搜索到
30
篇与
的结果
-
 动态更改 Spring 定时任务 Cron 表达式 在 SpringBoot 项目中,我们可以通过 @EnableScheduling 注解开启调度任务支持,并通过 @Scheduled 注解快速地建立一系列定时任务。@Scheduled 支持下面三种配置执行时间的方式:cron(expression):根据Cron表达式来执行。fixedDelay(period):固定间隔时间执行,无论任务执行长短,两次任务执行的间隔总是相同的。fixedRate(period):固定频率执行,从任务启动之后,总是在固定的时刻执行,如果因为执行时间过长,造成错过某个时刻的执行(晚点),则任务会被立刻执行。最常用的应该是第一种方式,基于Cron表达式的执行模式,因其相对来说更加灵活。可变与不可变默认情况下,@Scheduled 注解标记的定时任务方法在初始化之后,是不会再发生变化的。 Spring 在初始化 bean 后,通过后处理器拦截所有带有 @Scheduled 注解的方法,并解析相应的的注解参数,放入相应的定时任务列表等待后续统一执行处理。到定时任务真正启动之前,我们都有机会更改任务的执行周期等参数。换言之,我们既可以通过 application.properties 配置文件配合 @Value 注解的方式指定任务的 Cron 表达式,亦可以通过 CronTrigger 从数据库或者其他任意存储中间件中加载并注册定时任务。这是 Spring 提供给我们的可变的部分。但是我们往往要得更多。能否在定时任务已经在执行过的情况下,去动态更改 Cron 表达式,甚至禁用某个定时任务呢?很遗憾,默认情况下,这是做不到的,任务一旦被注册和执行,用于注册的参数便被固定下来,这是不可变的部分。创造与毁灭既然创造之后不可变,那就毁灭之后再重建吧。于是乎,我们的思路便是,在注册期间保留任务的关键信息,并通过另一个定时任务检查配置是否发生变化,如果有变化,就把“前任”干掉,取而代之。如果没有变化,就保持原样。先对任务做个简单的抽象,方便统一的识别和管理:public interface IPollableService { /** * 执行方法 */ void poll(); /** * 获取周期表达式 * * @return CronExpression */ default String getCronExpression() { return null; } /** * 获取任务名称 * * @return 任务名称 */ default String getTaskName() { return this.getClass().getSimpleName(); } }最重要的便是 getCronExpression() 方法,每个定时服务实现可以自己控制自己的表达式,变与不变,自己说了算。至于从何处获取,怎么获取,请诸君自行发挥了。接下来,就是实现任务的动态注册:@Configuration @EnableAsync @EnableScheduling public class SchedulingConfiguration implements SchedulingConfigurer, ApplicationContextAware { private static final Logger log = LoggerFactory.getLogger(SchedulingConfiguration.class); private static ApplicationContext appCtx; private final ConcurrentMap<String, ScheduledTask> scheduledTaskHolder = new ConcurrentHashMap<>(16); private final ConcurrentMap<String, String> cronExpressionHolder = new ConcurrentHashMap<>(16); private ScheduledTaskRegistrar taskRegistrar; public static synchronized void setAppCtx(ApplicationContext appCtx) { SchedulingConfiguration.appCtx = appCtx; } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { setAppCtx(applicationContext); } @Override public void configureTasks(ScheduledTaskRegistrar taskRegistrar) { this.taskRegistrar = taskRegistrar; } /** * 刷新定时任务表达式 */ public void refresh() { Map<String, IPollableService> beanMap = appCtx.getBeansOfType(IPollableService.class); if (beanMap.isEmpty() || taskRegistrar == null) { return; } beanMap.forEach((beanName, task) -> { String expression = task.getCronExpression(); String taskName = task.getTaskName(); if (null == expression) { log.warn("定时任务[{}]的任务表达式未配置或配置错误,请检查配置", taskName); return; } // 如果策略执行时间发生了变化,则取消当前策略的任务,并重新注册任务 boolean unmodified = scheduledTaskHolder.containsKey(beanName) && cronExpressionHolder.get(beanName).equals(expression); if (unmodified) { log.info("定时任务[{}]的任务表达式未发生变化,无需刷新", taskName); return; } Optional.ofNullable(scheduledTaskHolder.remove(beanName)).ifPresent(existTask -> { existTask.cancel(); cronExpressionHolder.remove(beanName); }); if (ScheduledTaskRegistrar.CRON_DISABLED.equals(expression)) { log.warn("定时任务[{}]的任务表达式配置为禁用,将被不会被调度执行", taskName); return; } CronTask cronTask = new CronTask(task::poll, expression); ScheduledTask scheduledTask = taskRegistrar.scheduleCronTask(cronTask); if (scheduledTask != null) { log.info("定时任务[{}]已加载,当前任务表达式为[{}]", taskName, expression); scheduledTaskHolder.put(beanName, scheduledTask); cronExpressionHolder.put(beanName, expression); } }); } }重点是保存 ScheduledTask 对象的引用,它是控制任务启停的关键。而表达式“-”则作为一个特殊的标记,用于禁用某个定时任务。当然,禁用后的任务通过重新赋予新的 Cron 表达式,是可以“复活”的。完成了上面这些,我们还需要一个定时任务来动态监控和刷新定时任务配置:@Component public class CronTaskLoader implements ApplicationRunner { private static final Logger log = LoggerFactory.getLogger(CronTaskLoader.class); private final SchedulingConfiguration schedulingConfiguration; private final AtomicBoolean appStarted = new AtomicBoolean(false); private final AtomicBoolean initializing = new AtomicBoolean(false); public CronTaskLoader(SchedulingConfiguration schedulingConfiguration) { this.schedulingConfiguration = schedulingConfiguration; } /** * 定时任务配置刷新 */ @Scheduled(fixedDelay = 5000) public void cronTaskConfigRefresh() { if (appStarted.get() && initializing.compareAndSet(false, true)) { log.info("定时调度任务动态加载开始>>>>>>"); try { schedulingConfiguration.refresh(); } finally { initializing.set(false); } log.info("定时调度任务动态加载结束<<<<<<"); } } @Override public void run(ApplicationArguments args) { if (appStarted.compareAndSet(false, true)) { cronTaskConfigRefresh(); } } }当然,也可以把这部分代码直接整合到 SchedulingConfiguration 中,但是为了方便扩展,这里还是将执行与触发分离了。毕竟除了通过定时任务触发刷新,还可以在界面上通过按钮手动触发刷新,或者通过消息机制回调刷新。这一部分就请大家根据实际业务情况来自由发挥了。验证我们创建一个原型工程和三个简单的定时任务来验证下,第一个任务是执行周期固定的任务,假设它的Cron表达式永远不会发生变化,像这样:@Service public class CronTaskBar implements IPollableService { @Override public void poll() { System.out.println("Say Bar"); } @Override public String getCronExpression() { return "0/1 * * * * ?"; } }第二个任务是一个经常更换执行周期的任务,我们用一个随机数发生器来模拟它的善变:@Service public class CronTaskFoo implements IPollableService { private static final Random random = new SecureRandom(); @Override public void poll() { System.out.println("Say Foo"); } @Override public String getCronExpression() { return "0/" + (random.nextInt(9) + 1) + " * * * * ?"; } }第三个任务就厉害了,它仿佛就像一个电灯的开关,在启用和禁用中反复横跳:@Service public class CronTaskUnavailable implements IPollableService { private String cronExpression = "-"; private static final Map<String, String> map = new HashMap<>(); static { map.put("-", "0/1 * * * * ?"); map.put("0/1 * * * * ?", "-"); } @Override public void poll() { System.out.println("Say Unavailable"); } @Override public String getCronExpression() { return (cronExpression = map.get(cronExpression)); } }如果上面的步骤都做对了,日志里应该能看到类似这样的输出:定时调度任务动态加载开始>>>>>> 定时任务[CronTaskBar]的任务表达式未发生变化,无需刷新 定时任务[CronTaskFoo]已加载,当前任务表达式为[0/6 * * * * ?] 定时任务[CronTaskUnavailable]的任务表达式配置为禁用,将被不会被调度执行 定时调度任务动态加载结束<<<<<< Say Bar Say Bar Say Foo Say Bar Say Bar Say Bar 定时调度任务动态加载开始>>>>>> 定时任务[CronTaskBar]的任务表达式未发生变化,无需刷新 定时任务[CronTaskFoo]已加载,当前任务表达式为[0/3 * * * * ?] 定时任务[CronTaskUnavailable]已加载,当前任务表达式为[0/1 * * * * ?] 定时调度任务动态加载结束<<<<<< Say Unavailable Say Bar Say Unavailable Say Bar Say Foo Say Unavailable Say Bar Say Unavailable Say Bar Say Unavailable Say Bar小结我们在上文通过定时刷新和重建任务的方式来实现了动态更改 Cron 表达式的需求,能够满足大部分的项目场景,而且没有引入 quartzs 等额外的中间件,可以说是十分的轻量和优雅了。当然,如果各位看官有更好的方法,还请不吝赐教。
动态更改 Spring 定时任务 Cron 表达式 在 SpringBoot 项目中,我们可以通过 @EnableScheduling 注解开启调度任务支持,并通过 @Scheduled 注解快速地建立一系列定时任务。@Scheduled 支持下面三种配置执行时间的方式:cron(expression):根据Cron表达式来执行。fixedDelay(period):固定间隔时间执行,无论任务执行长短,两次任务执行的间隔总是相同的。fixedRate(period):固定频率执行,从任务启动之后,总是在固定的时刻执行,如果因为执行时间过长,造成错过某个时刻的执行(晚点),则任务会被立刻执行。最常用的应该是第一种方式,基于Cron表达式的执行模式,因其相对来说更加灵活。可变与不可变默认情况下,@Scheduled 注解标记的定时任务方法在初始化之后,是不会再发生变化的。 Spring 在初始化 bean 后,通过后处理器拦截所有带有 @Scheduled 注解的方法,并解析相应的的注解参数,放入相应的定时任务列表等待后续统一执行处理。到定时任务真正启动之前,我们都有机会更改任务的执行周期等参数。换言之,我们既可以通过 application.properties 配置文件配合 @Value 注解的方式指定任务的 Cron 表达式,亦可以通过 CronTrigger 从数据库或者其他任意存储中间件中加载并注册定时任务。这是 Spring 提供给我们的可变的部分。但是我们往往要得更多。能否在定时任务已经在执行过的情况下,去动态更改 Cron 表达式,甚至禁用某个定时任务呢?很遗憾,默认情况下,这是做不到的,任务一旦被注册和执行,用于注册的参数便被固定下来,这是不可变的部分。创造与毁灭既然创造之后不可变,那就毁灭之后再重建吧。于是乎,我们的思路便是,在注册期间保留任务的关键信息,并通过另一个定时任务检查配置是否发生变化,如果有变化,就把“前任”干掉,取而代之。如果没有变化,就保持原样。先对任务做个简单的抽象,方便统一的识别和管理:public interface IPollableService { /** * 执行方法 */ void poll(); /** * 获取周期表达式 * * @return CronExpression */ default String getCronExpression() { return null; } /** * 获取任务名称 * * @return 任务名称 */ default String getTaskName() { return this.getClass().getSimpleName(); } }最重要的便是 getCronExpression() 方法,每个定时服务实现可以自己控制自己的表达式,变与不变,自己说了算。至于从何处获取,怎么获取,请诸君自行发挥了。接下来,就是实现任务的动态注册:@Configuration @EnableAsync @EnableScheduling public class SchedulingConfiguration implements SchedulingConfigurer, ApplicationContextAware { private static final Logger log = LoggerFactory.getLogger(SchedulingConfiguration.class); private static ApplicationContext appCtx; private final ConcurrentMap<String, ScheduledTask> scheduledTaskHolder = new ConcurrentHashMap<>(16); private final ConcurrentMap<String, String> cronExpressionHolder = new ConcurrentHashMap<>(16); private ScheduledTaskRegistrar taskRegistrar; public static synchronized void setAppCtx(ApplicationContext appCtx) { SchedulingConfiguration.appCtx = appCtx; } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { setAppCtx(applicationContext); } @Override public void configureTasks(ScheduledTaskRegistrar taskRegistrar) { this.taskRegistrar = taskRegistrar; } /** * 刷新定时任务表达式 */ public void refresh() { Map<String, IPollableService> beanMap = appCtx.getBeansOfType(IPollableService.class); if (beanMap.isEmpty() || taskRegistrar == null) { return; } beanMap.forEach((beanName, task) -> { String expression = task.getCronExpression(); String taskName = task.getTaskName(); if (null == expression) { log.warn("定时任务[{}]的任务表达式未配置或配置错误,请检查配置", taskName); return; } // 如果策略执行时间发生了变化,则取消当前策略的任务,并重新注册任务 boolean unmodified = scheduledTaskHolder.containsKey(beanName) && cronExpressionHolder.get(beanName).equals(expression); if (unmodified) { log.info("定时任务[{}]的任务表达式未发生变化,无需刷新", taskName); return; } Optional.ofNullable(scheduledTaskHolder.remove(beanName)).ifPresent(existTask -> { existTask.cancel(); cronExpressionHolder.remove(beanName); }); if (ScheduledTaskRegistrar.CRON_DISABLED.equals(expression)) { log.warn("定时任务[{}]的任务表达式配置为禁用,将被不会被调度执行", taskName); return; } CronTask cronTask = new CronTask(task::poll, expression); ScheduledTask scheduledTask = taskRegistrar.scheduleCronTask(cronTask); if (scheduledTask != null) { log.info("定时任务[{}]已加载,当前任务表达式为[{}]", taskName, expression); scheduledTaskHolder.put(beanName, scheduledTask); cronExpressionHolder.put(beanName, expression); } }); } }重点是保存 ScheduledTask 对象的引用,它是控制任务启停的关键。