搜索到
18
篇与
的结果
-
 面试官:从 MySQL 读取 百万 数据进行处理,应该怎么做?问倒一大片! 背景大数据量操作的场景大致如下:数据迁移数据导出批量处理数据在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。但有些情况不需要分页的方式查询数据或分很大一页查询数据时,如果一下子将数据全部加载出来到内存中,很可能会发生 OOM(内存溢出) ;而且查询会很慢,因为框架耗费大量的时间和内存去把数据库查询的结果封装成我们想要的对象(实体类)。举例:在业务系统需要从 MySQL 数据库里读取 100万 数据行进行处理,应该怎么做? 做法通常如下:常规查询:一次性读取 100万 数据到 JVM 内存中,或者分页读取流式查询:建立长连接,利用服务端游标,每次读取一条加载到 JVM 内存(多次获取,一次一行)游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据(多次获取,一次多行)常规查询默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于 MySQL 网络协议的设计,因此更易于实现。举例:假设单表 100万 数据量,一般会采用分页的方式查询:@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); }注:该示例使用的 MybatisPlus。该方式比较简单,如果在不考虑 LIMIT 深分页优化情况下,估计你的数据库服务器就噶皮了,或者你能等上几十分钟或几小时,甚至几天时间检索数据。流式查询流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 100万 条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。MyBatis 流式查询接口 MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:Cursor 是可关闭的;Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed():用于判断查询结果是否全部取完。getCurrentIndex():返回已经获取了多少条数据使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理为什么要用流式查询? 如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了 sharding-sphere 的代码不难发现,除了 group by 与 order by 字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。游标查询对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。这种处理方式比常规查询要快很多。当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。Mybatis 的处理加了两个注解: @Options 和 @ResultType@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { // 方式一 多次获取,一次多行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000) Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); // 方式二 一次获取,一次一行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000) @ResultType(BigDataSearchEntity.class) void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler); }@OptionsResultSet.FORWORD_ONLY:结果集的游标只能向下滚动ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变fetchSize:每次获取量@ResultType@ResultType(BigDataSearchEntity.class):转换成返回实体类型注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。注意: 虽然上面的代码中都有 @Options 但实际操作却有不同:方式一是多次查询,一次返回多条;方式二是一次查询,一次返回一条;原因: Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。非流式查询和流式查询区别:非流式查询:内存会随着查询记录的增长而近乎直线增长。流式查询:内存会保持稳定,不会随着记录的增长而增长。其内存大小取决于批处理大小BATCH_SIZE的设置,该尺寸越大,内存会越大。所以BATCH_SIZE应该根据业务情况设置合适的大小。另外要切记每次处理完一批结果要记得释放存储每批数据的临时容器,即上文中的 gxids.clear() ;
面试官:从 MySQL 读取 百万 数据进行处理,应该怎么做?问倒一大片! 背景大数据量操作的场景大致如下:数据迁移数据导出批量处理数据在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。但有些情况不需要分页的方式查询数据或分很大一页查询数据时,如果一下子将数据全部加载出来到内存中,很可能会发生 OOM(内存溢出) ;而且查询会很慢,因为框架耗费大量的时间和内存去把数据库查询的结果封装成我们想要的对象(实体类)。举例:在业务系统需要从 MySQL 数据库里读取 100万 数据行进行处理,应该怎么做? 做法通常如下:常规查询:一次性读取 100万 数据到 JVM 内存中,或者分页读取流式查询:建立长连接,利用服务端游标,每次读取一条加载到 JVM 内存(多次获取,一次一行)游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据(多次获取,一次多行)常规查询默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于 MySQL 网络协议的设计,因此更易于实现。举例:假设单表 100万 数据量,一般会采用分页的方式查询:@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); }注:该示例使用的 MybatisPlus。该方式比较简单,如果在不考虑 LIMIT 深分页优化情况下,估计你的数据库服务器就噶皮了,或者你能等上几十分钟或几小时,甚至几天时间检索数据。流式查询流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 100万 条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。MyBatis 流式查询接口 MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:Cursor 是可关闭的;Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed():用于判断查询结果是否全部取完。getCurrentIndex():返回已经获取了多少条数据使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理为什么要用流式查询? 如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了 sharding-sphere 的代码不难发现,除了 group by 与 order by 字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。游标查询对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。这种处理方式比常规查询要快很多。当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。Mybatis 的处理加了两个注解: @Options 和 @ResultType@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { // 方式一 多次获取,一次多行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000) Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); // 方式二 一次获取,一次一行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000) @ResultType(BigDataSearchEntity.class) void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler); }@OptionsResultSet.FORWORD_ONLY:结果集的游标只能向下滚动ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变fetchSize:每次获取量@ResultType@ResultType(BigDataSearchEntity.class):转换成返回实体类型注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。注意: 虽然上面的代码中都有 @Options 但实际操作却有不同:方式一是多次查询,一次返回多条;方式二是一次查询,一次返回一条;原因: Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。非流式查询和流式查询区别:非流式查询:内存会随着查询记录的增长而近乎直线增长。流式查询:内存会保持稳定,不会随着记录的增长而增长。其内存大小取决于批处理大小BATCH_SIZE的设置,该尺寸越大,内存会越大。所以BATCH_SIZE应该根据业务情况设置合适的大小。另外要切记每次处理完一批结果要记得释放存储每批数据的临时容器,即上文中的 gxids.clear() ; -
