搜索到
43
篇与
的结果
-
 面试官:从 MySQL 读取 百万 数据进行处理,应该怎么做?问倒一大片! 背景大数据量操作的场景大致如下:数据迁移数据导出批量处理数据在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。但有些情况不需要分页的方式查询数据或分很大一页查询数据时,如果一下子将数据全部加载出来到内存中,很可能会发生 OOM(内存溢出) ;而且查询会很慢,因为框架耗费大量的时间和内存去把数据库查询的结果封装成我们想要的对象(实体类)。举例:在业务系统需要从 MySQL 数据库里读取 100万 数据行进行处理,应该怎么做? 做法通常如下:常规查询:一次性读取 100万 数据到 JVM 内存中,或者分页读取流式查询:建立长连接,利用服务端游标,每次读取一条加载到 JVM 内存(多次获取,一次一行)游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据(多次获取,一次多行)常规查询默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于 MySQL 网络协议的设计,因此更易于实现。举例:假设单表 100万 数据量,一般会采用分页的方式查询:@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); }注:该示例使用的 MybatisPlus。该方式比较简单,如果在不考虑 LIMIT 深分页优化情况下,估计你的数据库服务器就噶皮了,或者你能等上几十分钟或几小时,甚至几天时间检索数据。流式查询流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 100万 条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。MyBatis 流式查询接口 MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:Cursor 是可关闭的;Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed():用于判断查询结果是否全部取完。getCurrentIndex():返回已经获取了多少条数据使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理为什么要用流式查询? 如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了 sharding-sphere 的代码不难发现,除了 group by 与 order by 字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。游标查询对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。这种处理方式比常规查询要快很多。当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。Mybatis 的处理加了两个注解: @Options 和 @ResultType@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { // 方式一 多次获取,一次多行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000) Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); // 方式二 一次获取,一次一行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000) @ResultType(BigDataSearchEntity.class) void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler); }@OptionsResultSet.FORWORD_ONLY:结果集的游标只能向下滚动ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变fetchSize:每次获取量@ResultType@ResultType(BigDataSearchEntity.class):转换成返回实体类型注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。注意: 虽然上面的代码中都有 @Options 但实际操作却有不同:方式一是多次查询,一次返回多条;方式二是一次查询,一次返回一条;原因: Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。非流式查询和流式查询区别:非流式查询:内存会随着查询记录的增长而近乎直线增长。流式查询:内存会保持稳定,不会随着记录的增长而增长。其内存大小取决于批处理大小BATCH_SIZE的设置,该尺寸越大,内存会越大。所以BATCH_SIZE应该根据业务情况设置合适的大小。另外要切记每次处理完一批结果要记得释放存储每批数据的临时容器,即上文中的 gxids.clear() ;
面试官:从 MySQL 读取 百万 数据进行处理,应该怎么做?问倒一大片! 背景大数据量操作的场景大致如下:数据迁移数据导出批量处理数据在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。但有些情况不需要分页的方式查询数据或分很大一页查询数据时,如果一下子将数据全部加载出来到内存中,很可能会发生 OOM(内存溢出) ;而且查询会很慢,因为框架耗费大量的时间和内存去把数据库查询的结果封装成我们想要的对象(实体类)。举例:在业务系统需要从 MySQL 数据库里读取 100万 数据行进行处理,应该怎么做? 做法通常如下:常规查询:一次性读取 100万 数据到 JVM 内存中,或者分页读取流式查询:建立长连接,利用服务端游标,每次读取一条加载到 JVM 内存(多次获取,一次一行)游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据(多次获取,一次多行)常规查询默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于 MySQL 网络协议的设计,因此更易于实现。举例:假设单表 100万 数据量,一般会采用分页的方式查询:@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); }注:该示例使用的 MybatisPlus。该方式比较简单,如果在不考虑 LIMIT 深分页优化情况下,估计你的数据库服务器就噶皮了,或者你能等上几十分钟或几小时,甚至几天时间检索数据。流式查询流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 100万 条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。MyBatis 流式查询接口 MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:Cursor 是可关闭的;Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed():用于判断查询结果是否全部取完。getCurrentIndex():返回已经获取了多少条数据使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理为什么要用流式查询? 如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了 sharding-sphere 的代码不难发现,除了 group by 与 order by 字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。游标查询对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。