而表达式“-”则作为一个特殊的标记,用于禁用某个定时任务。当然,禁用后的任务通过重新赋予新的 Cron 表达式,是可以“复活”的。完成了上面这些,我们还需要一个定时任务来动态监控和刷新定时任务配置:@Component public class CronTaskLoader implements ApplicationRunner { private static final Logger log = LoggerFactory.getLogger(CronTaskLoader.class); private final SchedulingConfiguration schedulingConfiguration; private final AtomicBoolean appStarted = new AtomicBoolean(false); private final AtomicBoolean initializing = new AtomicBoolean(false); public CronTaskLoader(SchedulingConfiguration schedulingConfiguration) { this.schedulingConfiguration = schedulingConfiguration; } /** * 定时任务配置刷新 */ @Scheduled(fixedDelay = 5000) public void cronTaskConfigRefresh() { if (appStarted.get() && initializing.compareAndSet(false, true)) { log.info("定时调度任务动态加载开始>>>>>>"); try { schedulingConfiguration.refresh(); } finally { initializing.set(false); } log.info("定时调度任务动态加载结束<<<<<<"); } } @Override public void run(ApplicationArguments args) { if (appStarted.compareAndSet(false, true)) { cronTaskConfigRefresh(); } } }当然,也可以把这部分代码直接整合到 SchedulingConfiguration 中,但是为了方便扩展,这里还是将执行与触发分离了。毕竟除了通过定时任务触发刷新,还可以在界面上通过按钮手动触发刷新,或者通过消息机制回调刷新。这一部分就请大家根据实际业务情况来自由发挥了。验证我们创建一个原型工程和三个简单的定时任务来验证下,第一个任务是执行周期固定的任务,假设它的Cron表达式永远不会发生变化,像这样:@Service public class CronTaskBar implements IPollableService { @Override public void poll() { System.out.println("Say Bar"); } @Override public String getCronExpression() { return "0/1 * * * * ?"; } }第二个任务是一个经常更换执行周期的任务,我们用一个随机数发生器来模拟它的善变:@Service public class CronTaskFoo implements IPollableService { private static final Random random = new SecureRandom(); @Override public void poll() { System.out.println("Say Foo"); } @Override public String getCronExpression() { return "0/" + (random.nextInt(9) + 1) + " * * * * ?"; } }第三个任务就厉害了,它仿佛就像一个电灯的开关,在启用和禁用中反复横跳:@Service public class CronTaskUnavailable implements IPollableService { private String cronExpression = "-"; private static final Map<String, String> map = new HashMap<>(); static { map.put("-", "0/1 * * * * ?"); map.put("0/1 * * * * ?", "-"); } @Override public void poll() { System.out.println("Say Unavailable"); } @Override public String getCronExpression() { return (cronExpression = map.get(cronExpression)); } }如果上面的步骤都做对了,日志里应该能看到类似这样的输出:定时调度任务动态加载开始>>>>>> 定时任务[CronTaskBar]的任务表达式未发生变化,无需刷新 定时任务[CronTaskFoo]已加载,当前任务表达式为[0/6 * * * * ?] 定时任务[CronTaskUnavailable]的任务表达式配置为禁用,将被不会被调度执行 定时调度任务动态加载结束<<<<<< Say Bar Say Bar Say Foo Say Bar Say Bar Say Bar 定时调度任务动态加载开始>>>>>> 定时任务[CronTaskBar]的任务表达式未发生变化,无需刷新 定时任务[CronTaskFoo]已加载,当前任务表达式为[0/3 * * * * ?] 定时任务[CronTaskUnavailable]已加载,当前任务表达式为[0/1 * * * * ?] 定时调度任务动态加载结束<<<<<< Say Unavailable Say Bar Say Unavailable Say Bar Say Foo Say Unavailable Say Bar Say Unavailable Say Bar Say Unavailable Say Bar小结我们在上文通过定时刷新和重建任务的方式来实现了动态更改 Cron 表达式的需求,能够满足大部分的项目场景,而且没有引入 quartzs 等额外的中间件,可以说是十分的轻量和优雅了。当然,如果各位看官有更好的方法,还请不吝赐教。 -
SpringBoot 优雅实现超大文件上传,通用方案 前言文件上传是一个老生常谈的话题了,在文件相对比较小的情况下,可以直接把文件转化为字节流上传到服务器,但在文件比较大的情况下,用普通的方式进行上传,这可不是一个好的办法,毕竟很少有人会忍受,当文件上传到一半中断后,继续上传却只能重头开始上传,这种让人不爽的体验。那有没有比较好的上传体验呢,答案有的,就是下边要介绍的几种上传方式详细教程秒传1、什么是秒传通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。2、本文实现的秒传核心逻辑a、利用redis的set方法存放文件上传状态,其中key为文件上传的md5,value为是否上传完成的标志位,b、当标志位true为上传已经完成,此时如果有相同文件上传,则进入秒传逻辑。如果标志位为false,则说明还没上传完成,此时需要在调用set的方法,保存块号文件记录的路径,其中key为上传文件md5加一个固定前缀,value为块号文件记录路径分片上传1、什么是分片上传分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。2、分片上传的场景1、大文件上传2、网络环境环境不好,存在需要重传风险的场景断点续传1、什么是断点续传断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。本文的断点续传主要是针对断点上传场景。2、应用场景断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。3、实现断点续传的核心逻辑在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。4、实现流程步骤a、方案一,常规步骤将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;初始化一个分片上传任务,返回本次分片上传唯一标识;按照一定的策略(串行或并行)发送各个分片数据块;发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。b、方案二、本文实现的步骤前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。5、分片上传/断点上传代码实现a、前端采用百度提供的webuploader的插件,进行分片。因本文主要介绍服务端代码实现,webuploader如何进行分片,具体实现可以查看链接: http://fex.baidu.com/webuploader/getting-started.htmlb、后端用两种方式实现文件写入,一种是用RandomAccessFile,如果对RandomAccessFile不熟悉的朋友,可以查看链接: https://blog.csdn.net/dimudan2015/article/details/81910690另一种是使用MappedByteBuffer,对MappedByteBuffer不熟悉的朋友,可以查看链接进行了解: https://www.jianshu.com/p/f90866dcbffc后端进行写入操作的核心代码a、RandomAccessFile实现方式@UploadMode(mode = UploadModeEnum.RANDOM_ACCESS) @Slf4j public class RandomAccessUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile accessTmpFile = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); accessTmpFile = new RandomAccessFile(tmpFile, "rw"); //这个必须与前端设定的值一致 long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); long offset = chunkSize * param.getChunk(); //定位到该分片的偏移量 accessTmpFile.seek(offset); //写入该分片数据 accessTmpFile.write(param.getFile().getBytes()); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessTmpFile); } return false; } } b、MappedByteBuffer实现方式@UploadMode(mode = UploadModeEnum.MAPPED_BYTEBUFFER) @Slf4j public class MappedByteBufferUploadStrategy extends SliceUploadTemplate { @Autowired private FilePathUtil filePathUtil; @Value("${upload.chunkSize}") private long defaultChunkSize; @Override public boolean upload(FileUploadRequestDTO param) { RandomAccessFile tempRaf = null; FileChannel fileChannel = null; MappedByteBuffer mappedByteBuffer = null; try { String uploadDirPath = filePathUtil.getPath(param); File tmpFile = super.createTmpFile(param); tempRaf = new RandomAccessFile(tmpFile, "rw"); fileChannel = tempRaf.getChannel(); long chunkSize = Objects.isNull(param.getChunkSize()) ? defaultChunkSize * 1024 * 1024 : param.getChunkSize(); //写入该分片数据 long offset = chunkSize * param.getChunk(); byte[] fileData = param.getFile().getBytes(); mappedByteBuffer = fileChannel .map(FileChannel.MapMode.READ_WRITE, offset, fileData.length); mappedByteBuffer.put(fileData); boolean isOk = super.checkAndSetUploadProgress(param, uploadDirPath); return isOk; } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.freedMappedByteBuffer(mappedByteBuffer); FileUtil.close(fileChannel); FileUtil.close(tempRaf); } return false; } } c、文件操作核心模板类代码@Slf4j public abstract class SliceUploadTemplate implements SliceUploadStrategy { public abstract boolean upload(FileUploadRequestDTO param); protected File createTmpFile(FileUploadRequestDTO param) { FilePathUtil filePathUtil = SpringContextHolder.getBean(FilePathUtil.class); param.setPath(FileUtil.withoutHeadAndTailDiagonal(param.getPath())); String fileName = param.getFile().getOriginalFilename(); String uploadDirPath = filePathUtil.getPath(param); String tempFileName = fileName + "_tmp"; File tmpDir = new File(uploadDirPath); File tmpFile = new File(uploadDirPath, tempFileName); if (!tmpDir.exists()) { tmpDir.mkdirs(); } return tmpFile; } @Override public FileUploadDTO sliceUpload(FileUploadRequestDTO param) { boolean isOk = this.upload(param); if (isOk) { File tmpFile = this.createTmpFile(param); FileUploadDTO fileUploadDTO = this.saveAndFileUploadDTO(param.getFile().getOriginalFilename(), tmpFile); return fileUploadDTO; } String md5 = FileMD5Util.getFileMD5(param.getFile()); Map<Integer, String> map = new HashMap<>(); map.put(param.getChunk(), md5); return FileUploadDTO.builder().chunkMd5Info(map).build(); } /** * 检查并修改文件上传进度 */ public boolean checkAndSetUploadProgress(FileUploadRequestDTO param, String uploadDirPath) { String fileName = param.getFile().getOriginalFilename(); File confFile = new File(uploadDirPath, fileName + ".conf"); byte isComplete = 0; RandomAccessFile accessConfFile = null; try { accessConfFile = new RandomAccessFile(confFile, "rw"); //把该分段标记为 true 表示完成 System.out.println("set part " + param.getChunk() + " complete"); //创建conf文件文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认0,已上传的就是Byte.MAX_VALUE 127 accessConfFile.setLength(param.getChunks()); accessConfFile.seek(param.getChunk()); accessConfFile.write(Byte.MAX_VALUE); //completeList 检查是否全部完成,如果数组里是否全部都是127(全部分片都成功上传) byte[] completeList = FileUtils.readFileToByteArray(confFile); isComplete = Byte.MAX_VALUE; for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) { //与运算, 