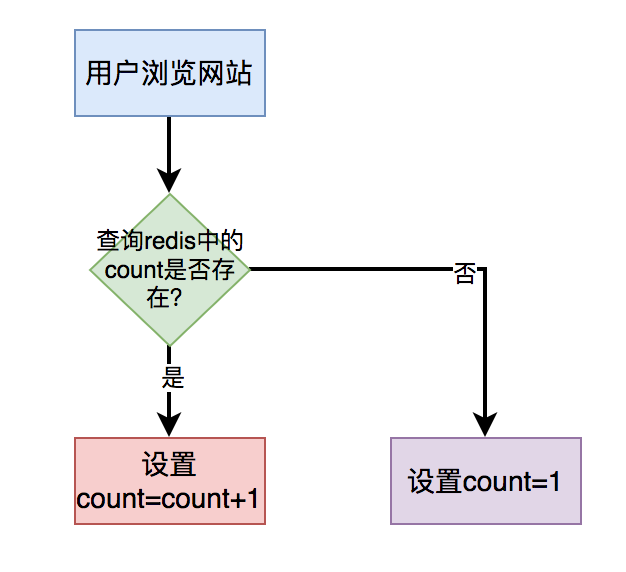
count(*) 导致接口性能差可能是这个原因! 最近我在公司优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助。我们使用的数据库是Mysql8,使用的存储引擎是Innodb。这次优化除了优化索引之外,更多的是在优化count(*)。通常情况下,分页接口一般会查询两次数据库,第一次是获取具体数据,第二次是获取总的记录行数,然后把结果整合之后,再返回。查询具体数据的 sql,比如是这样的:select id,name from user limit 1,20;它没有性能问题。但另外一条使用 count(*)查询总记录行数的 sql,例如:select count(\*) from user;却存在性能差的问题。为什么会出现这种情况呢?1. count(*)为什么性能差?在 Mysql 中,count(*)的作用是统计表中记录的总行数。而count(*)的性能跟存储引擎有直接关系,并非所有的存储引擎,count(*)的性能都很差。在 Mysql 中使用最多的存储引擎是:innodb和myisam。在 myisam 中会把总行数保存到磁盘上,使用 count(*)时,只需要返回那个数据即可,无需额外的计算,所以执行效率很高。而 innodb 则不同,由于它支持事务,有MVCC(即多版本并发控制)的存在,在同一个时间点的不同事务中,同一条查询 sql,返回的记录行数可能是不确定的。在 innodb 使用 count(*)时,需要从存储引擎中一行行的读出数据,然后累加起来,所以执行效率很低。如果表中数据量小还好,一旦表中数据量很大,innodb 存储引擎使用 count(*)统计数据时,性能就会很差。2. 如何优化 count(*)性能?从上面得知,既然count(*)存在性能问题,那么我们该如何优化呢?我们可以从以下几个方面着手。2.1 增加 redis 缓存对于简单的 count(*),比如:统计浏览总次数或者浏览总人数,我们可以直接将接口使用 redis 缓存起来,没必要实时统计。当用户打开指定页面时,在缓存中每次都设置成 count = count+1 即可。用户第一次访问页面时,redis 中的 count 值设置成 1。用户以后每访问一次页面,都让 count 加 1,最后重新设置到 redis 中。这样在需要展示数量的地方,从 redis 中查出 count 值返回即可。该场景无需从数据埋点表中使用 count(*)实时统计数据,性能将会得到极大的提升。不过在高并发的情况下,可能会存在缓存和数据库的数据不一致的问题。但对于统计浏览总次数或者浏览总人数这种业务场景,对数据的准确性要求并不高,容忍数据不一致的情况存在。2.2 加二级缓存对于有些业务场景,新增数据很少,大部分是统计数量操作,而且查询条件很多。这时候使用传统的 count(*)实时统计数据,性能肯定不会好。假如在页面中可以通过 id、name、状态、时间、来源等,一个或多个条件,统计品牌数量。这种情况下用户的组合条件比较多,增加联合索引也没用,用户可以选择其中一个或者多个查询条件,有时候联合索引也会失效,只能尽量满足用户使用频率最高的条件增加索引。也就是有些组合条件可以走索引,有些组合条件没法走索引,这些没法走索引的场景,该如何优化呢?答:使用二级缓存。二级缓存其实就是内存缓存。我们可以使用caffine或者guava实现二级缓存的功能。目前SpringBoot已经集成了 caffine,使用起来非常方便。只需在需要增加二级缓存的查询方法中,使用@Cacheable注解即可。@Cacheable(value = "brand", , keyGenerator = "cacheKeyGenerator") public BrandModel getBrand(Condition condition) { return getBrandByCondition(condition); }然后自定义 cacheKeyGenerator,用于指定缓存的 key。public class CacheKeyGenerator implements KeyGenerator { @Override public Object generate(Object target, Method method, Object... params) { return target.getClass().getSimpleName() + UNDERLINE + method.getName() + "," + StringUtils.arrayToDelimitedString(params, ","); } }这个 key 是由各个条件组合而成。这样通过某个条件组合查询出品牌的数据之后,会把结果缓存到内存中,设置过期时间为 5 分钟。后面用户在 5 分钟内,使用相同的条件,重新查询数据时,可以直接从二级缓存中查出数据,直接返回了。这样能够极大的提示 count(*)的查询效率。但是如果使用二级缓存,可能存在不同的服务器上,数据不一样的情况。我们需要根据实际业务场景来选择,没法适用于所有业务场景。2.3 多线程执行不知道你有没有做过这样的需求:统计有效订单有多少,无效订单有多少。这种情况一般需要写两条 sql,统计有效订单的 sql 如下:select count(\*) from order where status=1;统计无效订单的 sql 如下:select count(\*) from order where status=0;但如果在一个接口中,同步执行这两条 sql 效率会非常低。这时候,可以改成成一条 sql:select count(\*),status from order group by status;使用group by关键字分组统计相同 status 的数量,只会产生两条记录,一条记录是有效订单数量,另外一条记录是无效订单数量。但有个问题:status 字段只有 1 和 0 两个值,重复度很高,区分度非常低,不能走索引,会全表扫描,效率也不高。还有其他的解决方案不?答:使用多线程处理。我们可以使用CompleteFuture使用两个线程异步调用统计有效订单的 sql 和统计无效订单的 sql,最后汇总数据,这样能够提升查询接口的性能。2.4 减少 join 的表大部分的情况下,使用 count(*)是为了实时统计总数量的。但如果表本身的数据量不多,但 join 的表太多,也可能会影响 count(*)的效率。比如在查询商品信息时,需要根据商品名称、单位、品牌、分类等信息查询数据。这时候写一条 sql 可以查出想要的数据,比如下面这样的:select count(\*) from product p inner join unit u on p.unit_id = u.id inner join brand b on p.brand_id = b.id inner join category c on p.category_id = c.id where p.name='测试商品' and u.id=123 and b.id=124 and c.id=125;使用 product 表去join了 unit、brand 和 category 这三张表。其实这些查询条件,在 product 表中都能查询出数据,没必要 join 额外的表。我们可以把 sql 改成这样:select count(\*) from product where name='测试商品' and unit_id=123 and brand_id=124 and category_id=125;在 count(*)时只查 product 单表即可,去掉多余的表 join,让查询效率可以提升不少。2.5 改成 ClickHouse有些时候,join 的表实在太多,没法去掉多余的 join,该怎么办呢?比如上面的例子中,查询商品信息时,需要根据商品名称、单位名称、品牌名称、分类名称等信息查询数据。这时候根据 product 单表是没法查询出数据的,必须要去join:unit、brand 和 category 这三张表,这时候该如何优化呢?答:可以将数据保存到ClickHouse。ClickHouse 是基于列存储的数据库,不支持事务,查询性能非常高,号称查询十几亿的数据,能够秒级返回。为了避免对业务代码的嵌入性,可以使用Canal监听Mysql的binlog日志。当 product 表有数据新增时,需要同时查询出单位、品牌和分类的数据,生成一个新的结果集,保存到 ClickHouse 当中。查询数据时,从 ClickHouse 当中查询,这样使用 count(*)的查询效率能够提升 N 倍。需要特别提醒一下:使用 ClickHouse 时,新增数据不要太频繁,尽量批量插入数据。其实如果查询条件非常多,使用 ClickHouse 也不是特别合适,这时候可以改成ElasticSearch,不过它跟 Mysql 一样,存在深分页问题。3. count 的各种用法性能对比既然说到 count(*),就不能不说一下 count 家族的其他成员,比如:count(1)、count(id)、count(普通索引列)、count(未加索引列)。那么它们有什么区别呢?count(*) :它会获取所有行的数据,不做任何处理,行数加 1。count(1):它会获取所有行的数据,每行固定值 1,也是行数加 1。count(id):id 代表主键,它需要从所有行的数据中解析出 id 字段,其中 id 肯定都不为 NULL,行数加 1。count(普通索引列):它需要从所有行的数据中解析出普通索引列,然后判断是否为 NULL,如果不是 NULL,则行数+1。count(未加索引列):它会全表扫描获取所有数据,解析中未加索引列,然后判断是否为 NULL,如果不是 NULL,则行数+1。由此,最后 count 的性能从高到低是:count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)所以,其实count(*)是最快的。意不意外,惊不惊喜?千万别跟select * 搞混了
