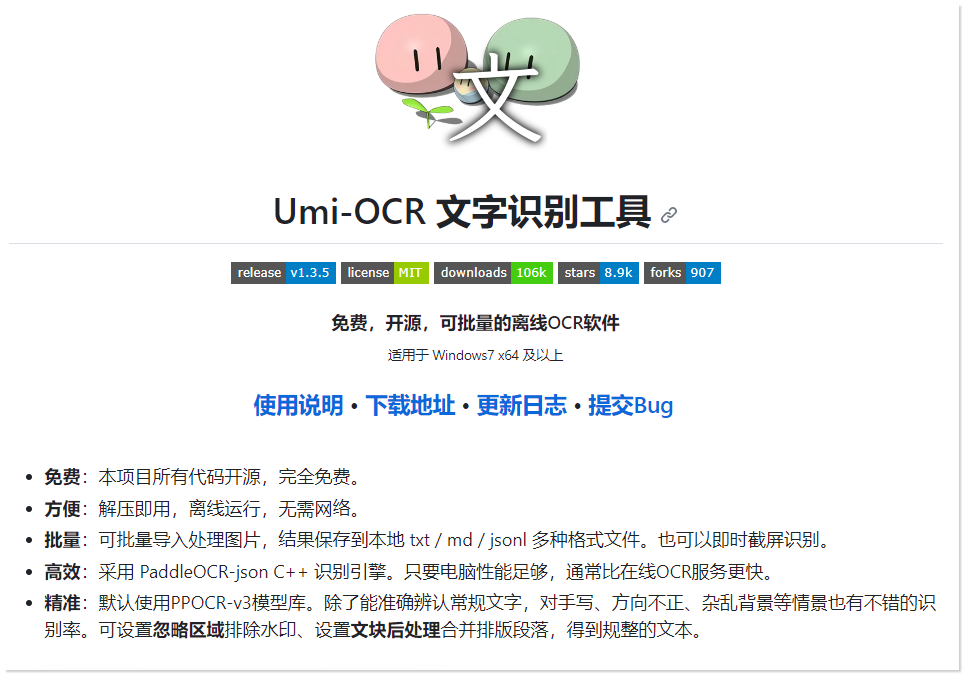
最好用的开源OCR文字识别项目,没有之一! 简介下面是项目在Github上的官方介绍。项目是基于PaddleOCR开发的,支持截图识别、批量导入识别、个性化识别等功能。整个项目都是用Python编写的,所以win7系统的朋友们可能用不了。推荐使用Win10 x64及以上版本。体验直接在releases中选择合适的版本,下载解压即可。下面就是工具的界面。接下来给大家展示一下它的亮点功能:截图识别这个功能很适合在一些不能复制的网页上使用,速度很快,准确率也很高。也就是说,你可以一次性截取所有的图片,然后再从记录板里复制所有识别出来的文字,不需要一张一张地截取和复制。批量识别如果有很多图片需要识别,这个功能非常好用。只需要将所有的图片导入,然后点击开始任务,就可以批量识别了。完成之后,识别的内容会保存在一个txt文档中。如果你不喜欢txt,需要md、jsonl 的格式,它一样可以满足你。自定义识别内容这个功能是Umi-OCR的一大亮点,可以指定识别的内容区域,或者屏蔽掉不需要识别的区域。比如说,我有三张和下图类似的图片,我只希望提取出发票号码。只需要在设置里点击打开忽略区域编辑器,将不需要的内容用红框框起来。然后点击开始任务即可。更多细节功能,可以自行去项目地址探索~GitHub地址:https://github.com/hiroi-sora/Umi-OCR
-
ElasticSearch入门篇 前言本章将介绍:ElasticSearch的作用,搭建elasticsearch的环境(Windows/Linux),ElasticSearch集群的搭建,可视化客户端插件elasticsearch-head的安装及使用,对IK分词器的安装及使用;本章介绍的ElasticSearch操作基于Restful形式(使用http请求的形式)ElasticSearch简介Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。ElasticSearch的使用案例2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”维基百科:启动以elasticsearch为基础的核心搜索架构SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据新浪使用ES 分析处理32亿条实时日志阿里使用ES 构建挖财自己的日志采集和分析体系ElasticSearch与solr的对比Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 ElasticsearchElasticSearch安装windows安装下载压缩包: ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch安装 注意:es使用java开发,使用lucene作为核心,需要配置好java环境!(jdk1.8以上)类似与tomcat,直接解压即可。其目录结构如下:修改配置文件 修改 conf\jvm.option 文件#-Xmx2g修改成为: -Xms340m -Xmx340m 否则因为虚拟机内存不够无法启动修改 conf\elasticsearch.yml 文件elasticsearch-x.x.x\config\elasticsearch.yml中末尾加入: http.cors.enabled: true http.cors.allow-origin: "*" network.host: 127.0.0.1 目的是使ES支持跨域请求启动 点击 ElasticSearch 下的 bin 目录下的 elasticsearch.bat 启动,控制台显示的日志信息如下:注意:9300 是tcp通信端口,es集群之间使用tcp进行通信,9200是http协议端口。