如果有部分没有完成则 isComplete 不是 Byte.MAX_VALUE isComplete = (byte) (isComplete & completeList[i]); System.out.println("check part " + i + " complete?:" + completeList[i]); } } catch (IOException e) { log.error(e.getMessage(), e); } finally { FileUtil.close(accessConfFile); } boolean isOk = setUploadProgress2Redis(param, uploadDirPath, fileName, confFile, isComplete); return isOk; } /** * 把上传进度信息存进redis */ private boolean setUploadProgress2Redis(FileUploadRequestDTO param, String uploadDirPath, String fileName, File confFile, byte isComplete) { RedisUtil redisUtil = SpringContextHolder.getBean(RedisUtil.class); if (isComplete == Byte.MAX_VALUE) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "true"); redisUtil.del(FileConstant.FILE_MD5_KEY + param.getMd5()); confFile.delete(); return true; } else { if (!redisUtil.hHasKey(FileConstant.FILE_UPLOAD_STATUS, param.getMd5())) { redisUtil.hset(FileConstant.FILE_UPLOAD_STATUS, param.getMd5(), "false"); redisUtil.set(FileConstant.FILE_MD5_KEY + param.getMd5(), uploadDirPath + FileConstant.FILE_SEPARATORCHAR + fileName + ".conf"); } return false; } } /** * 保存文件操作 */ public FileUploadDTO saveAndFileUploadDTO(String fileName, File tmpFile) { FileUploadDTO fileUploadDTO = null; try { fileUploadDTO = renameFile(tmpFile, fileName); if (fileUploadDTO.isUploadComplete()) { System.out .println("upload complete !!" + fileUploadDTO.isUploadComplete() + " name=" + fileName); //TODO 保存文件信息到数据库 } } catch (Exception e) { log.error(e.getMessage(), e); } finally { } return fileUploadDTO; } /** * 文件重命名 * * @param toBeRenamed 将要修改名字的文件 * @param toFileNewName 新的名字 */ private FileUploadDTO renameFile(File toBeRenamed, String toFileNewName) { //检查要重命名的文件是否存在,是否是文件 FileUploadDTO fileUploadDTO = new FileUploadDTO(); if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) { log.info("File does not exist: {}", toBeRenamed.getName()); fileUploadDTO.setUploadComplete(false); return fileUploadDTO; } String ext = FileUtil.getExtension(toFileNewName); String p = toBeRenamed.getParent(); String filePath = p + FileConstant.FILE_SEPARATORCHAR + toFileNewName; File newFile = new File(filePath); //修改文件名 boolean uploadFlag = toBeRenamed.renameTo(newFile); fileUploadDTO.setMtime(DateUtil.getCurrentTimeStamp()); fileUploadDTO.setUploadComplete(uploadFlag); fileUploadDTO.setPath(filePath); fileUploadDTO.setSize(newFile.length()); fileUploadDTO.setFileExt(ext); fileUploadDTO.setFileId(toFileNewName); return fileUploadDTO; } } 总结在实现分片上传的过程,需要前端和后端配合,比如前后端的上传块号的文件大小,前后端必须得要一致,否则上传就会有问题。其次文件相关操作正常都是要搭建一个文件服务器的,比如使用fastdfs、hdfs等。本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的md5值计算,后端写入的速度还是比较快。如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:https://help.aliyun.com/product/31815.html阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
-
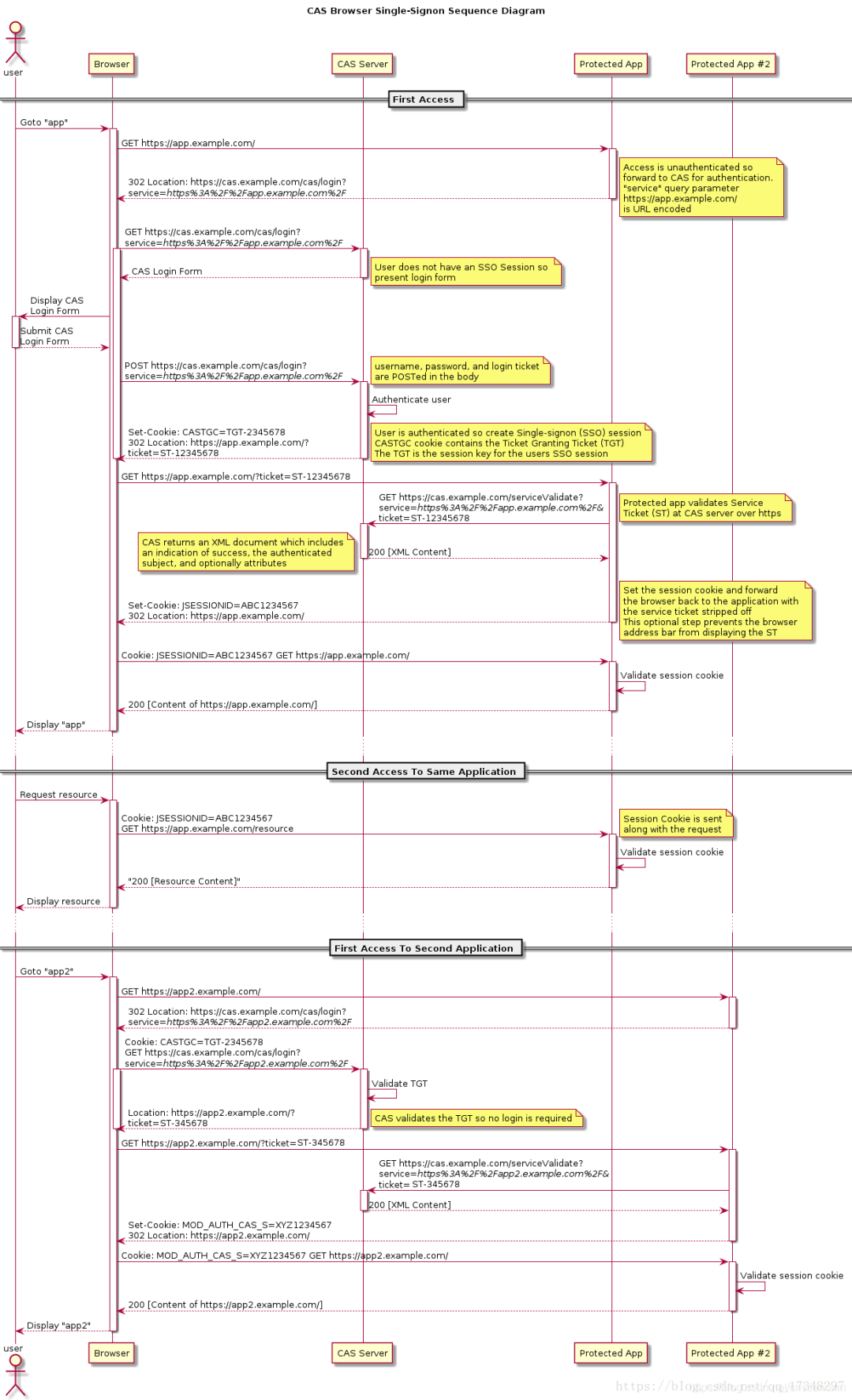
SSO 单点登录和 OAuth2.0 的区别和理解 一、概述SSO 是Single Sign On的缩写,OAuth是Open Authority的缩写,这两者都是使用令牌的方式来代替用户密码访问应用。流程上来说他们非常相似,但概念上又十分不同。SSO大家应该比较熟悉,它将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。OAuth2.0 原理可能比较陌生,但平时用的却很多,比如访问某网站想留言又不想注册时使用了微信授权。以上两者,你在业务系统中都没有账号和密码,账号密码是存放在登录中心或微信服务器中的,这就是所谓的使用令牌代替账号密码访问应用。二、SSO两者有很多相似之处,下面我们来解释一下这个过程。先来讲解SSO,通过SSO对比OAuth2.0,才比较好理解OAuth2.0的原理。SSO的实现有很多框架,比如CAS框架,以下是CAS框架的官方流程图。特别注意:SSO是一种思想,而CAS只是实现这种思想的一种框架而已上面的流程大概为:用户输入网址进入业务系统 Protected App ,系统发现用户未登录,将用户重定向到单点登录系统 CAS Server ,并带上自身地址service参数用户浏览器重定向到单点登录系统,系统检查该用户是否登录,这是SSO(这里是CAS)系统的第一个接口,该接口如果用户未登录,则将用户重定向到登录界面,如果已登录,则设置全局session,并重定向到业务系统用户填写密码后提交登录,注意此时的登录界面是SSO系统提供的,只有SSO系统保存了用户的密码,SSO系统验证密码是否正确,若正确则重定向到业务系统,并带上SSO系统的签发的ticket浏览器重定向到业务系统的登录接口,这个登录接口是不需要密码的,而是带上SSO的ticket,业务系统拿着ticket请求SSO系统,获取用户信息。并设置局部session,表示登录成功返回给浏览器 sessionId (tomcat中叫 JSESSIONID )之后所有的交互用 sessionId 与业务系统交互即可最常见的例子是,我们打开淘宝APP,首页就会有天猫、聚划算等服务的链接,当你点击以后就直接跳过去了,并没有让你再登录一次三、OAuth2.0OAuth2.0 有多种模式,这里讲的是OAuth2.0授权码模式,OAuth2.0的流程跟SSO差不多,在OAuth2中,有授权服务器、资源服务器、客户端这样几个角色,当我们用它来实现SSO的时候是不需要资源服务器这个角色的,有授权服务器和客户端就够了。授权服务器当然是用来做认证的,客户端就是各个应用系统,我们只需要登录成功后拿到用户信息以及用户所拥有的权限即可用户在某网站上点击使用微信授权,这里的某网站就类似业务系统,微信授权服务器就类似单点登录系统之后微信授权服务器返回一个确认授权页面,类似登录界面,这个页面当然是微信的而不是业务系统的用户确认授权,类似填写了账号和密码,提交后微信鉴权并返回一个ticket,并重定向业务系统。业务系统带上ticket访问微信服务器,微信服务器返回正式的token,业务系统就可以使用token获取用户信息了简介一下OAuth2.0的四种模式:授权码(authorization-code)授权码(authorization code)方式,指的是第三方应用先申请一个授权码,然后再用该码获取令牌。这种方式是最常用的流程,安全性也最高,它适用于那些有后端的 Web 应用。授权码通过前端传送,令牌则是储存在后端,而且所有与资源服务器的通信都在后端完成。这样的前后端分离,可以避免令牌泄漏。隐藏式(implicit)有些 Web 应用是纯前端应用,没有后端。这时就不能用上面的方式了,必须将令牌储存在前端。RFC 6749 就规定了第二种方式,允许直接向前端颁发令牌。这种方式没有授权码这个中间步骤,所以称为(授权码)“隐藏式”(implicit)密码式(password)如果你高度信任某个应用,RFC 6749 也允许用户把用户名和密码,直接告诉该应用。该应用就使用你的密码,申请令牌,这种方式称为"密码式"(password)。客户端凭证(client credentials)最后一种方式是凭证式(client credentials),适用于没有前端的命令行应用,即在命令行下请求令牌。简单流程四、说一下几个名词的区别首先,SSO 是一种思想,或者说是一种解决方案,是抽象的,我们要做的就是按照它的这种思想去实现它其次,OAuth2 是用来允许用户授权第三方应用访问他在另一个服务器上的资源的一种协议,它不是用来做单点登录的,但我们可以利用它来实现单点登录。在本例实现SSO的过程中,受保护的资源就是用户的信息(包括,用户的基本信息,以及用户所具有的权限),而我们想要访问这这一资源就需要用户登录并授权,OAuth2服务端负责令牌的发放等操作,这令牌的生成我们采用JWT,也就是说JWT是用来承载用户的Access_Token的最后,Spring Security、Shiro 是用于安全访问的,用来做访问权限控制。
-
小而全的第三方登录开源类库,开箱即用! JustAuth ,如你所见,它仅仅是一个第三方授权登录的工具类库,它可以让我们脱离繁琐的第三方登录 SDK,让登录变得 So easy!JustAuth 集成了诸如:Github、Gitee、支付宝、新浪微博、微信、Google、Facebook、Twitter、StackOverflow 等国内外数十家第三方平台。功能丰富的 OAuth 平台: 集成国内外数十家第三方平台,实现快速接入。自定义 state: 支持自定义 State 和缓存方式,开发者可根据实际情况选择任意缓存插件。自定义 OAuth: 提供统一接口,支持接入任意 OAuth 网站,快速实现 OAuth 登录功能。更容易适配自有的 OAuth 服务。自定义 Http: 接口 HTTP 工具,开发者可以根据自己项目的实际情况选择相对应的 HTTP 工具。自定义 Scope: 支持自定义 scope,以适配更多的业务场景,而不仅仅是为了登录。代码规范·简单: JustAuth 代码严格遵守阿里巴巴编码规约,结构清晰、逻辑简单。快速使用(以 QQ 为例)申请开发者如果是第一次使用,需要到 “QQ 互联平台” 申请开发者,通过后创建应用并且复制三个信息:App ID、App Key和网站回调域。集成 JustAuth添加依赖<dependency> <groupId>me.zhyd.oauth</groupId> <artifactId>JustAuth</artifactId> <version>{latest-version}</version> </dependency>创建Request,把第一步的三个信息添加进去AuthRequest authRequest = new AuthQqRequest(AuthConfig.builder() .clientId("App ID") .clientSecret("App Key") .redirectUri("网站回调域") .build());生成授权地址//这个链接可以直接在后台重定向跳转,也可以返回到前端跳转 String authorizeUrl = authRequest.authorize(AuthStateUtils.createState());或者生成静态授权页面AuthRequest authRequest = AuthRequestBuilder.builder() .source("github") .authConfig(AuthConfig.builder() .clientId("clientId") .clientSecret("clientSecret") .redirectUri("redirectUri") .build()) .build(); // 生成授权页面 authRequest.authorize("state"); // 授权登录后会返回code(auth_code(仅限支付宝))、state,1.8.0版本后,可以用AuthCallback类作为回调接口的参数 // 注:JustAuth默认保存state的时效为3分钟,3分钟内未使用则会自动清除过期的state authRequest.login(callback);或者生成动态授权页面AuthRequest authRequest = AuthRequestBuilder.builder() .source("gitee") .authConfig((source) -> { // 通过 source 动态获取 AuthConfig // 此处可以灵活的从 sql 中取配置也可以从配置文件中取配置 return AuthConfig.builder() .clientId("clientId") .clientSecret("clientSecret") .redirectUri("redirectUri") .build(); }) .build(); Assert.assertTrue(authRequest instanceof AuthGiteeRequest); System.out.println(authRequest.authorize(AuthStateUtils.createState()));JustAuth 的团队还在持续接入其他平台的授权登录,感兴趣的可以关注一下。开源地址:https://github.com/justauth/JustAuth
-
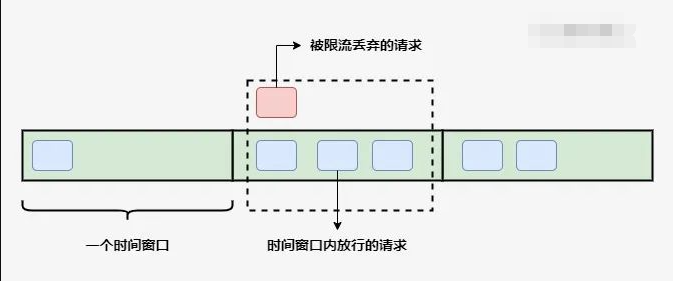
JAVA 6 种服务限流方案技术选型,哪个最香? 服务限流 ,是指通过控制请求的速率或次数来达到保护服务的目的,在微服务中,我们通常会将它和熔断、降级搭配在一起使用,来避免瞬时的大量请求对系统造成负荷,来达到保护服务平稳运行的目的。下面就来看一看常见的6种限流方式,以及它们的实现与使用。## 固定窗口算法固定窗口算法 通过在单位时间内维护一个计数器,能够限制在每个固定的时间段内请求通过的次数,以达到限流的效果。算法实现起来也比较简单,可以通过构造方法中的参数指定时间窗口大小以及允许通过的请求数量,当请求进入时先比较当前时间是否超过窗口上边界,未越界且未超过计数器上限则可以放行请求。@Slf4j public class FixedWindowRateLimiter { // 时间窗口大小,单位毫秒 private long windowSize; // 允许通过请求数 private int maxRequestCount; // 当前窗口通过的请求计数 private AtomicInteger count=new AtomicInteger(0); // 窗口右边界 private long windowBorder; public FixedWindowRateLimiter(long windowSize,int maxRequestCount){ this.windowSize = windowSize; this.maxRequestCount = maxRequestCount; windowBorder = System.currentTimeMillis()+windowSize; } public synchronized boolean tryAcquire(){ long currentTime = System.currentTimeMillis(); if (windowBorder < currentTime){ log.info("window reset"); do { windowBorder += windowSize; }while(windowBorder < currentTime); count=new AtomicInteger(0); } if (count.intValue() < maxRequestCount){ count.incrementAndGet(); log.info("tryAcquire success"); return true; }else { log.info("tryAcquire fail"); return false; } } }进行测试,允许在1000毫秒内通过5个请求:void test() throws InterruptedException { FixedWindowRateLimiter fixedWindowRateLimiter = new FixedWindowRateLimiter(1000, 5); for (int i = 0; i < 10; i++) { if (fixedWindowRateLimiter.tryAcquire()) { System.out.println("执行任务"); }else{ System.out.println("被限流"); TimeUnit.MILLISECONDS.sleep(300); } } }运行结果:固定窗口算法 的优点是实现简单,但是可能无法应对突发流量的情况,比如每秒允许放行100个请求,但是在0.9秒前都没有请求进来,这就造成了在0.9秒到1秒这段时间内要处理100个请求,而在1秒到1.1秒间可能会再进入100个请求,这就造成了要在0.2秒内处理200个请求,这种流量激增就可能导致后端服务出现异常。滑动窗口算法滑动窗口算法 在固定窗口的基础上,进行了一定的升级改造。它的算法的核心在于将时间窗口进行了更精细的分片,将固定窗口分为多个小块,每次仅滑动一小块的时间。并且在每个时间段内都维护了单独的计数器,每次滑动时,都减去前一个时间块内的请求数量,并再添加一个新的时间块到末尾,当时间窗口内所有小时间块的计数器之和超过了请求阈值时,就会触发限流操作。