-
Linux CentOS 7 纯命令安装 Oracle11g Oracl安装包下载,可参考 Oracle-11.2.0.4安装包1.操作系统[root@lucky ~]# uname -m x86_64 [root@lucky ~]# cat /etc/redhat-release CentOS Linux release 7.7.1908 (Core)2.安装前的准备2.1./etc/hosts 文件中添加主机名vim /etc/hosts 127.0.0.1 lucky [root@lucky ~]# cat /etc/hosts ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 127.0.0.1 lucky2.2 关闭 selinuxvim /etc/selinux/config SELINUX=disabled SELINUXTYPE=targeted2.3 关闭防火墙systemctl stop firewalld systemctl disable firewalld2.4 用 yum 进行安装yum -y install gcc gcc-c++ make binutils compat-libstdc++-33 elfutils-libelf elfutils-libelf-devel elfutils-libelf-devel-static glibc glibc-common glibc-devel ksh libaio libaio-devel libgcc libstdc++ libstdc++-devel numactl-devel sysstat unixODBC unixODBC-devel kernelheaders pdksh pcre-devel readline rlwrap2.5 创建用户、组groupadd oinstall && groupadd dba && useradd -g oinstall -G dba oracle echo "123456" | passwd --stdin oracle && id oracle 2.6 上传软件包cd /home/oracle linux.x64_11gR2_database_1of2.zip linux.x64_11gR2_database_2of2.zip ............2.7 修改内核参数vim /etc/sysctl.conf #添加以下内容 fs.aio-max-nr = 1048576 fs.file-max = 6815744 kernel.shmall = 2097152 kernel.shmmax = 1073741824 kernel.shmmni = 4096 kernel.sem = 250 32000 100 128 net.ipv4.ip_local_port_range = 9000 65500 net.core.rmem_default = 262144 net.core.rmem_max = 4194304 net.core.wmem_default = 262144 net.core.wmem_max = 1048576 #使内核新配置生效 sysctl -p2.8 修改用户限制vim /etc/security/limits.conf #添加以下内容 oracle soft nproc 2047 oracle hard nproc 16384 oracle soft nofile 1024 oracle hard nofile 65536 oracle soft stack 102402.9 修改/etc/pam.d/login 文件vim /etc/pam.d/login #添加以下内容 session required /lib64/security/pam_limits.so session required pam_limits.so 2.10 修改/etc/profile 文件vim /etc/profile #添加以下内容 if [ $USER = "oracle" ]; then if [ $SHELL = "/bin/ksh" ]; then ulimit -p 16384 ulimit -n 65536 else ulimit -u 16384 -n 65536 fi fi 2.11 检查 swap 空间是否足够[root@lucky oracle]# free -m total used free shared buff/cache available Mem: 3789 206 190 908 3392 2414 Swap: 1959 0 1959 #我的是分配了2G,不够的使用以下命令分配 dd if=/dev/zero of=/swapadd bs=1024 count=2006424 mkswap /swapfile swapon /swapfile #编辑这个文件,增加以下内容 vim /etc/fstab /swapfile swap swap default 0 03.ORACLE安装3.1 创建安装包文件存放目录mkdir -p /data/u01/software cd /home/oracle mv linux.x64_11gR2_database_* /data/u01/software/ && cd /data/u01/software3.2 解压安装包文件unzip linux.x64_11gR2_database_1of2.zip && unzip linux.x64_11gR2_database_2of2.zip && ........3.3 创建目录mkdir -p /data/u01/app/oracle/product/11.2.0/dbhome_1 mkdir /data/u01/app/oracle/{oradata,inventory,fast_recovery_area} chown -R oracle:oinstall /data/u01/app/oracle chmod -R 775 /data/u01/app/oracle 3.4 设置 oracle 用户环境变量su - oracle vim .bash_profile #添加以下内容 export ORACLE_BASE=/data/u01/app/oracle export ORACLE_HOME=/data/u01/app/oracle/product/11.2.0/dbhome_1 export ORACLE_SID=orcl export ORACLE_UNQNAME=$ORACLE_SID export PATH=$ORACLE_HOME/bin:$PATH export NLS_LANG=american_america.AL32UTF8 #生效 source .bash_profile3.5 编辑静默安装响应文件cp -R /data/u01/software/database/response/ . && cd response/ vim db_install.rsp #设置以下内容 oracle.install.option=INSTALL_DB_SWONLY ORACLE_HOSTNAME=自己的主机名 UNIX_GROUP_NAME=oinstall INVENTORY_LOCATION=/data/u01/app/oracle/inventory SELECTED_LANGUAGES=en,zh_CN ORACLE_HOME=/data/u01/app/oracle/product/11.2.0/dbhome_1 ORACLE_BASE=/data/u01/app/oracle oracle.install.db.InstallEdition=EE oracle.install.db.DBA_GROUP=dba oracle.install.db.OPER_GROUP=dba DECLINE_SECURITY_UPDATES=true3.6 安装cd /data/u01/software/database/ ./runInstaller -silent -responseFile /home/oracle/response/db_install.rsp -ignorePrereq #当安装界面出现如下信息的时候 打开另一个终端窗口,用root连接 The installation of Oracle Database 11g was successful. Please check '/home/oracle/oraInventory/logs/silentInstall2016-02-04_09-21-13AM.log' for more details. As a root user, execute the following script(s): 1. /home/oracle/oraInventory/orainstRoot.sh 2. /home/oracle/app/oracle/product/11.2.0/dbhome_1/root.sh Successfully Setup Software.3.7 打开终端,以 root 身份登录,执行脚本su - root source .bash_profile sh /data/u01/app/oracle/inventory/orainstRoot.sh