我们在浏览器可以访问:安装图形化插件 上述可以发现, ElasticSearch 不同于 Solr 自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插件的安装。 elasticsearch-5-x 以上版本安装head需要安装node和grunt。下载 head 插件:https://github.com/mobz/elasticsearch-head 下载压缩包后解压即可。下载 node.js:https://nodejs.org/en/download/双击安装,通过 cmd 输入 node -v 查看版本号将 grunt 安装为全局命令 ,Grunt是基于Node.js的项目构建工具在 cmd 中输入:npm install ‐g grunt‐cli由于访问的是国外的服务器,如果下载速度较慢,可以切换淘宝镜像npm install -g cnpm –registry=https://registry.npm.taobao.org后续使用的时候,只需要把npm xxx 换成 cnpm xxx 即可检测是否安装成功npm config get registry注意:后续使用时需要将 npm 替换为 cnpm。启动head 进入 head 插件目录,打开 cmd ,输入:npm install grunt server打开浏览器,输入 http://localhost:9100 即可Linux安装保证你已经安装了java环境 可以直接把windows中的copy过去,不用安装,解压即可。tar -zxf elasticsearch-6.3.2.tar.gz修改配置文件 修改 conf\jvm.option 文件#-Xmx2g修改成为: -Xms340m -Xmx340m 否则因为虚拟机内存不够无法启动修改 conf\elasticsearch.yml 文件#elasticsearch-5.6.8\config\elasticsearch.yml中末尾加入: http.cors.enabled: true http.cors.allow-origin: "*" network.host: 127.0.0.1 目的是使ES支持跨域请求启动 注意:在linux环境下不支持root用户直接启动(理由是安全问题)添加用户:[root@coderxz bin]# useradd rxz -p rongxianzhao [root@coderxz bin]# chown -R rxz:rxz /usr/local/elasticsearch/* [root@coderxz bin]# su rxz执行:#注意:切换为非root用户执行哦 [rxz@coderxz bin]$ ./elasticsearch查看运行状态:[root@coderxz ~]# ps aux|grep elasticsearch [root@coderxz ~]# curl -X GET 'http://localhost:9200'配置外网访问 9200 端口 需要开放服务器的端口修改配置文件:config/elasticsearch.yml network.host: 0.0.0.0后台启动如果你在服务器上安装Elasticsearch,而你想在本地机器上进行开发,这时候,你很可能需要在关闭终端的时候,让Elasticsearch继续保持运行。最简单的方法就是使用nohup。先按Ctrl + C,停止当前运行的Elasticsearch,改用下面的命令运行Elasticsearch。nohup ./bin/elasticsearch &ES相关概念概述(重要)Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。Elasticsearch比传统关系型数据库如下:Relational DB ‐> Databases ‐> Tables ‐> Rows ‐> ColumnsElasticsearch ‐> Indices ‐> Types ‐> Documents ‐> Fields核心概念index索引 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。