看一下算法的实现,核心就是通过一个int类型的数组循环使用来维护每个时间片内独立的计数器:@Slf4j public class SlidingWindowRateLimiter { // 时间窗口大小,单位毫秒 private long windowSize; // 分片窗口数 private int shardNum; // 允许通过请求数 private int maxRequestCount; // 各个窗口内请求计数 private int[] shardRequestCount; // 请求总数 private int totalCount; // 当前窗口下标 private int shardId; // 每个小窗口大小,毫秒 private long tinyWindowSize; // 窗口右边界 private long windowBorder; public SlidingWindowRateLimiter(long windowSize, int shardNum, int maxRequestCount) { this.windowSize = windowSize; this.shardNum = shardNum; this.maxRequestCount = maxRequestCount; shardRequestCount = new int[shardNum]; tinyWindowSize = windowSize/ shardNum; windowBorder=System.currentTimeMillis(); } public synchronized boolean tryAcquire() { long currentTime = System.currentTimeMillis(); if (currentTime > windowBorder){ do { shardId = (++shardId) % shardNum; totalCount -= shardRequestCount[shardId]; shardRequestCount[shardId]=0; windowBorder += tinyWindowSize; }while (windowBorder < currentTime); } if (totalCount < maxRequestCount){ log.info("tryAcquire success,{}",shardId); shardRequestCount[shardId]++; totalCount++; return true; }else{ log.info("tryAcquire fail,{}",shardId); return false; } } }进行一下测试,对第一个例子中的规则进行修改,每1秒允许100个请求通过不变,在此基础上再把每1秒等分为10个0.1秒的窗口。void test() throws InterruptedException { SlidingWindowRateLimiter slidingWindowRateLimiter = new SlidingWindowRateLimiter(1000, 10, 10); TimeUnit.MILLISECONDS.sleep(800); for (int i = 0; i < 15; i++) { boolean acquire = slidingWindowRateLimiter.tryAcquire(); if (acquire){ System.out.println("执行任务"); }else{ System.out.println("被限流"); } TimeUnit.MILLISECONDS.sleep(10); } }查看运行结果:程序启动后,在先休眠了一段时间后再发起请求,可以看到在0.9秒到1秒的时间窗口内放行了6个请求,在1秒到1.1秒内放行了4个请求,随后就进行了限流,解决了在固定窗口算法中相邻时间窗口内允许通过大量请求的问题。滑动窗口算法通过将时间片进行分片,对流量的控制更加精细化,但是相应的也会浪费一些存储空间,用来维护每一块时间内的单独计数,并且还没有解决固定窗口中可能出现的流量激增问题。漏桶算法为了应对流量激增的问题,后续又衍生出了漏桶算法,用专业一点的词来说,漏桶算法能够进行流量整形和流量控制。漏桶是一个很形象的比喻,外部请求就像是水一样不断注入水桶中,而水桶已经设置好了最大出水速率,漏桶会以这个速率匀速放行请求,而当水超过桶的最大容量后则被丢弃。看一下代码实现:@Slf4j public class LeakyBucketRateLimiter { // 桶的容量 private int capacity; // 桶中现存水量 private AtomicInteger water=new AtomicInteger(0); // 开始漏水时间 private long leakTimeStamp; // 水流出的速率,即每秒允许通过的请求数 private int leakRate; public LeakyBucketRateLimiter(int capacity,int leakRate){ this.capacity=capacity; this.leakRate=leakRate; } public synchronized boolean tryAcquire(){ // 桶中没有水,重新开始计算 if (water.get()==0){ log.info("start leaking"); leakTimeStamp = System.currentTimeMillis(); water.incrementAndGet(); return water.get() < capacity; } // 先漏水,计算剩余水量 long currentTime = System.currentTimeMillis(); int leakedWater= (int) ((currentTime-leakTimeStamp)/1000 * leakRate); log.info("lastTime:{}, currentTime:{}. LeakedWater:{}",leakTimeStamp,currentTime,leakedWater); // 可能时间不足,则先不漏水 if (leakedWater != 0){ int leftWater = water.get() - leakedWater; // 可能水已漏光,设为0 water.set(Math.max(0,leftWater)); leakTimeStamp=System.currentTimeMillis(); } log.info("剩余容量:{}",capacity-water.get()); if (water.get() < capacity){ log.info("tryAcquire success"); water.incrementAndGet(); return true; }else { log.info("tryAcquire fail"); return false; } } }进行一下测试,先初始化一个漏桶,设置桶的容量为3,每秒放行1个请求,在代码中每500毫秒尝试请求1次:void test() throws InterruptedException { LeakyBucketRateLimiter leakyBucketRateLimiter =new LeakyBucketRateLimiter(3,1); for (int i = 0; i < 15; i++) { if (leakyBucketRateLimiter.tryAcquire()) { System.out.println("执行任务"); }else { System.out.println("被限流"); } TimeUnit.MILLISECONDS.sleep(500); } }查看运行结果,按规则进行了放行:但是,漏桶算法同样也有缺点,不管当前系统的负载压力如何,所有请求都得进行排队,即使此时服务器的负载处于相对空闲的状态,这样会造成系统资源的浪费。由于漏桶的缺陷比较明显,所以在实际业务场景中,使用的比较少。令牌桶算法令牌桶算法 是基于 漏桶算法 的一种改进,主要在于令牌桶算法能够在限制服务调用的平均速率的同时,还能够允许一定程度内的突发调用。它的主要思想是系统以 恒定的 速度生成令牌,并将令牌放入令牌桶中,当令牌桶中满了的时候,再向其中放入的令牌就会被丢弃。而每次请求进入时,必须从令牌桶中获取一个令牌,如果没有获取到令牌则被限流拒绝。假设令牌的生成速度是每秒100个,并且第一秒内只使用了70个令牌,那么在第二秒可用的令牌数量就变成了130,在允许的请求范围上限内,扩大了请求的速率。当然,这里要设置桶容量的上限,避免超出系统能够承载的最大请求数量。Guava 中的 RateLimiter 就是基于令牌桶实现的,可以直接拿来使用,先引入依赖:<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>29.0-jre</version> </dependency>进行测试,设置 每秒产生5个令牌 :void acquireTest(){ RateLimiter rateLimiter=RateLimiter.create(5); for (int i = 0; i < 10; i++) { double time = rateLimiter.acquire(); log.info("等待时间:{}s",time); } }运行结果:可以看到,每 200ms 左右产生一个令牌并放行请求,也就是1秒放行 5 个请求,使用 RateLimiter 能够很好的实现单机的限流。那么再回到我们前面提到的突发流量情况,令牌桶是怎么解决的呢?RateLimiter中引入了一个预消费的概念。在源码中,有这么一段注释: * <p>It is important to note that the number of permits requested <i>never</i> affects the * throttling of the request itself (an invocation to {@code acquire(1)} and an invocation to {@code * acquire(1000)} will result in exactly the same throttling, if any), but it affects the throttling * of the <i>next</i> request. I.e., if an expensive task arrives at an idle RateLimiter, it will be * granted immediately, but it is the <i>next</i> request that will experience extra throttling, * thus paying for the cost of the expensive task.大意就是,申请令牌的数量不同不会影响这个申请令牌这个动作本身的响应时间, acquire(1) 和 acquire(1000) 这两个请求会消耗同样的时间返回结果,但是会影响下一个请求的响应时间。如果一个消耗大量令牌的任务到达空闲的 RateLimiter ,会被立即批准执行,但是当下一个请求进来时,将会额外等待一段时间,用来支付前一个请求的时间成本。至于为什么要这么做,通过举例来引申一下。当一个系统处于空闲状态时,突然来了1个需要消耗100个令牌的任务,那么白白等待100秒是毫无意义的浪费资源行为,那么可以先允许它执行,并对后续请求进行限流时间上的延长,以此来达到一个应对突发流量的效果。看一下具体的代码示例:void acquireMultiTest(){ RateLimiter rateLimiter=RateLimiter.create(1); for (int i = 0; i <3; i++) { int num = 2 * i + 1; log.info("获取{}个令牌", num); double cost = rateLimiter.acquire(num); log.info("获取{}个令牌结束,耗时{}ms",num,cost); } }运行结果:可以看到,在第二次请求时需要 3 个令牌,但是并没有等 3 秒后才获取成功,而是在等第一次的1个令牌所需要的1秒偿还后,立即获得了3个令牌得到了放行。同样,第三次获取5个令牌时等待的3秒是偿还的第二次获取令牌的时间,偿还完成后立即获取5个新令牌,而并没有等待全部重新生成完成。除此之外 RateLimiter 还具有 平滑预热功能 ,下面的代码就实现了在启动3秒内,平滑提高令牌发放速率到每秒 5 个的功能:void acquireSmoothly(){ RateLimiter rateLimiter=RateLimiter.create(5,3, TimeUnit.SECONDS); long startTimeStamp = System.currentTimeMillis(); for (int i = 0; i < 15; i++) { double time = rateLimiter.acquire(); log.info("等待时间:{}s, 总时间:{}ms" ,time,System.currentTimeMillis()-startTimeStamp); } }查看运行结果:可以看到,令牌发放时间从最开始的 500ms 多逐渐缩短,在 3 秒后达到了 200ms 左右的匀速发放。总的来说,基于令牌桶实现的 RateLimiter 功能还是非常强大的,在限流的基础上还可以把请求平均分散在各个时间段内,因此在单机情况下它是使用比较广泛的限流组件。中间件限流前面讨论的四种方式都是针对单体架构,无法跨 JVM 进行限流,而在分布式、微服务架构下,可以借助一些中间件进行限。 Sentinel 是 Spring Cloud Alibaba 中常用的熔断限流组件,为我们提供了开箱即用的限流方法。使用起来也非常简单,在 service层 的方法上添加 @SentinelResource注解 ,通过 value 指定资源名称, blockHandler 指定一个方法,该方法会在原方法被限流、降级、系统保护时被调用。@Service public class QueryService { public static final String KEY="query"; @SentinelResource(value = KEY, blockHandler ="blockHandlerMethod") public String query(String name){ return "begin query,name="+name; } public String blockHandlerMethod(String name, BlockException e){ e.printStackTrace(); return "blockHandlerMethod for Query : " + name; } }配置限流规则,这里使用直接编码方式配置,指定 QPS 到达 1 时进行限流:@Component public class SentinelConfig { @PostConstruct private void init(){ List<FlowRule> rules = new ArrayList<>(); FlowRule rule = new FlowRule(QueryService.KEY); rule.setCount(1); rule.setGrade(RuleConstant.FLOW_GRADE_QPS); rule.setLimitApp("default"); rules.add(rule); FlowRuleManager.loadRules(rules); } }在 application.yml 中配置 sentinel 的端口及 dashboard 地址:spring: application: name: sentinel-test cloud: sentinel: transport: port: 8719 dashboard: localhost:8088启动项目后,启动 sentinel-dashboard :java -Dserver.port=8088 -jar sentinel-dashboard-1.8.0.jar在浏览器打开 dashboard 就可以看见我们设置的流控规则:进行接口测试,在超过 QPS 指定的限制后,则会执行 blockHandler() 方法中的逻辑:Sentinel 在微服务架构下得到了广泛的使用,能够提供可靠的集群流量控制、服务断路等功能。在使用中,限流可以结合熔断、降级一起使用,成为有效应对三高系统的三板斧,来保证服务的稳定性。网关限流网关限流也是目前比较流行的一种方式,这里我们介绍采用 Spring Cloud 的gateway组件进行限流的方式。在项目中引入依赖, gateway 的限流实际使用的是 Redis 加 lua 脚本的方式实现的令牌桶,因此还需要引入redis的相关依赖:<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis-reactive</artifactId> </dependency>对 gateway 进行配置,主要就是配一下令牌的生成速率、令牌桶的存储量上限,以及用于限流的键的解析器。这里设置的桶上限为 2 ,每秒填充 1 个令牌:spring: application: name: gateway-test cloud: gateway: routes: - id: limit_route uri: lb://sentinel-test predicates: - Path=/sentinel-test/** filters: - name: RequestRateLimiter args: # 令牌桶每秒填充平均速率 redis-rate-limiter.replenishRate: 1 # 令牌桶上限 redis-rate-limiter.burstCapacity: 2 # 指定解析器,使用spEl表达式按beanName从spring容器中获取 key-resolver: "#{@pathKeyResolver}" - StripPrefix=1 redis: host: 127.0.0.1 port: 6379我们使用请求的路径作为限流的键,编写对应的解析器:@Slf4j @Component public class PathKeyResolver implements KeyResolver { public Mono<String> resolve(ServerWebExchange exchange) { String path = exchange.getRequest().getPath().toString(); log.info("Request path: {}",path); return Mono.just(path); } }启动gateway,使用 jmeter 进行测试,设置请求间隔为 500ms ,因为每秒生成一个令牌,所以后期达到了每两个请求放行1个的限流效果,在被限流的情况下,http请求会返回429状态码。除了上面的根据请求路径限流外,我们还可以灵活设置各种限流的维度,例如根据请求 heade r中携带的用户信息、或是携带的参数等等。当然,如果不想用 gateway 自带的这个 Redis 的限流器的话,我们也可以自己实现 RateLimiter接口 来实现一个自己的限流工具。gateway 实现限流的关键是 spring-cloud-gateway-core 包中的 RedisRateLimiter类 ,以及 META-INF/scripts 中的 request-rate-limiter.lua 这个脚本,如果有兴趣可以看一下具体是如何实现的。{mtitle title="总结"/}总的来说,要保证系统的抗压能力,限流是一个必不可少的环节,虽然可能会造成某些用户的请求被丢弃,但相比于突发流量造成的系统宕机来说,这些损失一般都在可以接受的范围之内。前面也说过,限流可以结合熔断、降级一起使用,多管齐下,保证服务的可用性与健壮性。