sh /data/u01/app/oracle/product/11.2.0/dbhome_1/root.sh3.8 查看监听响应文件配置信息egrep -v "(^#|^$)" /home/oracle/response/netca.rsp #以静默方式配置监听 su - oracle source .bash_profile netca /silent /responsefile /home/oracle/response/netca.rsp3.9 用 Oracle 用户启动su - oracle lsnrctl start netstat -tunlp|grep 1521 #查看监听状态 lsnrctl status #查看监听器配置文件 listener.ora cat $ORACLE_HOME/network/admin/listener.ora3.10 配置以静默方式建立新库,和实例的响应文件vim /home/oracle/response/dbca.rsp 设置以下参数 GDBNAME = "orcl" SID = "orcl" SYSPASSWORD = "SYS 用户密码" SYSTEMPASSWORD = "SYSTEM 用户密码" SYSMANPASSWORD = "sysman" DBSNMPPASSWORD = "dbsnmp" DATAFILEDESTINATION =/data/u01/app/oracle/oradata RECOVERYAREADESTINATION=/data/u01/app/oracle/fast_recovery_area CHARACTERSET = "AL32UTF8" TOTALMEMORY = "6144"3.11 查看建库响应文件配置信息egrep -v "(^#|^$)" /home/oracle/response/dbca.rsp3.12 启用配置,以静默方式建立新库,和实例dbca -silent -responseFile /home/oracle/response/dbca.rsp #查看监听器配置文件 listener.ora cat $ORACLE_HOME/network/admin/listener.ora # listener.ora Network Configuration File: /data/u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora # Generated by Oracle configuration tools. LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = lucky)(PORT = 1521)) ) ) ADR_BASE_LISTENER = /data/u01/app/oracle #查看监听服务名配置文件 tnsnames.ora cat $ORACLE_HOME/network/admin/tnsnames.ora # tnsnames.ora Network Configuration File:/data/u01/app/oracle/product/11.2.0/dbhome_1/network/admin/tnsnames.ora # Generated by Oracle configuration tools. ORCL = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = lucky)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = orcl) ) )3.13 检查实例后台进程ps -ef | grep ora_ | grep -v grep #查看 ORACLE_UNQNAME 环境变量 env|grep ORACLE_UNQNAME lsnrctl stop 以 sysdba 身份登录 sqlplus / as sysdba 启动 oralce 数据库 SQL> shutdown immediate SQL> startup SQL> exit lsnrctl start lsnrctl status3.14 创建用户[oracle@oracal ~]$ sqlplus / as sysdba SQL> conn / as sysdba; SQL> alter user lucky identified by 123456; SQL> alter user lucky account unlock; SQL> conn lucky/123456;PS:如果本地客户端连接提示ora12170或者提示监听有误,去开启下服务器1521端口
-
Oracle-11.2.0.4安装包 找了好多都是收费的,在Google上找了近2个小时,自己下载,百度云也是坑货,我上传倒了OneDrive 上,有梯子哥们走这边,适用于Linux, 如果对你有用希望你留言或者点赞,这样会增加曝光度让更多的人知道软件包:p13390677_112040_Linux-x86-64_1of7.zipp13390677_112040_Linux-x86-64_2of7.zipp13390677_112040_Linux-x86-64_3of7.zipp13390677_112040_Linux-x86-64_4of7.zipp13390677_112040_Linux-x86-64_5of7.zipp13390677_112040_Linux-x86-64_6of7.zipp13390677_112040_Linux-x86-64_7of7.zip下载地址:链接: https://pan.baidu.com/s/1KJnYRHZtUVtg-t-eMXfxmQ 密码: gtk1
-
教程丨官方下载Oracle各版本安装软件及补丁包,包含8i 9i 10g 11g 12c 18c 19c 21c 最近还有一些人在询问到哪里下载 Oracle 数据库软件,故总结一下官方下载 Oracle 软件及补丁的渠道,以及一些注意事项。由于 Oracle 的开放下载政策,Oracle 的软件下载没有任何限制,且与付费版本没有任何区别,可以用来学习和测试,但是如果用于商业生产环境就需要主动向 Oracle 付费购买 license,否则有严重的法律风险,尤其是上市企业。当然 Oracle 也推出了免费版本 XE,不过也有严格的 CPU、内存、容量的限制,详情查看:浅谈 ORACLE 免费数据库 Oracle Database XE (Express Edition) 版。重要-----重要-----重要在开篇特别强调一下,无论从什么渠道下载的软件包一定要验证安装文件的 MD5 或者 SHA 值,确保安装软件与官方提供的软件完全一致,主要有下面两个问题:软件包被篡改植入勒索病毒,尤其是从非官方渠道下载的软件包很有可能带木马。比如云和恩墨在过去几年遇到最多紧急救援的案例:ORA-600 16703 错误的原因和解决方案,就是将恶意代码添加到安装文件,系统上线运行 1000 天后触发木马,勒索比特币。安装包不完整或者损坏,这样会造成多次尝试安装都失败,因为这种情况下的报错或者现象非常异常无法快速定位,可能会浪费大量的时间;另外就是即时安装成功了,软件本身也有隐患,问题可能会在后续暴露出来。官方下载 Oracle 的途径主要是 Oracle 官网、Oracle Delivery 以及 MOS,前两个普通账号即可登录,下载软件的版本也有一定的限制。MOS 需要关联企业 SI 激活,可以下载所有版本的软件以及服务期限内的补丁,部分扩展支持的补丁需要付费下载。导航1、Oracle 官网2、Oracle Delivery3、Oracle MOS3.1 Doc ID 2118136.2Oracle 11204 软件包Oracle 11204 补丁3.2 Patch SearchOracle 11.2.0.4.210420 补丁附 Oracle 11204 安装包 SHA 值1、Oracle 官网Oracle 官方网站,点击 product 找到 database,然后找到下载页面,直达地址如下:https://www.oracle.com/database/technologies/oracle-database-software-downloads.html,目前可以下载 Oracle database 19.5 for solaris,19.3 for all platform,以及 21c 的 x86 下的客户端。20c 由于疫情原因取消发布了,21c 应该会在近期发布。另外在底部也提供了三个 EX 免费版的下载链接:登录之后点击下载 icon 即可直接下载。点击列表中的 See All,可以查看到软件包的 sha256sum 值,再与本地安装包进行确认。 2、Oracle Delivery第 2 个地方就是 Oracle Software Delivery Cloud,这个也是官方渠道,Oracle 的绝大多数软件都可以在这里下载:https://edelivery.oracle.com,注册登录之后即可,虽然比官网直接下载要多一些,但是还是有一些限制,比如 Oracle 11204 只有 HP OpenVMS Itanium 平台的。然后下拉选择 DLP,输入要下载的软件,在下拉候选中选择相应的版本,然后点击搜索。点击选择需要下载的版本加入到下载队列中,可以通过右上角的 view items 查看,然后点击 continue 进入确认页面。勾选需要下载的软件包,是数据库、还是 client,还是集群,右侧选择对应的平台,然后点击右上角 continue,勾选同意 Oracle 许可协议,继续点击 continue 进入下载页面。直接依次点击左侧的 zip 文件名即可直接下载,不需要点击 download 按钮(如果点击会先安装一个 Oracle 下载器,然后统一下载),通过右上角的 show digest details 按钮显示安装包的 SHA 值并保持下来,待安装时比对确认。 