可类比mysql中的数据库type类型 在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。可类比mysql中的表Filed字段 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识 。映射mapping mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。相当于mysql中的创建表的过程,设置主键外键等等document文档 一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。 插入索引库以文档为单位,类比与数据库中的一行数据集群cluster 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由 一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集 群的名字,来加入这个集群。节点node 一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一 个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的 时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对 应于Elasticsearch集群中的哪些节点。一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫 做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此, 它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点, 这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。分片和复制 shards&replicas 一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因: 1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。ElasticSearch客户端操作上述部分为理论部分,实际开发中,主要有三种方式可以作为es服务的客户端:使用elasticsearch-head插件使用elasticsearch提供的Restful接口直接访问使用elasticsearch提供的API进行访问使用Restful接口直接访问我们需要使用http请求,介绍两款接口测试工具: postman 和 Talend API tester 。Talend API tester安装: 这是一款chrome插件,无需下载。Postman安装: Postman官网:https://www.getpostman.com使用Talend API tester进行es客户端操作。Elasticsearch的接口语法curl ‐X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' ‐d '<BODY>'其中:创建索引库index并添加映射mapping------PUT 请求体:article:type类型;相当于这个索引库中有张表叫做article下面定义的这张表中的字段的定义,字段默认为不索引的;analyzer:分词器使用标准分词器{ "mappings": { "article": { "properties": { "id": { "type": "long", "store": true, "index": "not_analyzed" }, "title": { "type": "text", "store": true, "index": "analyzed", "analyzer": "standard" }, "content": { "type": "text", "store": true, "index": "analyzed", "analyzer": "standard" } } } } }在可视化工具elasticsearch-head中查看:先创建索引index,再添加mapping ----PUT 我们可以在创建索引时设置mapping信息,当然也可以先创建索引然后再设置mapping。在上一个步骤中不设置maping信息,直接使用put方法创建一个索引,然后设置mapping信息。请求的url:PUT http://127.0.0.1:9200/hello2/article/_mapping请求体:{ "article": { "properties": { "id": { "type": "long", "store": true, "index": "not_analyzed" }, "title": { "type": "text", "store": true, "index": "analyzed", "analyzer": "standard" }, "content": { "type": "text", "store": true, "index": "analyzed", "analyzer": "standard" } } } }删除索引index ----DELETE 请求URL:DELETE http://127.0.0.1:9200/hello2创建文档document(向索引库中添加内容)---POST 请求URL:POST http://127.0.0.1:9200/hello/article/1请求体:{ "id": 1, "title": "ElasticSearch是一个基于Lucene的搜索服务器", "content": "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。" }在elasticsearch-head中查看:注意,一般我们将_id与id赋相同值。修改document内容----POST 请求URL:POST http://127.0.0.1:9200/hello/article/1在elasticsearch-head中查看:删除文档document---DELETE 请求URL:DELETE http://127.0.0.1:9200/hello/article/2查询文档document-----GET 查询文档有三种方式:根据id查询;根据关键词查询根据输入的内容先分词,再查询i.根据id查询请求URL:GET http://127.0.0.1:9200/hello/article/1ii.根据关键字查询-term查询请求URL:POST http://127.0.0.1:9200/hello/article/_search请求体:{ "query": { "term": { "title": "搜" } } }iii.查询文档-querystring查询请求URL:POST http://127.0.0.1:9200/hello/article/_search请求体:{ "query": { "query_string": { "default_field": "title", "query": "搜索服务器" } } }指定:在哪个字段上进行查询;要查询的内容是什么;它会把查询内容先进行分词,再进行查询使用elasticsearch-head进行es客户端操作在elasticsearch-head中集成了http请求的工具,可以提供复查查询:IK分词器和Elasticsearch集成使用上述分词器使用的是标准分词器,其对中文分词不是很友好,例如对我是程序员进行分词得到:GET