-
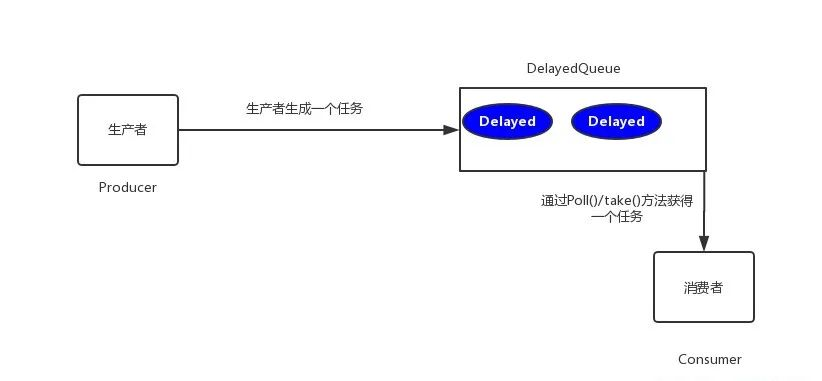
JAVA实现订单 30 分钟未支付则自动取消,我有五种方案! 引言方案分析(1)数据库轮询(2)JDK的延迟队列(3)时间轮算法(4)redis缓存(5)使用消息队列总结引言在开发中,往往会遇到一些关于延时任务的需求。例如:生成订单30分钟未支付,则自动取消;生成订单60秒后,给用户发短信。对上述的任务,我们给一个专业的名字来形容,那就是 延时任务 。那么这里就会产生一个问题,这个 延时任务和定时任务 的区别究竟在哪里呢?一共有如下几点区别:定时任务有明确的触发时间,延时任务没有;定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期;定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务。下面,我们以判断订单是否超时为例,进行方案分析。方案分析(1) 数据库轮询思路 该方案通常是在小型项目中使用,即通过一个线程定时的去扫描数据库,通过订单时间来判断是否有超时的订单,然后进行update或delete等操作。实现 博主当年早期是用 quartz 来实现的(实习那会的事),简单介绍一下 maven 项目引入一个依赖如下所示<dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.2.2</version> </dependency>调用Demo类MyJob如下所示package com.rjzheng.delay1; import org.quartz.JobBuilder; import org.quartz.JobDetail; import org.quartz.Scheduler; import org.quartz.SchedulerException; import org.quartz.SchedulerFactory; import org.quartz.SimpleScheduleBuilder; import org.quartz.Trigger; import org.quartz.TriggerBuilder; import org.quartz.impl.StdSchedulerFactory; import org.quartz.Job; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; public class MyJob implements Job { public void execute(JobExecutionContext context) throws JobExecutionException { System.out.println("要去数据库扫描啦。。。"); } public static void main(String[] args) throws Exception { // 创建任务 JobDetail jobDetail = JobBuilder.newJob(MyJob.class) .withIdentity("job1", "group1").build(); // 创建触发器 每3秒钟执行一次 Trigger trigger = TriggerBuilder .newTrigger() .withIdentity("trigger1", "group3") .withSchedule( SimpleScheduleBuilder.simpleSchedule() .withIntervalInSeconds(3).repeatForever()) .build(); Scheduler scheduler = new StdSchedulerFactory().getScheduler(); // 将任务及其触发器放入调度器 scheduler.scheduleJob(jobDetail, trigger); // 调度器开始调度任务 scheduler.start(); } }运行代码,可发现每隔3秒,输出如下要去数据库扫描啦。。。优缺点 优点: 简单易行,支持集群操作。缺点:(1)对服务器内存消耗大;(2)存在延迟,比如你每隔3分钟扫描一次,那最坏的延迟时间就是3分钟;(3)假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大。(2) JDK的延迟队列思路 该方案是利用 JDK 自带的 DelayQueue 来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入DelayQueue中的对象,是必须实现Delayed接口的。DelayedQueue实现工作流程如下图所示其中poll(): 获取并移除队列的超时元素,没有则返回空;take(): 获取并移除队列的超时元素,如果没有则wait当前线程,直到有元素满足超时条件,返回结果。实现定义一个类OrderDelay实现Delayed,代码如下:package com.rjzheng.delay2; import java.util.concurrent.Delayed; import java.util.concurrent.TimeUnit; public class OrderDelay implements Delayed { private String orderId; private long timeout; OrderDelay(String orderId, long timeout) { this.orderId = orderId; this.timeout = timeout + System.nanoTime(); } public int compareTo(Delayed other) { if (other == this) return 0; OrderDelay t = (OrderDelay) other; long d = (getDelay(TimeUnit.NANOSECONDS) - t .getDelay(TimeUnit.NANOSECONDS)); return (d == 0) ? 0 : ((d < 0) ? -1 : 1); } // 返回距离你自定义的超时时间还有多少 public long getDelay(TimeUnit unit) { return unit.convert(timeout - System.nanoTime(), TimeUnit.NANOSECONDS); } void print() { System.out.println(orderId+"编号的订单要删除啦。。。。"); } }运行的测试Demo为,我们设定延迟时间为3秒。package com.rjzheng.delay2; import java.util.ArrayList; import java.util.List; import java.util.concurrent.DelayQueue; import java.util.concurrent.TimeUnit; public class DelayQueueDemo { public static void main(String[] args) { // TODO Auto-generated method stub List<String> list = new ArrayList<String>(); list.add("00000001"); list.add("00000002"); list.add("00000003"); list.add("00000004"); list.add("00000005"); DelayQueue<OrderDelay> queue = new DelayQueue<OrderDelay>(); long start = System.currentTimeMillis(); for(int i = 0;i<5;i++){ //延迟三秒取出 queue.put(new OrderDelay(list.get(i), TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS))); try { queue.take().print(); System.out.println("After " + (System.currentTimeMillis()-start) + " MilliSeconds"); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }输出如下:00000001编号的订单要删除啦。。。。 After 3003 MilliSeconds 00000002编号的订单要删除啦。。。。 After 6006 MilliSeconds 00000003编号的订单要删除啦。。。。 After 9006 MilliSeconds 00000004编号的订单要删除啦。。。。 After 12008 MilliSeconds 00000005编号的订单要删除啦。。。。 After 15009 MilliSeconds可以看到都是延迟3秒,订单被删除。优缺点 优点: 效率高,任务触发时间延迟低。缺点:(1) 服务器重启后,数据全部消失,怕宕机;(2) 集群扩展相当麻烦;(3) 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常;(4) 代码复杂度较高。(3) 时间轮算法思路 先上一张时间轮的图(这图到处都是啦)时间轮算法可以类比于时钟,如上图箭头(指针)按某一个方向按固定频率轮动,每一次跳动称为一个 tick。这样可以看出定时轮由个3个重要的属性参数,ticksPerWheel(一轮的tick数),tickDuration(一个tick的持续时间)以及 timeUnit(时间单位),例如当ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和现实中的始终的秒针走动完全类似了。如果当前指针指在1上面,我有一个任务需要4秒以后执行,那么这个执行的线程回调或者消息将会被放在5上。那如果需要在20秒之后执行怎么办,由于这个环形结构槽数只到8,如果要20秒,指针需要多转2圈。位置是在2圈之后的5上面(20 % 8 + 1)。实现 我们用Netty的HashedWheelTimer来实现 给Pom加上下面的依赖:<dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.1.24.Final</version> </dependency>测试代码HashedWheelTimerTest,如下所示:package com.rjzheng.delay3; import io.netty.util.HashedWheelTimer; import io.netty.util.Timeout; import io.netty.util.Timer; import io.netty.util.TimerTask; import java.util.concurrent.TimeUnit; public class HashedWheelTimerTest { static class MyTimerTask implements TimerTask{ boolean flag; public MyTimerTask(boolean flag){ this.flag = flag; } public void run(Timeout timeout) throws Exception { // TODO Auto-generated method stub System.out.println("要去数据库删除订单了。。。。"); this.flag =false; } } public static void main(String[] argv) { MyTimerTask timerTask = new MyTimerTask(true); Timer timer = new HashedWheelTimer(); timer.newTimeout(timerTask, 5, TimeUnit.SECONDS); int i = 1; while(timerTask.flag){ try { Thread.sleep(1000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println(i+"秒过去了"); i++; } } }输出如下:1秒过去了 2秒过去了 3秒过去了 4秒过去了 5秒过去了 要去数据库删除订单了。。。。 6秒过去了优缺点 优点: 效率高,任务触发时间延迟时间比delayQueue低,代码复杂度比delayQueue低。缺点:(1) 服务器重启后,数据全部消失,怕宕机;(2) 集群扩展相当麻烦;(3) 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常。(4) redis缓存思路一 利用 redis 的 zset ,zset是一个有序集合,每一个元素(member)都关联了一个score,通过score排序来取集合中的值。zset常用命令添加元素:ZADD key score member [[score member] [score member] ...]按顺序查询元素:ZRANGE key start stop [WITHSCORES]查询元素score:ZSCORE key member移除元素:ZREM key member [member ...]测试如下: # 添加单个元素 redis> ZADD page_rank 10 google.com (integer) 1 # 添加多个元素 redis> ZADD page_rank 9 baidu.com 8 bing.com (integer) 2 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # 查询元素的score值 redis> ZSCORE page_rank bing.com "8" # 移除单个元素 redis> ZREM page_rank google.com (integer) 1 redis> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9"那么如何实现呢?我们将订单超时时间戳与订单号分别设置为 score 和 member ,系统扫描第一个元素判断是否超时,具体如下图所示:实现一package com.rjzheng.delay4; import java.util.Calendar; import java.util.Set; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.Tuple; public class AppTest { private static final String ADDR = "127.0.0.1"; private static final int PORT = 6379; private static JedisPool jedisPool = new JedisPool(ADDR, PORT); public static Jedis getJedis() { return jedisPool.getResource(); } //生产者,生成5个订单放进去 public void productionDelayMessage(){ for(int i=0;i<5;i++){ //延迟3秒 Calendar cal1 = Calendar.getInstance(); cal1.add(Calendar.SECOND, 3); int second3later = (int) (cal1.getTimeInMillis() / 1000); AppTest.getJedis().zadd("OrderId", second3later,"OID0000001"+i); System.out.println(System.currentTimeMillis()+"ms:redis生成了一个订单任务:订单ID为"+"OID0000001"+i); } } //消费者,取订单 public void consumerDelayMessage(){ Jedis jedis = AppTest.getJedis(); while(true){ Set<Tuple> items = jedis.zrangeWithScores("OrderId", 0, 1); if(items == null || items.isEmpty()){ System.out.println("当前没有等待的任务"); try { Thread.sleep(500); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } continue; } int score = (int) ((Tuple)items.toArray()[0]).getScore(); Calendar cal = Calendar.getInstance(); int nowSecond = (int) (cal.getTimeInMillis() / 1000); if(nowSecond >= score){ String orderId = ((Tuple)items.toArray()[0]).getElement(); jedis.zrem("OrderId", orderId); System.out.println(System.currentTimeMillis() +"ms:redis消费了一个任务:消费的订单OrderId为"+orderId); } } } public static void main(String[] args) { AppTest appTest =new AppTest(); appTest.productionDelayMessage(); appTest.consumerDelayMessage(); } }此时对应输出如下:1525086085261ms:redis生成了一个订单任务:订单ID为OID00000010 1525086085263ms:redis生成了一个订单任务:订单ID为OID00000011 1525086085266ms:redis生成了一个订单任务:订单ID为OID00000012 1525086085268ms:redis生成了一个订单任务:订单ID为OID00000013 1525086085270ms:redis生成了一个订单任务:订单ID为OID00000014 1525086088000ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525086088001ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525086088002ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525086088003ms:redis消费了一个任务:消费的订单OrderId为OID00000013 1525086088004ms:redis消费了一个任务:消费的订单OrderId为OID00000014 当前没有等待的任务 当前没有等待的任务 当前没有等待的任务可以看到,几乎都是3秒之后,消费订单。然而,这一版存在一个致命的硬伤,在高并发条件下,多消费者会取到同一个订单号,我们上测试代码 ThreadTest 。