3、Oracle MOS也就是 My Oracle Support(之前叫 metalink),这个需要企业或组织购买了 Oracle 的官方服务才可以开通,直接找管理员申请即可,开通之后即可下载除部分扩展支持外的软件和补丁。另外,MOS 还有一个重要的功能就是开 SR,也就是遇到问题可以找原厂的工程师甚至研发人员帮你解决。MOS 上介绍两种途径,一种是根据《Assistant: Download Reference for Oracle Database/GI Update, Revision, PSU, SPU(CPU), Bundle Patches, Patchsets and Base Releases (Doc ID 2118136.2)》文档导航指引直接下载,另外一种方法就是 MOS 上有一个 Patches and Updates 搜索的位置。3.1 Doc ID 2118136.2《Assistant: Download Reference for Oracle Database/GI Update, Revision, PSU, SPU(CPU), Bundle Patches, Patchsets and Base Releases (Doc ID 2118136.2)》该文档也是用得最多的,有快捷的指引,分类如下:Oracle Database Base ReleasesOracle Database PatchsetsOracle Database Updates (Versions 12.2 & higher)Oracle Database Update Revisions (Versions 12.2 & higher)Oracle Database PSU, SPU(CPU), Bundle Patches (Versions 12.1 & lower)OJVM Update/PSU/Bundle PatchesLatest Available Microsoft Windows Patches比如我们要下载 Oracle 11204 for Linux x86_64 安装包以及 11.2.0.4.201020 的 PSU。Oracle 11204 软件包左侧选择 Oracle Database Patchsets,然后点击 Patchsets ID 13390677。再次点击进入下载页面。点击右侧的download按钮,弹出下载框。点击文件名即可下载。同样通过show digest details显示sha-256值并记录。Oracle 11204 补丁左侧依次选择 Oracle Database PSU, SPU(CPU), Bundle Patches (Versions 12.1 & lower)和 11.2.0.4,点击 31537677 进入下载页面。重复上面的操作即可下载201020的PSU。3.2 Patch Search在 MOS 中有一个搜索安装包和补丁的功能,可以通过 ID 来搜,也可以模糊搜索。Oracle 11.2.0.4.210420 补丁比如我们要查询 Oracle 11204 最新的补丁,勾选 include all products in a family 搜索。 进入之后发现无法下载,Oracle 11204在2020年已经扩展支持,需要付费才可下载。如果实在需要,可联系O记客户经理或者尝试通过SR索取。以上列举了官方渠道的下载方式,下载速度还是不错的,千兆电信宽带基本上2M/s,几分钟即可下载完成,呼吁大家尽量在官方渠道下载,如果是其他渠道下载切记验证安装包,一般11204这个版本被篡改的较多,末尾附上Windows和Linux安装包的SHA-256值。附 Oracle 11204 安装包 SHA 值软件包名大小SHA-256p13390677_112040_MSWIN-x86-64_1of7.zip1.2 GB9C6E1235D1B0EE6C36E3F82FEBDC74160BB9766900579FC7EBBFACECD6E8F4B2p13390677_112040_MSWIN-x86-64_2of7.zip1.1 GB6343B2EA4F47C4E85FD4DC1B5C2EA0B86294E48FAD90DE1820C3F9DF906675F3p13390677_112040_MSWIN-x86-64_3of7.zip735.0 MBEC47CFF4D500BD357982C57D9F84F893293A3DBB79A62FC7AE66E2144BEFFF6Cp13390677_112040_Linux-x86-64_1of7.zip1.3 GB0B399A6593804C04B4BD65F61E73575341A49F8A273ACABA0DCDA2DFEC4979E0p13390677_112040_Linux-x86-64_2of7.zip1.1 GB73E04957EE0BF6F3B3E6CFCF659BDF647800FE52A377FB8521BA7E3105CCC8DDp13390677_112040_Linux-x86-64_3of7.zip1.1 GB09C08AD3E1EE03DB1707F01C6221C7E3E75EC295316D0046CC5D82A65C7B928C本文转载至:教程丨官方下载Oracle各版本安装软件及补丁包,包含8i 9i 10g 11g 12c 18c 19c 21c
-
Docker部署 Mysql、redis、Rabbitmq、Vue、Java 项目 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux 或 Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。本文主要讲解如何在Linux环境下使用 Docker 部署前后端分离项目,其中涉及到使用 Docker 安装本人项目相关的一些环境 ,例如mysql、rabbitmq、redis,基于CenterOS7.0。Docker 环境安装1.安装 Docker 客户端# step 1: 安装必要的一些系统工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # Step 2: 添加软件源信息 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # Step 3: 更新并安装 Docker-CE sudo yum makecache fast sudo yum -y install docker-ce # Step 4: 开启Docker服务 sudo service docker start2.配置镜像加速器sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://sq2b0kv9.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker安装 PortainerPortainer 是一个轻量级 Web 端的 Docker 管理 UI,Portainer 够轻松地管理不同的 Docker 环境(Docker 主机或集群)。Portainer 的部署和使用十分简单。Portainer 可以部署为 Linux 容器或 Windows 本机容器,也支持其他平台。Portainer 允许您管理所有 Docker 资源(容器、映像、卷、网络等)!它与独立的 Docker 引擎和 Docker 集群模式兼容。1.安装# 拉取官方镜像 docker pull portainer/portainer # 运行镜像到容器 docker run -d -p 9000:9000\ --restart=always\ -v /var/run/docker.sock:/var/run/docker.sock\ -m 20M --oom-kill-disable --memory-swap=-1\ --name portainer\ portainer/portainer2.访问页面访问地址:http://localhost:9000,第一次打开需要设置用户名、密码,docker 模式我一般选择 Local 本机模式。通过此工具我们可以更加简便的对镜像和容器进行操作和管理。登录页 面板页 安装 mysql# docker search mysql 可通过此命令查看可用版本 # 拉取mysql镜像,默认会拉取最新版本,我这里加上版本号 docker pull mysql:8.0.0 # 查看镜像是否拉取成功 docker images # 在/home/docker/mysql目录下创建mysql挂载目录 mkdir {data,logs,conf} # 运行容器 docker run -d -p 3306:3306 -v /home/docker/mysql/my.cnf:/etc/mysql/conf.d/mysqld.cnf -v /home/docker/mysql/data:/var/lib/mysql -v /home/docker/mysql/logs:/var/log/mysql -e MYSQL_ROOT_PASSWORD=12345 --name mysql_test mysql:8.0.0说明:--name:容器名-e:配置信息,此处配置 mysql 的 root 用户登陆密码-d:后台运行容器,保证在退出终端后容器继续运行-p:端口映射,此处映射 主机 3306 端口 到 容器的 3306 端口-v:挂载目录此处需要注意不要直接挂载容器中的 mysql 配置文件目录,可能会将容器内的配置文件目录清空。个人建议将容器中的 my.cnf 文件复制出来进行选择性的修改,再挂载 mysql.cnf 文件即可。docker cp :用于容器与主机之间的数据拷贝。