http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=我是程序员"tokens":[ {"token": "我", "start_offset": 0, "end_offset": 1, "type": "<IDEOGRAPHIC>",…}, {"token": "是", "start_offset": 1, "end_offset": 2, "type": "<IDEOGRAPHIC>",…}, {"token": "程", "start_offset": 2, "end_offset": 3, "type": "<IDEOGRAPHIC>",…}, {"token": "序", "start_offset": 3, "end_offset": 4, "type": "<IDEOGRAPHIC>",…}, {"token": "员", "start_offset": 4, "end_offset": 5, "type": "<IDEOGRAPHIC>",…} ]我们希望达到的分词是:我、是、程序、程序员。支持中文的分词器有很多,word分词器,庖丁解牛,Ansj分词器,下面注意说IK分词器的使用。IK分词器的安装1)下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases2)解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik (其他名字也可以,目的是不要重名)3)重新启动ElasticSearch,即可加载IK分词器IK分词器测试IK提供两种分词ik_smart和ik_max_word其中ik_smart为最少切分,ik_max_word为最细粒度划分。下面测试一下:最小切分:在浏览器输入地址:GET http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员返回结果:"tokens":[ {"token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR",…}, {"token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR",…}, {"token": "程序员", "start_offset": 2, "end_offset": 5, "type": "CN_WORD",…} ]最新切分:在浏览器输入地址:GET http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员返回结果:"tokens":[ {"token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR",…}, {"token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR",…}, {"token": "程序员", "start_offset": 2, "end_offset": 5, "type": "CN_WORD",…}, {"token": "程序", "start_offset": 2, "end_offset": 4, "type": "CN_WORD",…}, {"token": "员", "start_offset": 4, "end_offset": 5, "type": "CN_CHAR",…} ]ElasticSearch集群ES集群是一个 P2P类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在 Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了相同 cluster.name 的节点都自动归属到一个集群中。