package com.rjzheng.delay4; import java.util.concurrent.CountDownLatch; public class ThreadTest { private static final int threadNum = 10; private static CountDownLatch cdl = new CountDownLatch(threadNum); static class DelayMessage implements Runnable{ public void run() { try { cdl.await(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } AppTest appTest =new AppTest(); appTest.consumerDelayMessage(); } } public static void main(String[] args) { AppTest appTest =new AppTest(); appTest.productionDelayMessage(); for(int i=0;i<threadNum;i++){ new Thread(new DelayMessage()).start(); cdl.countDown(); } } }输出如下所示:1525087157727ms:redis生成了一个订单任务:订单ID为OID00000010 1525087157734ms:redis生成了一个订单任务:订单ID为OID00000011 1525087157738ms:redis生成了一个订单任务:订单ID为OID00000012 1525087157747ms:redis生成了一个订单任务:订单ID为OID00000013 1525087157753ms:redis生成了一个订单任务:订单ID为OID00000014 1525087160009ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525087160011ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525087160012ms:redis消费了一个任务:消费的订单OrderId为OID00000010 1525087160022ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525087160023ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525087160029ms:redis消费了一个任务:消费的订单OrderId为OID00000011 1525087160038ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525087160045ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525087160048ms:redis消费了一个任务:消费的订单OrderId为OID00000012 1525087160053ms:redis消费了一个任务:消费的订单OrderId为OID00000013 1525087160064ms:redis消费了一个任务:消费的订单OrderId为OID00000013 1525087160065ms:redis消费了一个任务:消费的订单OrderId为OID00000014 1525087160069ms:redis消费了一个任务:消费的订单OrderId为OID00000014 当前没有等待的任务 当前没有等待的任务 当前没有等待的任务 当前没有等待的任务显然,出现了多个线程消费同一个资源的情况。解决方案(1) 用分布式锁,但是用分布式锁,性能下降了,该方案不细说;(2) 对ZREM的返回值进行判断,只有大于0的时候,才消费数据,于是将 consumerDelayMessage() 方法里的。if(nowSecond >= score){ String orderId = ((Tuple)items.toArray()[0]).getElement(); jedis.zrem("OrderId", orderId); System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId); }修改为:if(nowSecond >= score){ String orderId = ((Tuple)items.toArray()[0]).getElement(); Long num = jedis.zrem("OrderId", orderId); if( num != null && num>0){ System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId); } }在这种修改后,重新运行ThreadTest类,发现输出正常了。思路二 该方案使用 redis 的 Keyspace Notifications ,中文翻译就是键空间机制,就是利用该机制可以在key失效之后,提供一个回调,实际上是redis会给客户端发送一个消息。是需要 redis版本2.8以上 。实现二 在 redis.conf 中,加入一条配置:notify-keyspace-events Ex运行代码如下:package com.rjzheng.delay5; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPubSub; public class RedisTest { private static final String ADDR = "127.0.0.1"; private static final int PORT = 6379; private static JedisPool jedis = new JedisPool(ADDR, PORT); private static RedisSub sub = new RedisSub(); public static void init() { new Thread(new Runnable() { public void run() { jedis.getResource().subscribe(sub, "__keyevent@0__:expired"); } }).start(); } public static void main(String[] args) throws InterruptedException { init(); for(int i =0;i<10;i++){ String orderId = "OID000000"+i; jedis.getResource().setex(orderId, 3, orderId); System.out.println(System.currentTimeMillis()+"ms:"+orderId+"订单生成"); } } static class RedisSub extends JedisPubSub { @Override public void onMessage(String channel, String message) { System.out.println(System.currentTimeMillis()+"ms:"+message+"订单取消"); } } }输出如下:1525096202813ms:OID0000000订单生成 1525096202818ms:OID0000001订单生成 1525096202824ms:OID0000002订单生成 1525096202826ms:OID0000003订单生成 1525096202830ms:OID0000004订单生成 1525096202834ms:OID0000005订单生成 1525096202839ms:OID0000006订单生成 1525096205819ms:OID0000000订单取消 1525096205920ms:OID0000005订单取消 1525096205920ms:OID0000004订单取消 1525096205920ms:OID0000001订单取消 1525096205920ms:OID0000003订单取消 1525096205920ms:OID0000006订单取消 1525096205920ms:OID0000002订单取消可以明显看到3秒过后,订单取消了。ps: redis的pub/sub 机制存在一个硬伤,官网内容如下:原: Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.翻: Redis的发布/订阅目前是即发即弃(fire and forget)模式的,因此无法实现事件的可靠通知。也就是说,如果发布/订阅的客户端断链之后又重连,则在客户端断链期间的所有事件都丢失了。因此,方案二不是太推荐。当然,如果你对可靠性要求不高,可以使用。优缺点 优点:(1) 由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性;(2) 做集群扩展相当方便;(3) 时间准确度高。缺点: (1) 需要额外进行redis维护。(5) 使用消息队列我们可以采用 RabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列:(1)RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter(2)lRabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能,具体的,我改天再写一篇文章,这里再讲下去,篇幅太长。优缺点优点: 高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。缺点:本身的易用度要依赖于rabbitMq的运维。因为要引用rabbitMq,所以复杂度和成本变高。总结本文总结了目前互联网中,绝大部分的延时任务的实现方案。希望大家在工作中能够有所收获。
-
不要再封装各种JAVA Util 工具类了,这个神级框架值得拥有! 今天给大家推荐一个非常好用的Java工具类库,企业级常用工具类,基本都有,能避免重复造轮子及节省大量的开发时间,非常不错,值得大家去了解使用。Hutool 谐音 “糊涂”,寓意追求 “万事都作糊涂观,无所谓失,无所谓得” 的境界。Hutool 是一个 Java 工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让 Java 语言也可以 “甜甜的”。Hutool 最初是我项目中 “util” 包的一个整理,后来慢慢积累并加入更多非业务相关功能,并广泛学习其它开源项目精髓,经过自己整理修改,最终形成丰富的开源工具集。一、功能一个 Java 基础工具类,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行封装,组成各种 Util 工具类,同时提供以下组件:tool-aop JDK 动态代理封装,提供非 IOC 下的切面支持hutool-bloomFilter 布隆过滤,提供一些 Hash 算法的布隆过滤hutool-cache 缓存hutool-core 核心,包括 Bean 操作、日期、各种 Util 等hutool-cron 定时任务模块,提供类 Crontab 表达式的定时任务hutool-crypto 加密解密模块hutool-db JDBC 封装后的数据操作,基于 ActiveRecord 思想hutool-dfa 基于 DFA 模型的多关键字查找hutool-extra 扩展模块,对第三方封装(模板引擎、邮件等)hutool-http 基于 HttpUrlConnection 的 Http 客户端封装hutool-log 自动识别日志实现的日志门面hutool-script 脚本执行封装,例如 Javascripthutool-setting 功能更强大的 Setting 配置文件和 Properties 封装hutool-system 系统参数调用封装(JVM 信息等)hutool-json JSON 实现hutool-captcha 图片验证码实现二、安装maven 项目在 pom.xml 添加以下依赖即可:<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>4.6.3</version> </dependency>三、简单测试DateUtil 日期时间工具类,定义了一些常用的日期时间操作方法。//Date、long、Calendar之间的相互转换 //当前时间 Date date = DateUtil.date(); //Calendar转Date date = DateUtil.date(Calendar.getInstance()); //时间戳转Date date = DateUtil.date(System.currentTimeMillis()); //自动识别格式转换 String dateStr = "2017-03-01"; date = DateUtil.parse(dateStr); //自定义格式化转换 date = DateUtil.parse(dateStr, "yyyy-MM-dd"); //格式化输出日期 String format = DateUtil.format(date, "yyyy-MM-dd"); //获得年的部分 int year = DateUtil.year(date); //获得月份,从0开始计数 int month = DateUtil.month(date); //获取某天的开始、结束时间 Date beginOfDay = DateUtil.beginOfDay(date); Date endOfDay = DateUtil.endOfDay(date); //计算偏移后的日期时间 Date newDate = DateUtil.offset(date, DateField.DAY_OF_MONTH, 2); //计算日期时间之间的偏移量 long betweenDay = DateUtil.between(date, newDate, DateUnit.DAY);StrUtil 字符串工具类,定义了一些常用的字符串操作方法。//判断是否为空字符串 String str = "test"; StrUtil.isEmpty(str); StrUtil.isNotEmpty(str); //去除字符串的前后缀 StrUtil.removeSuffix("a.jpg", ".jpg"); StrUtil.removePrefix("a.jpg", "a."); //格式化字符串 String template = "这只是个占位符:{}"; String str2 = StrUtil.format(template, "我是占位符"); LOGGER.info("/strUtil format:{}", str2);NumberUtil 数字处理工具类,可用于各种类型数字的加减乘除操作及判断类型。double n1 = 1.234; double n2 = 1.234; double result; //对float、double、BigDecimal做加减乘除操作 result = NumberUtil.add(n1, n2); result = NumberUtil.sub(n1, n2); result = NumberUtil.mul(n1, n2); result = NumberUtil.div(n1, n2); //保留两位小数 BigDecimal roundNum = NumberUtil.round(n1, 2); String n3 = "1.234"; //判断是否为数字、整数、浮点数 NumberUtil.isNumber(n3); NumberUtil.isInteger(n3); NumberUtil.isDouble(n3); BeanUtil JavaBean的工具类,可用于Map与JavaBean对象的互相转换以及对象属性的拷贝。 PmsBrand brand = new PmsBrand(); brand.setId(1L); brand.setName("小米"); brand.setShowStatus(0); //Bean转Map Map<String, Object> map = BeanUtil.beanToMap(brand); LOGGER.info("beanUtil bean to map:{}", map); //Map转Bean PmsBrand mapBrand = BeanUtil.mapToBean(map, PmsBrand.class, false); LOGGER.info("beanUtil map to bean:{}", mapBrand); //Bean属性拷贝 PmsBrand copyBrand = new PmsBrand(); BeanUtil.copyProperties(brand, copyBrand); LOGGER.info("beanUtil copy properties:{}", copyBrand);MapUtil Map操作工具类,可用于创建Map对象及判断Map是否为空。//将多个键值对加入到Map中 Map<Object, Object> map = MapUtil.of(new String[][]{ {"key1", "value1"}, {"key2", "value2"}, {"key3", "value3"} }); //判断Map是否为空 MapUtil.isEmpty(map); MapUtil.isNotEmpty(map); AnnotationUtil 注解工具类,可用于获取注解与注解中指定的值。 //获取指定类、方法、字段、构造器上的注解列表 Annotation[] annotationList = AnnotationUtil.getAnnotations(HutoolController.class, false); LOGGER.info("annotationUtil annotations:{}", annotationList); //获取指定类型注解 Api api = AnnotationUtil.getAnnotation(HutoolController.class, Api.class); LOGGER.info("annotationUtil api value:{}", api.description()); //获取指定类型注解的值 Object annotationValue = AnnotationUtil.getAnnotationValue(HutoolController.class, RequestMapping.class);SecureUtil 加密解密工具类,可用于MD5加密。//MD5加密 String str = "123456"; String md5Str = SecureUtil.md5(str); LOGGER.info("secureUtil md5:{}", md5Str);CaptchaUtil 验证码工具类,可用于生成图形验证码。//生成验证码图片 LineCaptcha lineCaptcha = CaptchaUtil.createLineCaptcha(200, 100); try { request.getSession().setAttribute("CAPTCHA_KEY", lineCaptcha.getCode()); response.setContentType("image/png");//告诉浏览器输出内容为图片 response.setHeader("Pragma", "No-cache");//禁止浏览器缓存 response.setHeader("Cache-Control", "no-cache"); response.setDateHeader("Expire", 0); lineCaptcha.write(response.getOutputStream()); } catch (IOException e) { e.printStackTrace(); }Hutool中的工具类很多,可以参考官网:https://www.hutool.cn/当然,还有很多其他非常方便的方法,留着你自己去测试吧!使用Hutool工具,可以大大提高你的开发效率!