# 语法 docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|- # 实例 docker cp 96f7f14e99ab:/etc/mysql/conf.d/mysqld.cnf /home/docker/mysql/my.cnf安装 redis因为 redis 默认配置只能够本地连接,不能进行远程访问,使用 Redis 客户端工具连接都会报错,因此需要手动挂载 redis 配置文件。# /home/docker/redis目录下新增挂载文件夹 mkdir {data,conf} # 下载最新版本的Redis镜像 docker pull redis # 新增redis配置文件 cd /home/docker/redis/conf touch redis.conf vim redis.conf添加以下内容#bind 127.0.0.1 protected-mode no appendonly yes requirepass 123456说明:bind 127.0.0.1 ,注释掉这部分,这是限制 redis 只能本地访问protected-mode:默认 yes,开启保护模式,限制为本地访问appendonly:redis 持久化(可选)requirepass:设置访问密码为 123456运行容器docker run --name myredis -p 6379:6379 -v /home/docker/redis/data:/data -v /home/docker/redis/conf/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf说明:--name:容器名称-p :表示将服务器的 6379(冒号前的 6379)端口映射到 docker 的 6379(冒号后的 6379)端口-d :表示以后台服务的形式运行 redis-v :挂载宿主机目录redis redis-server /etc/redis/redis.conf:表示运行 redis 服务器程序,并且指定运行时的配置文件经过以上步骤,便可以通过 redis 客户端工具进行连接,如果连接不上,检查安全组和服务器防火墙端口是否开放安装 rabbitmq# 拉取带图形化管理界面的镜像 docker pull rabbitmq:3.7.7-management # 根据下载的镜像创建和启动容器 docker run -d --name rabbitmq3.7.7 -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq --hostname myRabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin df80af9ca0c9说明:-d:后台运行容器;--name:指定容器名;-p:指定服务运行的端口(5672:应用访问端口;15672:控制台 Web 端口号);-v:映射目录或文件;--hostname :主机名(RabbitMQ 的一个重要注意事项是它根据所谓的 “节点名称” 存储数据,默认为主机名);-e:指定环境变量;(RABBITMQ_DEFAULT_VHOST:默认虚拟机名;RABBITMQ_DEFAULT_USER:默认的用户名;RABBITMQ_DEFAULT_PASS:默认用户名的密码)Rabbitmq 访问地址:http://localhost:15672 至此,基本的运行环境都安装完毕,下面就是关键的打包步骤了。Vue 前端项目打包将 dist 下的所有文件目录拷贝到 SpringBoot 后端项目的 resources\static 目录下,static 目录需要新建。如果你的项目中用到了 shiro 或者 spring security 等安全框架,需要对静态资源放行。以上配置完成后,先在本地运行,再用 maven 进行打包。将 jar 包上传到服务器后,就要开始制作自己的镜像了,首先在与 jar 包同目录下新建 Dockerfile 文件。# 新建Dockerfile文件 touch Dockerfile # 编写Dockerfile文件 vim Dockerfile加入以下内容# Docker image for springboot file run # VERSION 0.0.1 FROM java:8 # VOLUME 指定了临时文件目录为/tmp。 # 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp VOLUME /tmp # 将jar包添加到容器中并更名为app.jar ADD demo-01.jar app.jar # 运行jar包 RUN bash -c 'touch /app.jar' ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]执行 docker build -t [镜像名称] . ,至此镜像文件就制作完成了。docker images查看镜像是否存在。最后一步,创建并启动容器,docker run --name [容器名称] -d -p 80:8080 [镜像名]。
-
Mysql 创建用户,指定数据库 1.远程登录 mysqlmysql -h ip -u root -p 密码2.创建用户格式:grant 权限 on 数据库.* to 用户名@登录主机 identified by “密码”;例 1:增加一个 test1 用户,密码为 123456,可以在任何主机上登录,并对所有数据库有查询,增加,修改和删除的功能。需要在 mysql 的 root 用户下进行mysql>grant select,insert,update,delete on *.* to test1@'%' identified by '123456'; mysql>flush privileges;例 2:增加一个 test2 用户,密码为 123456,只能在 192.168.2.12 上登录,并对数据库 student 有查询,增加,修改和删除的功能。需要在 mysql 的 root 用户下进行mysql>grant select,insert,update,delete on student.* to test2@192.168.2.12 identified by '123456'; mysql>flush privileges;例 3:授权用户 test3 拥有数据库 student 的所有权限mysql>grant all privileges on student.* to test3@localhost identified by ’123456′; mysql>flush privileges;3.修改用户密码mysql>update mysql.user set password=password(’123456′) where User=’test1′ and Host=’localhost’; mysql>flush privileges;4.删除用户mysql>delete from user where user=’test2′ and host=’localhost’; mysql>flush privileges;5.删除数据库和删除表mysql>drop database 数据库名; mysql>drop table 表名;6.删除账户及权限drop user 用户名@’%’ drop user 用户名@localhostgrant 详细解析如下:MySQL 赋予用户权限命令的简单格式可概括为: grant 权限 on 数据库对象 to 用户 一、grant 普通数据用户,查询、插入、更新、删除 数据库中所有表数据的权利。grant select on testdb.* to common_user@'%'; grant insert on testdb.* to common_user@'%'; grant update on testdb.* to common_user@'%'; grant delete on testdb.* to common_user@'%';或者,用一条 MySQL 命令来替代:grant select, insert, update, delete on testdb.* to common_user@'%'二、grant 数据库开发人员,创建表、索引、视图、存储过程、函数。。。等权限。grant 创建、修改、删除 MySQL 数据表结构权限。grant create on testdb.* to developer@'192.168.0.%'; grant alter on testdb.* to developer@'192.168.0.%'; grant drop on testdb.* to developer@'192.168.0.%';grant 操作 MySQL 外键权限。grant references on testdb.* to developer@'192.168.0.%';grant 操作 MySQL 临时表权限。grant create temporary tables on testdb.* to developer@'192.168.0.%';grant 操作 MySQL 索引权限。grant index on testdb.* to developer@'192.168.0.%';grant 操作 MySQL 视图、查看视图源代码 权限。grant create view on testdb.* to developer@'192.168.0.%'; grant show view on testdb.* to developer@'192.168.0.%';grant 操作 MySQL 存储过程、函数 权限。grant create routine on testdb.* to developer@'192.168.0.%'; — now, can show procedure status grant alter routine on testdb.* to developer@'192.168.0.