2.0 版本之后,基于安全的考虑避免开发环境过于随便造成的麻烦,从 2.0 版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES 将其视作gossip router 角色,借以完成集群的发现。由于这只是 ES 内一个很小的功能,所以 gossip router 角色并不需要单独配置,每个 ES 节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为 router即可。集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了。一般处于高性能及高可用方面来考虑,一般集群中的节点数量都是3个及3个以上 .集群的搭建Windows 准备三台elasticsearch服务器: 修改每台服务器的配置 修改 \comf\elasticsearch.yml 配置文件:#Node节点1: http.cors.enabled: true http.cors.allow-origin: "*" #节点1的配置信息: #集群名称,保证唯一 cluster.name: my-elasticsearch #节点名称,必须不一样 node.name: node-1 #必须为本机的ip地址 network.host: 127.0.0.1 #服务端口号,在同一机器下必须不一样 http.port: 9201 #集群间通信端口号,在同一机器下必须不一样 transport.tcp.port: 9301 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"] #Node节点2: http.cors.enabled: true http.cors.allow-origin: "*" #节点1的配置信息: #集群名称,保证唯一 cluster.name: my-elasticsearch #节点名称,必须不一样 node.name: node-2 #必须为本机的ip地址 network.host: 127.0.0.1 #服务端口号,在同一机器下必须不一样 http.port: 9202 #集群间通信端口号,在同一机器下必须不一样 transport.tcp.port: 9302 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"] #Node节点3: http.cors.enabled: true http.cors.allow-origin: "*" #节点1的配置信息: #集群名称,保证唯一 cluster.name: my-elasticsearch #节点名称,必须不一样 node.name: node-3 #必须为本机的ip地址 network.host: 127.0.0.1 #服务端口号,在同一机器下必须不一样 http.port: 9203 #集群间通信端口号,在同一机器下必须不一样 transport.tcp.port: 9303 #设置集群自动发现机器ip集合 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]启动各个节点服务器 可以分别启动每个服务器下的 elasticsearch.bat ,我这里使用的是 windows 下的批处理文件:新建一个 elasticsearch_cluster_start.bat 文件,然后添加下面内容:格式为:start "需要启动的文件名" "文件的路径" &表示启动A后继续执行。start "elasticsearch.bat" "F:\Soft\ES-cluster\cluster01\bin\elasticsearch.bat" & start "elasticsearch.bat" "F:\Soft\ES-cluster\cluster02\bin\elasticsearch.bat" & start "elasticsearch.bat" "F:\Soft\ES-cluster\cluster03\bin\elasticsearch.bat" 关于Windows的批处理在本章就不细说了。