-
讲的太通透了,切面 AOP 优雅的实现权限校验! 1 理解AOP1.1 什么是AOPAOP(Aspect Oriented Programming) ,面向切面思想,是 Spring 的三大核心思想之一(两外两个:IOC-控制反转、DI-依赖注入)。那么 AOP 为何那么重要呢?在我们的程序中,经常存在一些系统性的需求,比如权限校验、日志记录、统计等,这些代码会散落穿插在各个业务逻辑中,非常冗余且不利于维护。例如下面这个示意图:有多少业务操作,就要写多少重复的校验和日志记录代码,这显然是无法接受的。当然,用面向对象的思想,我们可以把这些重复的代码抽离出来,写成公共方法,就是下面这样:这样,代码冗余和可维护性的问题得到了解决,但每个业务方法中依然要依次手动调用这些公共方法,也是略显繁琐。有没有更好的方式呢?有的,那就是AOP,AOP将权限校验、日志记录等非业务代码完全提取出来,与业务代码分离,并寻找节点切入业务代码中:1.2 AOP体系与概念简单地去理解,其实AOP要做三类事:在哪里切入,也就是权限校验等非业务操作在哪些业务代码中执行。在什么时候切入,是业务代码执行前还是执行后。切入后做什么事,比如做权限校验、日志记录等。因此,AOP的体系可以梳理为下图:一些概念详解:「Pointcut」:切点,决定处理如权限校验、日志记录等在何处切入业务代码中(即织入切面)。切点分为execution方式和annotation方式。前者可以用路径表达式指定哪些类织入切面,后者可以指定被哪些注解修饰的代码织入切面。「Advice」:处理,包括处理时机和处理内容。处理内容就是要做什么事,比如校验权限和记录日志。处理时机就是在什么时机执行处理内容,分为前置处理(即业务代码执行前)、后置处理(业务代码执行后)等。「Aspect」:切面,即Pointcut和Advice。「Joint point」:连接点,是程序执行的一个点。例如,一个方法的执行或者一个异常的处理。在 Spring AOP 中,一个连接点总是代表一个方法执行。「Weaving」:织入,就是通过动态代理,在目标对象方法中执行处理内容的过程。网络上有张图,我觉得非常传神,贴在这里供大家观详:2 AOP实例实践出真知,接下来我们就撸代码来实现一下AOP。完整项目已上传至:GitHub AOP demo项目,该项目是关于springboot的集成项目,AOP部分请关注【aop-demo】模块。使用 AOP,首先需要引入 AOP 的依赖。<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>2.1 第一个实例接下来,我们先看一个极简的例子:所有的get请求被调用前在控制台输出一句"get请求的advice触发了"。具体实现如下:1.创建一个AOP切面类,只要在类上加个 @Aspect 注解即可。@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。@Component 注解将该类交给 Spring 来管理。在这个类里实现advice:package com.mu.demo.advice; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.aspectj.lang.annotation.Pointcut; import org.springframework.stereotype.Component; @Aspect @Component public class LogAdvice { // 定义一个切点:所有被GetMapping注解修饰的方法会织入advice @Pointcut("@annotation(org.springframework.web.bind.annotation.GetMapping)") private void logAdvicePointcut() {} // Before表示logAdvice将在目标方法执行前执行 @Before("logAdvicePointcut()") public void logAdvice(){ // 这里只是一个示例,你可以写任何处理逻辑 System.out.println("get请求的advice触发了"); } }2.创建一个接口类,内部创建一个get请求:package com.mu.demo.controller; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping(value = "/aop") public class AopController { @GetMapping(value = "/getTest") public JSONObject aopTest() { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200}"); } @PostMapping(value = "/postTest") public JSONObject aopTest2(@RequestParam("id") String id) { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200}"); } }项目启动后,请求http://localhost:8085/aop/getTest接口:请求http://localhost:8085/aop/postTest接口,控制台无输出,证明切点确实是只针对被GetMapping修饰的方法。2.2 第二个实例下面我们将问题复杂化一些,该例的场景是:自定义一个注解PermissionsAnnotation创建一个切面类,切点设置为拦截所有标注PermissionsAnnotation的方法,截取到接口的参数,进行简单的权限校验将PermissionsAnnotation标注在测试接口类的测试接口test上具体的实现步骤:1.使用 @Target、@Retention、@Documented 自定义一个注解(关于这三个注解详情请见:元注解详解):@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface PermissionAnnotation{ }2.创建第一个AOP切面类,,只要在类上加个 @Aspect 注解即可。@Aspect 注解用来描述一个切面类,定义切面类的时候需要打上这个注解。 @Component 注解将该类交给 Spring 来管理。在这个类里实现第一步权限校验逻辑:package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; @Aspect @Component @Order(1) public class PermissionFirstAdvice { // 定义一个切面,括号内写入第1步中自定义注解的路径 @Pointcut("@annotation(com.mu.demo.annotation.PermissionAnnotation)") private void permissionCheck() { } @Around("permissionCheck()") public Object permissionCheckFirst(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("===================第一个切面===================:" + System.currentTimeMillis()); //获取请求参数,详见接口类 Object[] objects = joinPoint.getArgs(); Long id = ((JSONObject) objects[0]).getLong("id"); String name = ((JSONObject) objects[0]).getString("name"); System.out.println("id1->>>>>>>>>>>>>>>>>>>>>>" + id); System.out.println("name1->>>>>>>>>>>>>>>>>>>>>>" + name); // id小于0则抛出非法id的异常 if (id < 0) { return JSON.parseObject("{\"message\":\"illegal id\",\"code\":403}"); } return joinPoint.proceed(); } }3.创建接口类,并在目标方法上标注自定义注解 PermissionsAnnotation :package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping(value = "/permission") public class TestController { @RequestMapping(value = "/check", method = RequestMethod.POST) // 添加这个注解 @PermissionsAnnotation() public JSONObject getGroupList(@RequestBody JSONObject request) { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200}"); } }在这里,我们先进行一个测试。首先,填好请求地址和header:其次,构造正常的参数:可以拿到正常的响应结果:然后,构造一个异常参数,再次请求:响应结果显示,切面类进行了判断,并返回相应结果:有人会问,如果我一个接口想设置多个切面类进行校验怎么办?这些切面的执行顺序如何管理?很简单,一个自定义的AOP注解可以对应多个切面类,这些切面类执行顺序由@Order注解管理,该注解后的数字越小,所在切面类越先执行。下面在实例中进行演示:创建第二个AOP切面类,在这个类里实现第二步权限校验:package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; @Aspect @Component @Order(0) public class PermissionSecondAdvice { @Pointcut("@annotation(com.mu.demo.annotation.PermissionAnnotation)") private void permissionCheck() { } @Around("permissionCheck()") public Object permissionCheckSecond(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("===================第二个切面===================:" + System.currentTimeMillis()); //获取请求参数,详见接口类 Object[] objects = joinPoint.getArgs(); Long id = ((JSONObject) objects[0]).getLong("id"); String name = ((JSONObject) objects[0]).getString("name"); System.out.println("id->>>>>>>>>>>>>>>>>>>>>>" + id); System.out.println("name->>>>>>>>>>>>>>>>>>>>>>" + name); // name不是管理员则抛出异常 if (!name.equals("admin")) { return JSON.parseObject("{\"message\":\"not admin\",\"code\":403}"); } return joinPoint.proceed(); } }重启项目,继续测试,构造两个参数都异常的情况:响应结果,表面第二个切面类执行顺序更靠前:3 AOP相关注解上面的案例中,用到了诸多注解,下面针对这些注解进行详解。3.1 @Pointcut@Pointcut 注解,用来定义一个切点,即上文中所关注的某件事情的入口,切入点定义了事件触发时机。@Aspect @Component public class LogAspectHandler { /** * 定义一个切面,拦截 com.mutest.controller 包和子包下的所有方法 */ @Pointcut("execution(* com.mutest.controller..*.*(..))") public void pointCut() {} }@Pointcut 注解指定一个切点,定义需要拦截的东西,这里介绍两个常用的表达式:一个是使用 execution() ,另一个是使用 annotation() 。execution表达式: 以 execution(* com.mutest.controller...(..))) 表达式为例:第一个 号的位置:表示返回值类型, 表示所有类型。包名:表示需要拦截的包名,后面的两个句点表示当前包和当前包的所有子包,在本例中指 com.mutest.controller包、子包下所有类的方法。第二个 号的位置:表示类名, 表示所有类。(..):这个星号表示方法名, 表示所有的方法,后面括弧里面表示方法的参数,两个句点表示任何参数。annotation() 表达式: annotation() 方式是针对某个注解来定义切点,比如我们对具有 @PostMapping 注解的方法做切面,可以如下定义切面:@Pointcut("@annotation(org.springframework.web.bind.annotation.PostMapping)") public void annotationPointcut() {}然后使用该切面的话,就会切入注解是 @PostMapping 的所有方法。这种方式很适合处理 @GetMapping、@PostMapping、@DeleteMapping 不同注解有各种特定处理逻辑的场景。还有就是如上面案例所示,针对自定义注解来定义切面。@Pointcut("@annotation(com.example.demo.PermissionsAnnotation)") private void permissionCheck() {}3.2 @Around@Around 注解用于修饰Around增强处理,Around增强处理非常强大,表现在:@Around可以自由选择增强动作与目标方法的执行顺序,也就是说可以在增强动作前后,甚至过程中执行目标方法。这个特性的实现在于,调用ProceedingJoinPoint参数的procedd()方法才会执行目标方法。@Around可以改变执行目标方法的参数值,也可以改变执行目标方法之后的返回值。Around增强处理有以下特点:当定义一个Around增强处理方法时,该方法的第一个形参必须是 ProceedingJoinPoint 类型(至少一个形参)。在增强处理方法体内,调用ProceedingJoinPoint的proceed方法才会执行目标方法:这就是@Around增强处理可以完全控制目标方法执行时机、如何执行的关键;如果程序没有调用ProceedingJoinPoint的proceed方法,则目标方法不会执行。调用ProceedingJoinPoint的proceed方法时,还可以传入一个Object[ ]对象,该数组中的值将被传入目标方法作为实参——这就是Around增强处理方法可以改变目标方法参数值的关键。这就是如果传入的Object[ ]数组长度与目标方法所需要的参数个数不相等,或者Object[ ]数组元素与目标方法所需参数的类型不匹配,程序就会出现异常。@Around功能虽然强大,但通常需要在线程安全的环境下使用。因此,如果使用普通的Before、AfterReturning就能解决的问题,就没有必要使用Around了。如果需要目标方法执行之前和之后共享某种状态数据,则应该考虑使用Around。尤其是需要使用增强处理阻止目标的执行,或需要改变目标方法的返回值时,则只能使用Around增强处理了。下面,在前面例子上做一些改造,来观察@Around的特点。自定义注解类不变。首先,定义接口类:package com.example.demo; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.springframework.web.bind.annotation.*; @RestController @RequestMapping(value = "/permission") public class TestController { @RequestMapping(value = "/check", method = RequestMethod.POST) @PermissionsAnnotation() public JSONObject getGroupList(@RequestBody JSONObject request) { return JSON.parseObject("{\"message\":\"SUCCESS\",\"code\":200,\"data\":" + request + "}"); } }唯一切面类(前面案例有两个切面类,这里只需保留一个即可):package com.example.demo; import com.alibaba.fastjson.JSONObject; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; @Aspect @Component @Order(1) public class PermissionAdvice { @Pointcut("@annotation(com.example.demo.PermissionsAnnotation)") private void permissionCheck() { } @Around("permissionCheck()") public Object permissionCheck(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("===================开始增强处理==================="); //获取请求参数,详见接口类 Object[] objects = joinPoint.getArgs(); Long id = ((JSONObject) objects[0]).getLong("id"); String name = ((JSONObject) objects[0]).getString("name"); System.out.println("id1->>>>>>>>>>>>>>>>>>>>>>" + id); System.out.println("name1->>>>>>>>>>>>>>>>>>>>>>" + name); // 修改入参 JSONObject object = new JSONObject(); object.put("id", 8); object.put("name", "lisi"); objects[0] = object; // 将修改后的参数传入 return joinPoint.proceed(objects); } }同样使用JMeter调用接口,传入参数:{"id":-5,"name":"admin"},响应结果表明:@Around截取到了接口的入参,并使接口返回了切面类中的结果。3.3 @Before@Before 注解指定的方法在切面切入目标方法之前执行,可以做一些 Log 处理,也可以做一些信息的统计,比如获取用户的请求 URL 以及用户的 IP 地址等等,这个在做个人站点的时候都能用得到,都是常用的方法。例如下面代码:@Aspect @Component @Slf4j public class LogAspectHandler { /** * 在上面定义的切面方法之前执行该方法 * @param joinPoint jointPoint */ @Pointcut("execution(* com.mutest.controller..*.*(..))") public void pointCut() {} @Before("pointCut()") public void doBefore(JoinPoint joinPoint) { log.info("====doBefore方法进入了===="); // 获取签名 Signature signature = joinPoint.getSignature(); // 获取切入的包名 String declaringTypeName = signature.getDeclaringTypeName(); // 获取即将执行的方法名 String funcName = signature.getName(); log.info("即将执行方法为: {},属于{}包", funcName, declaringTypeName); // 也可以用来记录一些信息,比如获取请求的 URL 和 IP ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); // 获取请求 URL String url = request.getRequestURL().toString(); // 获取请求 IP String ip = request.getRemoteAddr(); log.info("用户请求的url为:{},ip地址为:{}", url, ip); } }JointPoint 对象很有用,可以用它来获取一个签名,利用签名可以获取请求的包名、方法名,包括参数(通过 joinPoint.getArgs() 获取)等。3.4 @After@After 注解和 @Before 注解相对应,指定的方法在切面切入目标方法之后执行,也可以做一些完成某方法之后的 Log 处理。@Aspect @Component @Slf4j public class LogAspectHandler { /** * 定义一个切面,拦截 com.mutest.controller 包下的所有方法 */ @Pointcut("execution(* com.mutest.controller..*.