%'; — now, you can drop a procedure grant execute on testdb.* to developer@'192.168.0.%';三、grant 普通 DBA 管理某个 MySQL 数据库的权限。grant all privileges on testdb to dba@'localhost'其中,关键字 “privileges” 可以省略。四、grant 高级 DBA 管理 MySQL 中所有数据库的权限。grant all on *.* to dba@'localhost'五、MySQL grant 权限,分别可以作用在多个层次上。grant 作用在整个 MySQL 服务器上:grant select on _._ to dba@localhost; — dba 可以查询 MySQL 中所有数据库中的表。 grant all on _._ to dba@localhost; — dba 可以管理 MySQL 中的所有数据库grant 作用在单个数据库上:grant select on testdb.\* to dba@localhost; — dba 可以查询 testdb 中的表。grant 作用在单个数据表上:grant select, insert, update, delete on testdb.orders to dba@localhost;grant 作用在表中的列上:grant select(id, se, rank) on testdb.apache_log to dba@localhost;grant 作用在存储过程、函数上:grant execute on procedure testdb.pr_add to dba@localhost; grant execute on function testdb.fn_add to dba@localhost;六、查看 MySQL 用户权限查看当前用户(自己)权限:show grants;查看其他 MySQL 用户权限:show grants for dba@localhost;七、撤销已经赋予给 MySQL 用户权限的权限。revoke 跟 grant 的语法差不多,只需要把关键字 “to” 换成 “from” 即可:grant all on *.* to dba@localhost; revoke all on *.* from dba@localhost;八、MySQL grant、revoke 用户权限注意事项grant, revoke 用户权限后,该用户只有重新连接 MySQL 数据库,权限才能生效。如果想让授权的用户,也可以将这些权限 grant 给其他用户,需要选项 “grant option“grant select on testdb.\* to dba@localhost with grant option;这个特性一般用不到。实际中,数据库权限最好由 DBA 来统一管理。=========================================================1.创建用户并授权grant 语句的语法:grant privileges (columns) on what to user identified by “password” with grant option要使用该句型,需确定字段有: privileges 权限指定符权限允许的操作 alter 修改表和索引 create 创建数据库和表 delete 删除表中已有的记录 drop 抛弃(删除)数据库和表 index 创建或抛弃索引 insert 向表中插入新行 reference 未用 select 检索表中的记录 update 修改现存表记录 file 读或写服务器上的文件 process 查看服务器中执行的线程信息或杀死线程 reload 重载授权表或清空日志、主机缓存或表缓存。 shutdown 关闭服务器 all 所有; all privileges同义词 usage 特殊的“无权限”权限以上权限分三组: 第一组:适用于数据库、表和列如:alter create delete drop index insert select update 第二组:数管理权限 它们允许用户影响服务器的操作 需严格地授权 如:file process reload shut* 第三组:权限特殊 all 意味着“所有权限” uasge 意味着无权限,即创建用户,但不授予权限 columns 权限运用的列(可选)并且你只能设置列特定的权限。如果命令有多于一个列,应该用逗号分开它们。 what 权限运用的级别。权限可以是全局,定数据库或特定表. user 权限授予的用户,由一个用户名和主机名组成,许两个同名用户从不同地方连接.缺省:mysql用户password赋予用户的口令(可选),如果你对用户没有指定 identified by 子句,该用户口令不变. 用 identified by 时,口令字符串用改用口令的字面含义,grant 将为你编码口令.注:set password使用password()函数with grant option用户可以授予权限通过 grant 语句授权给其它用户(可选) 实例讲解:grant all on db_book.* to test@kk.com identified by '123456' 只能在本地连接 grant all on db_book.* to test@vpn.kk.com identified by '123456' 允许从此域连接 grant all on db_book.* to test@% identified by '123456' 允许从任何主机连接 注:”%”字符起通配符作用,与like模式匹配的含义相同。 grant all on db_book.* to test@%.kk.com identified by '123456'; 允许test从kk.com域的任何主机连接 grant all on db_book.* to test@192.168.1.189 identified by '123456' grant all on db_book.* to test@192.168.1.% identified by '123456' grant all on db_book.* to test@192.168.1.0/17 identified by '123456'允许从单 IP 段 IP 或一子网 IP 登陆 注:有时 用户@IP 需用引号 如 ‘test@192.168.1.0/17’grant all on *.* to test@localhost identified by '123456' with grant option添加超级用户 admin 可在本地登陆做任何操作.grant reload on *.* to admin@localhost identified by '123456'; 只赋予reload权限 grant all on db_book to admin@kk.com indetified by '123456'; 所有权限 grant select on db_book to admin@% indetified by '123456'; 只读权限 grant select,insert,delete,update on db_book to admin@kk.com indetified by '123456'; 只有select,insert,delete,update的权限 grant select on db_book.storybook to admin@localhost indetified by '123456'; 只对表 grant update(name) on db_book.storybook to admin@localhost; 只对表的name列 密码不变 grant update(id,name,author) on db_book.storybook to admin@localhost; 只对表的多列 grant all on book.* to ''@kk.com; 允许kk.com域中的所有用户使用库book grant all on book.* to admin@%.kk.com indetified by '123456' with grant option; 允许admin对库book所有表的管理员授权.2.撤权并删除用户 revoke的语法类似于grant语句 to用from取代,没有indetifed by和with grant option子句. 如下: revoke privileges (columns) on what from user user:必须匹配原来grant语句的你想撤权的用户的user部分。 privileges:不需匹配,可以用grant语句授权,然后用revoke语句只撤销部分权限。 revoke语句只删权限不删用户,撤销了所有权限后user表中用户记录保留,用户仍然可以连接服务器. 要完全删除一个用户必须用一条delete语句明确从user表中删除用户记录: delete from user where user=”admin” flush privileges; 重载授权表注:使用 grant 和 revoke 语句时,表自动重载,而你直接修改授权表时不是.实例:1.创建数据库CREATE DATABASE `fypay` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;2.为创建的数据库增加用户 fypaygrant create,select,insert,update,delete,drop,alter on fypay.* to fypay@”%” identified by “testfpay”;3.删除 fypay 用户delete from user where user=”fypay” drop user fypay@localhost4.刷新数据库flush privileges;
-