集群测试 只要连接集群中的任意节点,其操作方式与单机版本基本相同,改变的仅仅是存储的结构。添加索引和映射PUT http://127.0.0.1:9201/hello请求体:{ "mappings": { "article": { "properties": { "id": { "type": "long", "store": true, "index": "not_analyzed" }, "title": { "type": "text", "store": true, "index": true, "analyzer": "ik_smart" }, "content": { "type": "text", "store": true, "index": true, "analyzer": "ik_smart" } } } } }返回结果:{ "acknowledged": true, "shards_acknowledged": true, "index": "hello" }添加文档POST http://127.0.0.1:9201/hello/article/1请求体:{ "id":1, "title":"ElasticSearch是一个基于Lucene的搜索服务器", "content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。" }返回值:{ "_index": "hello", "_type": "article", "_id": "1", "_version": 1, "result": "created", "_shards":{ "total": 2, "successful": 2, "failed": 0 }, "created": true }在elasticsearch-head中查看:
-
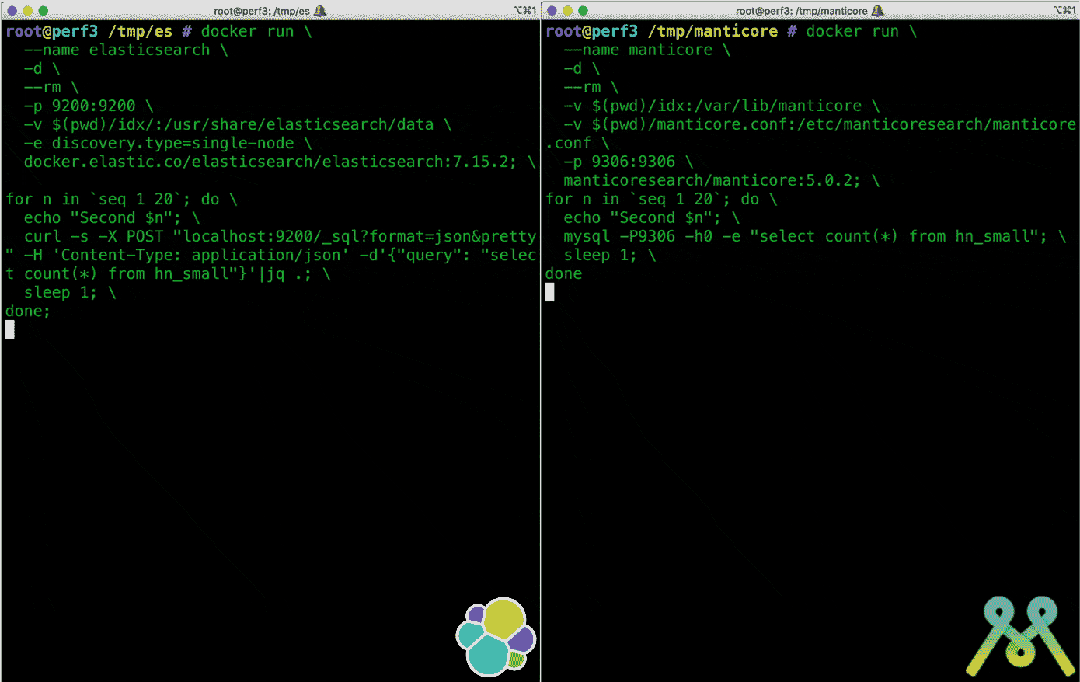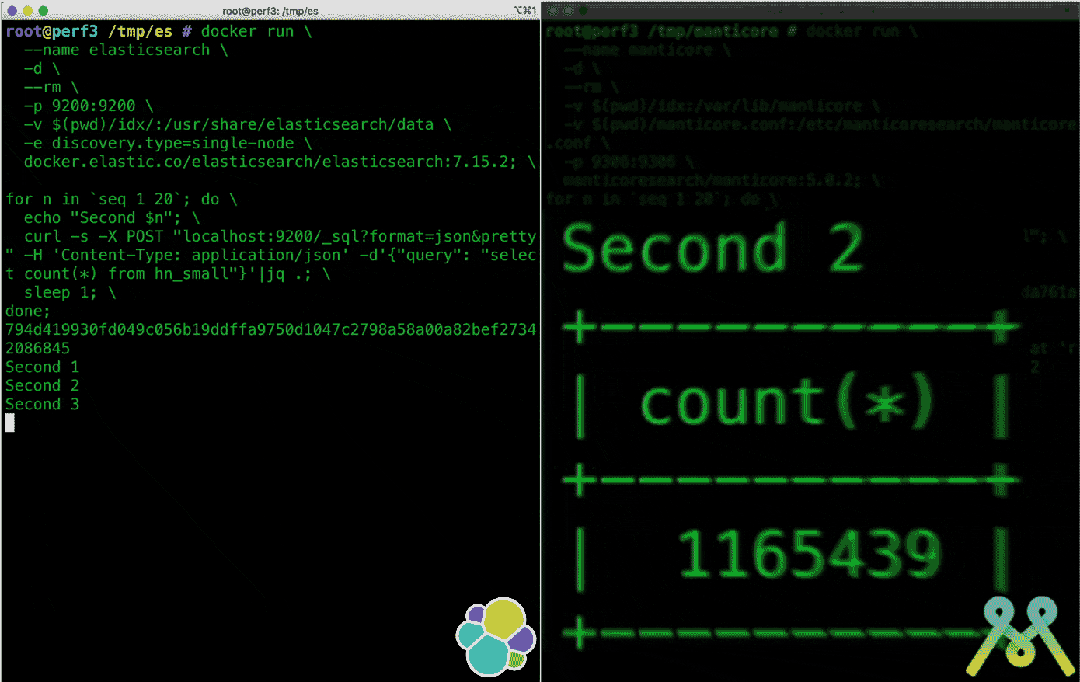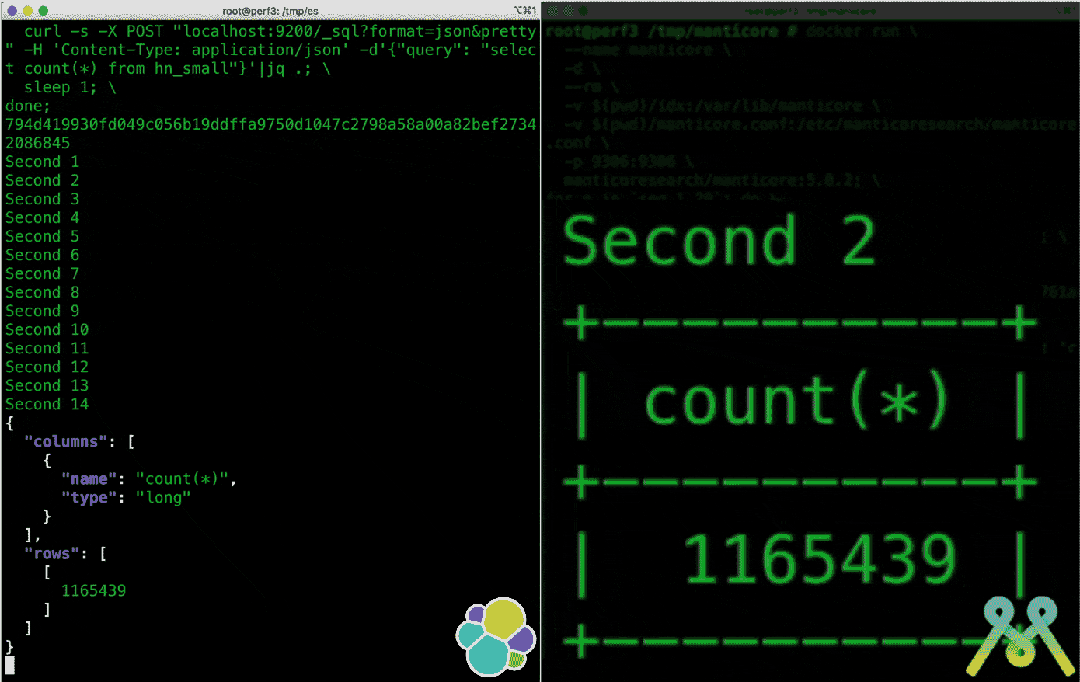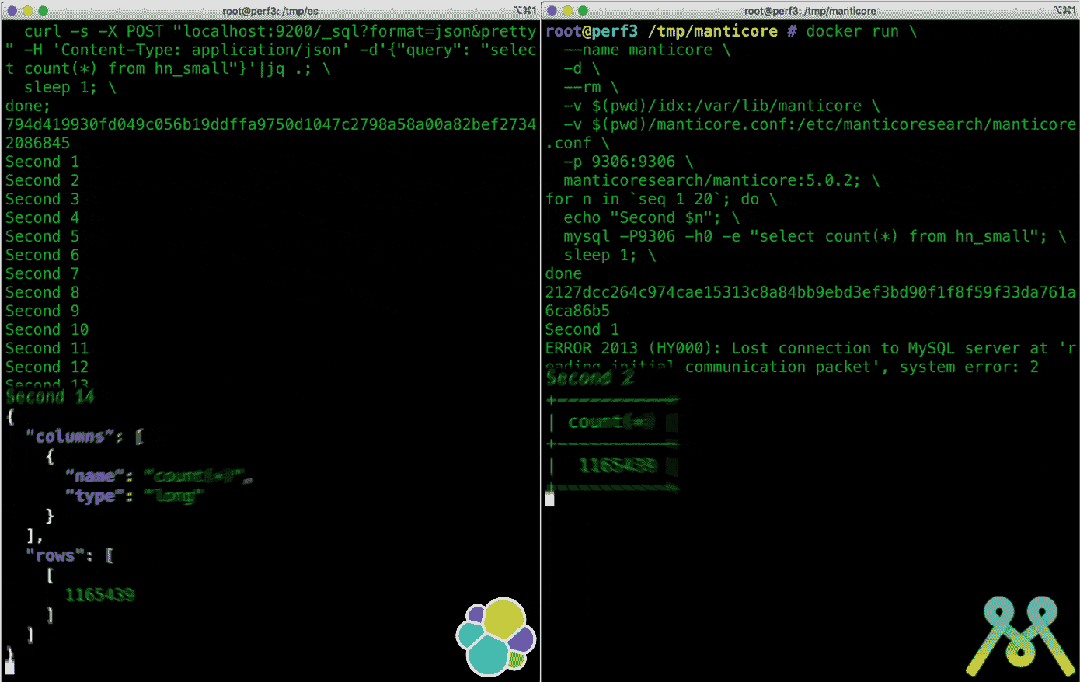
号称取代 Elasticsearch,太猛了! 10倍 提升效率,号称取代 Elasticsearch 的轻量级搜索引擎到底有多强悍?# Manticore Search介绍 Manticore Search 是一个使用 C++ 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码并保持开源。这一切使 Manticore Search 成为一个现代,快速,轻量级和功能齐全的数据库,具有出色的全文搜索功能。Manticore Search目前在GitHub收获3.7k star,拥有大批忠实用户。同时开源者在GitHub介绍中明确说明了该项目是是Elasticsearch的良好替代品,在不久的将来就会取代ELK中的E。同时,来自 MS 官方的测试表明 Manticore Search 性能比 ElasticSearch 有质的提升:在一定的场景中,Manticore 比 Elasticsearch 快 15 倍!完整的测评结果,可以参考:https://manticoresearch.com/blog/manticore-alternative-to-elasticsearch/优势 它与其他解决方案的区别在于:它非常快,因此比其他替代方案更具成本效益。例如,Manticore:对于小型数据,比MySQL快182倍(可重现)对于日志分析,比Elasticsearch快29倍(可重现)对于小型数据集,比Elasticsearch快15倍(可重现)对于中等大小的数据,比Elasticsearch快5倍(可重现)对于大型数据,比Elasticsearch快4倍(可重现)在单个服务器上进行数据导入时,最大吞吐量比Elasticsearch快最多2倍(可重现)由于其现代的多线程架构和高效的查询并行化能力,Manticore能够充分利用所有CPU核心,以实现最快的响应时间。