*(..))") public void pointCut() {} /** * 在上面定义的切面方法之后执行该方法 * @param joinPoint jointPoint */ @After("pointCut()") public void doAfter(JoinPoint joinPoint) { log.info("==== doAfter 方法进入了===="); Signature signature = joinPoint.getSignature(); String method = signature.getName(); log.info("方法{}已经执行完", method); } }到这里,我们来写个 Controller 测试一下执行结果,新建一个 AopController 如下:@RestController @RequestMapping("/aop") public class AopController { @GetMapping("/{name}") public String testAop(@PathVariable String name) { return "Hello " + name; } }启动项目,在浏览器中输入:localhost:8080/aop/csdn,观察一下控制台的输出信息:====doBefore 方法进入了==== 即将执行方法为: testAop,属于com.itcodai.mutest.AopController包 用户请求的 url 为:http://localhost:8080/aop/name,ip地址为:0:0:0:0:0:0:0:1 ==== doAfter 方法进入了==== 方法 testAop 已经执行完从打印出来的 Log 中可以看出程序执行的逻辑与顺序,可以很直观的掌握 @Before 和 @After 两个注解的实际作用。3.5 @AfterReturning@AfterReturning 注解和 @After 有些类似,区别在于 @AfterReturning 注解可以用来捕获切入方法执行完之后的返回值,对返回值进行业务逻辑上的增强处理,例如:@Aspect @Component @Slf4j public class LogAspectHandler { /** * 在上面定义的切面方法返回后执行该方法,可以捕获返回对象或者对返回对象进行增强 * @param joinPoint joinPoint * @param result result */ @AfterReturning(pointcut = "pointCut()", returning = "result") public void doAfterReturning(JoinPoint joinPoint, Object result) { Signature signature = joinPoint.getSignature(); String classMethod = signature.getName(); log.info("方法{}执行完毕,返回参数为:{}", classMethod, result); // 实际项目中可以根据业务做具体的返回值增强 log.info("对返回参数进行业务上的增强:{}", result + "增强版"); } }需要注意的是,在 @AfterReturning 注解 中,属性 returning 的值必须要和参数保持一致,否则会检测不到。该方法中的第二个入参就是被切方法的返回值,在 doAfterReturning 方法中可以对返回值进行增强,可以根据业务需要做相应的封装。我们重启一下服务,再测试一下:方法 testAop 执行完毕,返回参数为:Hello CSDN 对返回参数进行业务上的增强:Hello CSDN 增强版3.6 @AfterThrowing当被切方法执行过程中抛出异常时,会进入 @AfterThrowing 注解的方法中执行,在该方法中可以做一些异常的处理逻辑。要注意的是 throwing 属性的值必须要和参数一致,否则会报错。该方法中的第二个入参即为抛出的异常。@Aspect @Component @Slf4j public class LogAspectHandler { /** * 在上面定义的切面方法执行抛异常时,执行该方法 * @param joinPoint jointPoint * @param ex ex */ @AfterThrowing(pointcut = "pointCut()", throwing = "ex") public void afterThrowing(JoinPoint joinPoint, Throwable ex) { Signature signature = joinPoint.getSignature(); String method = signature.getName(); // 处理异常的逻辑 log.info("执行方法{}出错,异常为:{}", method, ex); } }完整的项目已上传至Gtihub:https://github.com/ThinkMugz/aopDemo以上就是AOP的全部内容。通过几个例子就可以感受到,AOP的便捷之处。欢迎大家指出文中不足之处。( •̀ ω •́ )y
-
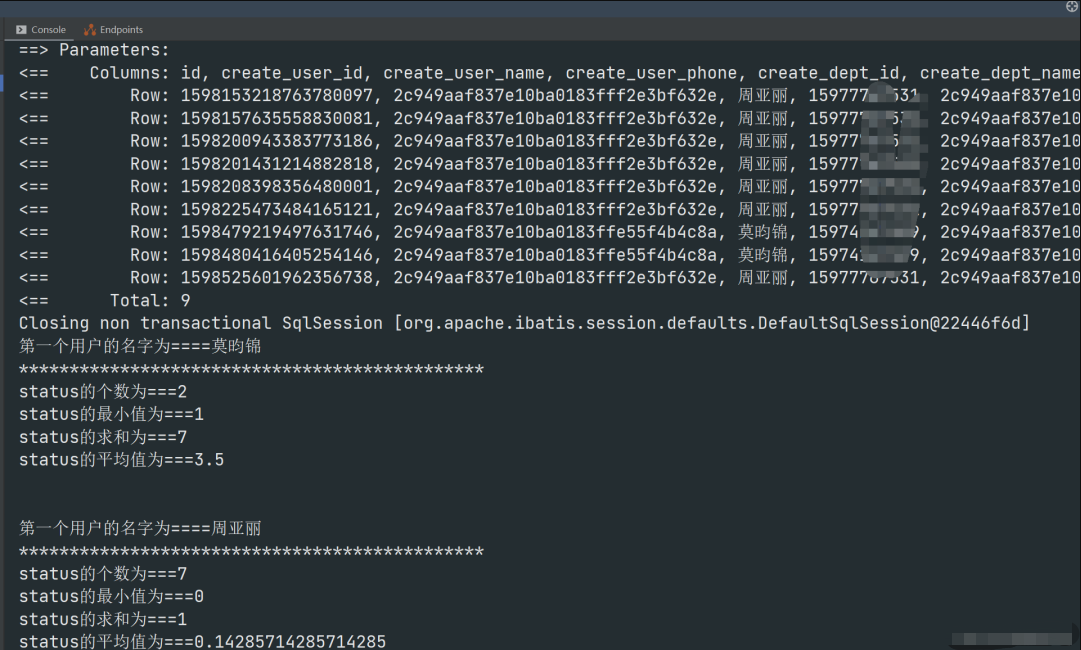
Java8 Stream 一行代码实现数据分组统计、排序、最大值、最小值、平均值、总数、合计 示例:统计用户status的最大值,最小值,求和,平均值分组统计:如果我们想看某个部门下面有哪些数据,可以如下代码求最大值,最小值对某个字段求最大,最小,求和,统计,计数求最大值,最小值还可以这样做对某个字段求和并汇总求某个字段的平均值拼接某个字段的值,可以设置前缀,后缀或者分隔符根据部门进行分组,并获取汇总人数根据部门和是否退休进行分组,并汇总人数根据部门和是否退休进行分组,并取得每组中年龄最大的人Java8 对数据处理可谓十分流畅,既不改变数据,又能对数据进行很好的处理,今天给大家演示下,用Java8的 Stream 如何对数据进行分组统计,排序,求和等这些方法属于Java8的汇总统计类:getAverage(): 它返回所有接受值的平均值。getCount(): 它计算所有元素的总数。getMax(): 它返回最大值。getMin(): 它返回最小值。getSum(): 它返回所有元素的总和。示例:统计用户status的最大值,最小值,求和,平均值看官可以根据自己的需求进行灵活变通@GetMapping("/list") public void list(){ List<InputForm> inputForms = inputFormMapper.selectList(); Map<String, IntSummaryStatistics> collect = inputForms.stream() .collect(Collectors.groupingBy(InputForm::getCreateUserName, Collectors.summarizingInt(InputForm::getStatus))); // 对名字去重 Set<String> collect1 = inputForms.stream().distinct().map(InputForm::getCreateUserName).collect(Collectors.toSet()); // 遍历名字,从map中取出对应用户的status最大值,最小值,平均值。。。 for (String s1 : collect1) { IntSummaryStatistics statistics1 = collect.get(s1); System.out.println("第一个用户的名字为====" + s1); System.out.println("**********************************************"); System.out.println("status的个数为===" + statistics1.getCount()); System.out.println("status的最小值为===" + statistics1.getMin()); System.out.println("status的求和为===" + statistics1.getSum()); System.out.println("status的平均值为===" + statistics1.getAverage()); System.out.println(); System.out.println(); } }结果如下:分组统计:@GetMapping("/list") public void list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); Map<String, Long> collect = inputForms.stream().collect(Collectors.groupingBy(InputForm::getCreateUserName, Collectors.counting())); System.out.println("collect = " + collect); }❝其中Collectors.groupingBy(InputForm::getCreateUserName, Collectors.counting())返回的是一个Map集合,InputForm::getCreateUserName代表key,Collectors.counting()代表value,我是按照创建人的姓名进行统计❞可以看到总共有九条数据,其中莫昀锦有两个,周亚丽有七个如果我们想看某个部门下面有哪些数据,可以如下代码@GetMapping("/list") public Map<String, List<InputForm>> list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); Map<String, List<InputForm>> collect = inputForms.stream() .collect(Collectors.groupingBy(InputForm::getCreateCompanyName)); return collect; }求最大值,最小值@GetMapping("/list") public Map<String, List<InputForm>> list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); Optional<InputForm> min = inputForms.stream() .min(Comparator.comparing(InputForm::getId)); System.out.println("min = " + min); return null; }可以看到此id是最小的,最大值雷同对某个字段求最大,最小,求和,统计,计数@GetMapping("/list") public void list(){ List<InputForm> inputForms = inputFormMapper.selectList(); System.out.println("inputForms = " + inputForms); IntSummaryStatistics collect = inputForms.stream() .collect(Collectors.summarizingInt(InputForm::getStatus)); double average = collect.getAverage(); int max = collect.getMax(); int min = collect.getMin(); long sum = collect.getSum(); long count = collect.getCount(); System.out.println("collect = " + collect); }求最大值,最小值还可以这样做// 求最大值 Optional<InputForm> max = inputForms.stream().max(Comparator.comparing(InputForm::getAgency)); if (max.isPresent()){ System.out.println("max = " + max); } // 求最小值 Optional<InputForm> min = inputForms.stream().min(Comparator.comparing(InputForm::getAgency)); if (min.isPresent()){ System.out.println("min = " + min); }对某个字段求和并汇总int sum = inputForms.stream().mapToInt(InputForm::getStatus).sum(); System.out.println("sum = " + sum);求某个字段的平均值// 求某个字段的平均值 Double collect2 = inputForms.stream().collect(Collectors.averagingInt(InputForm::getStatus)); System.out.println("collect2 = " + collect2); // 简化后 OptionalDouble average = inputForms.stream().mapToDouble(InputForm::getStatus).average(); if (average.isPresent()){ System.out.println("average = " + average); }拼接某个字段的值,可以设置前缀,后缀或者分隔符// 拼接某个字段的值,用逗号分隔,并设置前缀和后缀 String collect3 = inputForms.stream().map(InputForm::getCreateUserName).collect(Collectors.joining(",", "我是前缀", "我是后缀")); System.out.println("collect3 = " + collect3);根据部门进行分组,并获取汇总人数// 根据部门进行汇总,并获取汇总人数 Map<String, Long> collect4 = inputForms.stream().collect(Collectors.groupingBy(InputForm::getCreateDeptName, Collectors.counting())); System.out.println("collect4 = " + collect4);根据部门和是否退休进行分组,并汇总人数// 根据部门和是否退休进行分组,并汇总人数 Map<String, Map<Integer, Long>> collect5 = inputForms.stream().collect(Collectors.groupingBy(InputForm::getCreateDeptName, Collectors.groupingBy(InputForm::getIsDelete, Collectors.counting()))); System.out.println("collect5 = " + collect5);根据部门和是否退休进行分组,并取得每组中年龄最大的人// 根据部门和是否退休进行分组,并取得每组中年龄最大的人 Map<String, Map<Integer, InputForm>> collect6 = inputForms.stream().collect( Collectors.groupingBy(InputForm::getCreateDeptName, Collectors.groupingBy(InputForm::getIsDelete, Collectors.collectingAndThen( Collectors.maxBy( Comparator.comparing(InputForm::getAge)), Optional::get)))); System.out.println("collect6 = " + collect6);
-
SpringBoot 玩一玩代码混淆,防止反编译代码泄露 编译简单就是把代码跑一哈,然后我们的代码 .java文件 就被编译成了 .class 文件反编译就是针对编译生成的 jar/war 包 里面的 .class 文件 逆向还原回来,可以看到你的代码写的啥。比较常用的反编译工具 JD-GUI ,直接把编译好的jar丢进去,大部分都能反编译看到源码:那如果不想给别人反编译看自己写的代码呢?怎么做?混淆该篇玩的代码混淆 ,是其中一种手段。我给你看,但你反编译看到的不是真正的代码。先看一张效果示例图 :开整正文先看一下我们混淆一个项目代码,要做啥?一共就两步第一步, 在项目路径下,新增一份文件 proguard.cfg :proguard.cfg#指定Java的版本 -target 1.8 #proguard会对代码进行优化压缩,他会删除从未使用的类或者类成员变量等 -dontshrink #是否关闭字节码级别的优化,如果不开启则设置如下配置 -dontoptimize #混淆时不生成大小写混合的类名,默认是可以大小写混合 -dontusemixedcaseclassnames # 对于类成员的命名的混淆采取唯一策略 -useuniqueclassmembernames #混淆时不生成大小写混合的类名,默认是可以大小写混合 -dontusemixedcaseclassnames #混淆类名之后,对使用Class.forName('className')之类的地方进行相应替代 -adaptclassstrings #对异常、注解信息予以保留 -keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LineNumberTable,*Annotation*,EnclosingMethod # 此选项将保存接口中的所有原始名称(不混淆)--> -keepnames interface ** { *; } # 此选项将保存所有软件包中的所有原始接口文件(不进行混淆) #-keep interface * extends * { *; } #保留参数名,因为控制器,或者Mybatis等接口的参数如果混淆会导致无法接受参数,xml文件找不到参数 -keepparameternames # 保留枚举成员及方法 -keepclassmembers enum * { *; } # 不混淆所有类,保存原始定义的注释- -keepclassmembers class * { @org.springframework.context.annotation.Bean *; @org.springframework.beans.factory.annotation.Autowired *; @org.springframework.beans.factory.annotation.Value *; @org.springframework.stereotype.Service *; @org.springframework.stereotype.Component *; } #忽略warn消息 -ignorewarnings #忽略note消息 -dontnote #打印配置信息 -printconfiguration -keep public class com.example.myproguarddemo.MyproguarddemoApplication { public static void main(java.lang.String[]); }注意点:其余的看注释,可以配置哪些类不参与混淆,哪些枚举保留,哪些方法名不混淆等等。第二步,在 pom 文件上 加入 proguard 混淆插件 :build标签里面改动加入一下配置<build> <plugins> <plugin> <groupId>com.github.wvengen</groupId> <artifactId>proguard-maven-plugin</artifactId> <version>2.6.0</version> <executions> <!-- 以下配置说明执行mvn的package命令时候,会执行proguard--> <execution> <phase>package</phase> <goals> <goal>proguard</goal> </goals> </execution> </executions> <configuration> <!-- 就是输入Jar的名称,我们要知道,代码混淆其实是将一个原始的jar,生成一个混淆后的jar,那么就会有输入输出。 --> <injar>${project.build.finalName}.jar</injar> <!-- 输出jar名称,输入输出jar同名的时候就是覆盖,也是比较常用的配置。 --> <outjar>${project.build.finalName}.jar</outjar> <!-- 是否混淆 默认是true --> <obfuscate>true</obfuscate> <!-- 配置一个文件,通常叫做proguard.cfg,该文件主要是配置options选项,也就是说使用proguard.cfg那么options下的所有内容都可以移到proguard.cfg中 --> <proguardInclude>${project.basedir}/proguard.cfg</proguardInclude> <!-- 额外的jar包,通常是项目编译所需要的jar --> <libs> <lib>${java.home}/lib/rt.jar</lib> <lib>${java.home}/lib/jce.jar</lib> <lib>${java.home}/lib/jsse.jar</lib> </libs> <!-- 对输入jar进行过滤比如,如下配置就是对META-INFO文件不处理。 --> <inLibsFilter>!META-INF/**,!META-INF/versions/9/**.class</inLibsFilter> <!-- 这是输出路径配置,但是要注意这个路径必须要包括injar标签填写的jar --> <outputDirectory>${project.basedir}/target</outputDirectory> <!--这里特别重要,此处主要是配置混淆的一些细节选项,比如哪些类不需要混淆,哪些需要混淆--> <options> <!-- 可以在此处写option标签配置,不过我上面使用了proguardInclude,故而我更喜欢在proguard.cfg中配置 --> </options> </configuration> </plugin> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>repackage</goal> </goals> <configuration> <mainClass>com.example.myproguarddemo.MyproguarddemoApplication</mainClass> </configuration> </execution> </executions> </plugin> </plugins> </build>注意点:然后可以看到:然后点击 package,正常执行编译打包流程就可以 :然后可以看到jar的生成:看看效果:好了,该篇就到这。