Windows下搭建Redis集群的方法步骤 Windows下搭建Redis集群的方法步骤本文主要介绍了Windows下搭建Redis集群的方法步骤,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下目录Redis集群:在Windows系统下搭建Redis集群:1.下载并安装Redis2.下载并安装ruby3.创建Redis集群Redis集群:如果部署到多台电脑,就跟普通的集群一样;因为Redis是单线程处理的,多核CPU也只能使用一个核,所以部署在同一台电脑上,通过运行多个Redis实例组成集群,然后能提高CPU的利用率。在Windows系统下搭建Redis集群:需要4个部件:Redis、Ruby语言运行环境、Redis的Ruby驱动redis-xxxx.gem、创建Redis集群的工具redis-trib.rb安装Redis,并运行3个实例(Redis集群需要至少3个以上节点,低于3个无法创建);使用redis-trib.rb工具来创建Redis集群,由于该文件是用ruby语言写的,所以需要安装Ruby开发环境,以及驱动redis-xxxx.gem1.下载并安装Redis其GitHub路径如下:https://github.com/MSOpenTech/redis/releases/Redis提供msi和zip格式的下载文件,这里下载zip格式 3.0.504版本将下载到的Redis-x64-3.0.504.zip解压即可,为了方便使用,建议放在盘符根目录下,并修改目录名为Redis,如:C:\Redis 或者D:\Redis 通过配置文件来启动3个不同的Redis实例,由于Redis默认端口为6379,所以这里使用了6380、6381、6382来运行3个Redis实例。注意:为了避免不必要的错误,配置文件尽量保存为utf8格式,并且不要包含注释;配置文件中以下两种保存日志的方式(保存在文件中、保存到System Log中)请根据需求选择其中一种即可:loglevel notice #日志的记录级别,notice是适合生产环境的 logfile "D:/Redis/Logs/redis6380_log.txt" #指定log的保持路径,默认是创建在Redis安装目录下,如果有子目录需要手动创建,如此处的Logs目录 syslog-enabled yes #是否使用系统日志 syslog-ident redis6380 #在系统日志的标识名这里使用了保存在文件中的方式,所以先在Redis目录D:/Redis下新建Logs文件夹[/code]redis.6380.conf 内容如下:port 6380 loglevel notice logfile "D:/Redis/Logs/redis6380_log.txt" appendonly yes appendfilename "appendonly.6380.aof" cluster-enabled yes cluster-config-file nodes.6380.conf cluster-node-timeout 15000 cluster-slave-validity-factor 10 cluster-migration-barrier 1 cluster-require-full-coverage yesredis.6381.conf 内容如下:port 6381 loglevel notice logfile "D:/Redis/Logs/redis6381_log.txt" appendonly yes appendfilename "appendonly.6381.aof" cluster-enabled yes cluster-config-file nodes.6381.conf cluster-node-timeout 15000 cluster-slave-validity-factor 10 cluster-migration-barrier 1 cluster-require-full-coverage yesredis.6382.conf 内容如下:port 6382 loglevel notice logfile "D:/Redis/Logs/redis6382_log.txt" appendonly yes appendfilename "appendonly.6382.aof" cluster-enabled yes cluster-config-file nodes.6382.conf cluster-node-timeout 15000 cluster-slave-validity-factor 10 cluster-migration-barrier 1 cluster-require-full-coverage yes配置内容的解释如下:port 6380 #端口号 loglevel notice #日志的记录级别,notice是适合生产环境的 logfile "Logs/redis6380_log.txt" #指定log的保持路径,默认是创建在Redis安装目录下,如果有子目录需要手动创建,如此处的Logs目录 syslog-enabled yes #是否使用系统日志 syslog-ident redis6380 #在系统日志的标识名 appendonly yes #数据的保存为aof格式 appendfilename "appendonly.6380.aof" #数据保存文件 cluster-enabled yes #是否开启集群 cluster-config-file nodes.6380.conf cluster-node-timeout 15000 cluster-slave-validity-factor 10 cluster-migration-barrier 1 cluster-require-full-coverage yes将上述配置文件保存到Redis目录下,并使用这些配置文件安装3个redis服务,命令如下:注意:redis.6380.conf等配置文件最好使用完整路径,避免重启Redis集群出现问题,博主的安装目录为D:/RedisD:/Redis/redis-server.exe --service-install D:/Redis/redis.6380.conf --service-name redis6380 D:/Redis/redis-server.exe --service-install D:/Redis/redis.6381.conf --service-name redis6381 D:/Redis/redis-server.exe --service-install D:/Redis/redis.6382.conf --service-name redis6382启动这3个服务,命令如下:D:/Redis/redis-server.exe --service-start --service-name Redis6380 D:/Redis/redis-server.exe --service-start --service-name Redis6381 D:/Redis/redis-server.exe --service-start --service-name Redis6382执行结果:2.下载并安装ruby2.1. 下载路径如下:http://dl.bintray.com/oneclick/rubyinstaller/rubyinstaller-2.2.4-x64.exe下载后,双击安装即可,同样,为了操作方便,也是建议安装在盘符根目录下,如: C:\Ruby22-x64 ,安装时这里选中后两个选项,意思是将ruby添加到系统的环境变量中,在cmd命令中能直接使用ruby的命令2.2.下载ruby环境下Redis的驱动,考虑到兼容性,这里下载的是3.2.2版本https://rubygems.org/gems/redis/versions/3.2.2注意:下载在页面右下角相关连接一项中安装该驱动,命令如下:gem install --local path_to_gem/filename.gem实际操作如下:2.3.下载Redis官方提供的创建Redis集群的ruby脚本文件redis-trib.rb,路径如下:https://raw.githubusercontent.com/MSOpenTech/redis/3.0/src/redis-trib.rb打开该链接如果没有下载,而是打开一个页面,那么将该页面保存为redis-trib.rb建议保存到Redis的目录下。注意:因为redis-trib.rb是ruby代码,必须用ruby来打开,若redis-trib.rb无法识别,需要手动选择该文件的打开方式:**选择ruby为的打开方式后,redis-trib.rb的logo都会发生改变,如下图:3.创建Redis集群CMD下切换到Redis目录,使用redis-trib.rb来创建Redis集群:redis-trib.rb create --replicas 0 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 执行结果:当出现提示时,需要手动输入yes,输入后,当出现以下内容,说明已经创建了Redis集群检验是否真的创建成功,输入以下命令:redis-trib.rb check 127.0.0.1:6380出现以下信息,说明创建的Redis集群是没问题的使用Redis客户端Redis-cli.exe来查看数据记录数,以及集群相关信息D:/Redis/redis-cli.exe -c -p 6380-c 表示 cluster-p 表示 port 端口号输入dbsize查询 记录总数dbsize或者一次输入完整命令:D:/Redis/redis-cli.exe -c -p 6380 dbsize结果如下:输入cluster info可以从客户端的查看集群的信息:cluster info结果如下: 到此这篇关于Windows下搭建Redis集群的方法步骤的文章就介绍到这了。