强大而快速的全文搜索功能能够无缝地处理小型和大型数据集。针对小、中、大型数据集提供逐行存储。对于更大的数据集,Manticore通过Manticore Columnar Library提供列存储支持,可以处理无法适合内存的数据集。自动创建高效的二级索引,节省时间和精力。成本优化的查询优化器可优化搜索查询以实现最佳性能。Manticore是基于SQL的,使用SQL作为其本机语法,并与MySQL协议兼容,使您可以使用首选的MySQL客户端。通过PHP、Python、JavaScript、Java、Elixir和Go等客户端,与Manticore Search的集成变得简单。Manticore还提供了一种编程HTTP JSON协议,用于更多样化的数据和模式管理。Manticore Search使用C++构建,启动快速,内存使用最少,低级别优化有助于其卓越性能。实时插入,新添加的文档立即可访问。提供互动课程,使学习轻松愉快。Manticore还拥有内置的复制和负载均衡功能,增加了可靠性。可以轻松地从MySQL、PostgreSQL、ODBC、xml和csv等来源同步数据。 - 虽然不完全符合ACID,但Manticore仍支持事务和binlog以确保安全写入。内置工具和SQL命令可轻松备份和恢复数据。Craigslist、Socialgist、PubChem、Rozetka和许多其他公司使用 Manticore 进行高效搜索和流过滤。# 使用 具体的安装方法:https://manticoresearch.com/install/Docker镜像可在Docker Hub上获取:https://hub.docker.com/r/manticoresearch/manticore/要在 Docker 中试验 Manticore Search,只需运行:docker run -e EXTRA=1 --name manticore --rm -d manticoresearch/manticore && until docker logs manticore 2>&1 | grep -q "accepting connections"; do sleep 1; done && docker exec -it manticore mysql && docker stop manticore 之后,可以进行其他操作,例如创建表、添加数据并运行搜索: create table movies(title text, year int) morphology='stem_en' html_strip='1' stopwords='en'; insert into movies(title, year) values ('The Seven Samurai', 1954), ('Bonnie and Clyde', 1954), ('Reservoir Dogs', 1992), ('Airplane!', 1980), ('Raging Bull', 1980), ('Groundhog Day', 1993), ('<a href="http://google.com/">Jurassic Park</a>', 1993), ('Ferris Bueller\'s Day Off', 1986); select highlight(), year from movies where match('the dog'); select highlight(), year from movies where match('days') facet year; select * from movies where match('google');完整文档和开源代码,可以移步:https://github.com/manticoresoftware/manticoresearch