这种处理方式比常规查询要快很多。当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。Mybatis 的处理加了两个注解: @Options 和 @ResultType@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { // 方式一 多次获取,一次多行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000) Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); // 方式二 一次获取,一次一行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000) @ResultType(BigDataSearchEntity.class) void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler); }@OptionsResultSet.FORWORD_ONLY:结果集的游标只能向下滚动ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变fetchSize:每次获取量@ResultType@ResultType(BigDataSearchEntity.class):转换成返回实体类型注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。注意: 虽然上面的代码中都有 @Options 但实际操作却有不同:方式一是多次查询,一次返回多条;方式二是一次查询,一次返回一条;原因: Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。非流式查询和流式查询区别:非流式查询:内存会随着查询记录的增长而近乎直线增长。流式查询:内存会保持稳定,不会随着记录的增长而增长。其内存大小取决于批处理大小BATCH_SIZE的设置,该尺寸越大,内存会越大。所以BATCH_SIZE应该根据业务情况设置合适的大小。另外要切记每次处理完一批结果要记得释放存储每批数据的临时容器,即上文中的 gxids.clear() ; -
Jenkins+Docker 实现一键自动化部署项目!步骤齐全,少走坑路 本文章实现最简单全面的 Jenkins+docker+springboot 一键自动部署项目,步骤齐全,少走坑路。环境:Centos7+Git(Gitee)简述实现步骤:在 docker 安装 jenkins,配置 jenkins 基本信息,利用 Dockerfile 和 shell 脚本实现项目自动拉取打包并运行。安装 dockerdocker 安装社区版本 CE确保 yum 包更新到最新。yum update卸载旧版本(如果安装过旧版本的话)yum remove docker docker-common docker-selinux docker-engine安装需要的软件包yum install -y yum-utils device-mapper-persistent-data lvm2设置 yum 源yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo安装 dockeryum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0 yum install <自己的版本> # 例如:sudo yum install docker-ce-17.12.0.ce启动和开机启动systemctl start docker systemctl enable docker验证安装是否成功docker version安装 JenkinsJenkins 中文官网安装 Jenkinsdocker 安装一切都是那么简单,注意检查 8080 是否已经占用!如果占用修改端口docker run --name jenkins -u root --rm -d -p 8080:8080 -p 50000:50000 -v /var/jenkins_home:/var/jenkins_home -v /var/run/docker.sock:/var/run/docker.sock jenkinsci/blueocean如果没改端口号的话安装完成后访问地址=> http://{部署Jenkins所在服务IP}:8080此处会有几分钟的等待时间。初始化 Jenkins详情见官网教程=> https://www.jenkins.io解锁 Jenkins进入 Jenkins 容器:docker exec -it {Jenkins容器名} bash # 例如 `docker exec -it jenkins bash`查看密码:cat /var/lib/jenkins/secrets/initialAdminPassword复制密码到输入框里面安装插件选择第一个:安装推荐的插件创建管理员用户此账户一定要记住哦系统配置安装需要插件进入【首页】–【系统管理】–【插件管理】–【可选插件】搜索以下需要安装的插件,点击安装即可。安装 Maven Integration安装 Publish Over SSH(如果不需要远程推送,不用安装)如果使用 Gitee 码云,安装插件 Gitee(Git 自带不用安装)配置 Maven进入【首页】–【系统管理】–【全局配置】,拉到最下面 maven–maven 安装创建任务新建任务点击【新建任务】,输入任务名称,点击构建一个自由风格的软件项目源码管理点击【源码管理】–【Git】,输入仓库地址,添加凭证,选择好凭证即可。构建触发器点击【构建触发器】–【构建】–【增加构建步骤】–【调用顶层Maven目标】–【填写配置】–【保存】此处命令只是 install,看是否能生成 jar 包clean install -Dmaven.test.skip=true保存点击【保存】按钮即可测试该功能测试是否能正常打包构建查看日志点击正在构建的任务,或者点击任务名称,进入详情页面,查看控制台输出,看是否能成功打成 jar 包。该处日志第一次可能下载依赖 jar 包失败,再次点击构建即可成功。查看项目位置cd /var/jenkins_home/workspacell 命令即可查看是否存在运行项目因为我们项目和 jenkins 在同一台服务器,所以我们用 shell 脚本运行项目,原理既是通过 dockerfile 打包镜像,然后 docker 运行即可。Dockerfile在 springboot 项目根目录新建一个名为 Dockerfile 的文件,注意没有后缀名,其内容如下:(大致就是使用 jdk8,把 jar 包添加到 docker 然后运行 prd 配置文件)FROM jdk:8 VOLUME /tmp ADD target/zx-order-0.0.1-SNAPSHOT.jar app.jar EXPOSE 8888 ENTRYPOINT ["Bash","-DBash.security.egd=file:/dev/./urandom","-jar","/app.jar","--spring.profiles.active=prd"]修改 jenkins 任务配置配置如下:-t:指定新镜像名.:表示Dockfile在当前路径cd /var/jenkins_home/workspace/zx-order-api docker stop zx-order || true docker rm zx-order || true docker rmi zx-order || true docker build -t zx-order . docker run -d -p 8888:8888 --name zx-order zx-order:latest备注:我上图用了 docker logs -f 是为了方便看日志,真实不要用,因为会一直等待日志,构建任务会失败加|| true 是如果命令执行失败也会继续实行,为了防止第一次没有该镜像报错保存点击 保存 即可构建查看 jenkins 控制台输出,输出如下,证明成功!验证docker ps 查看是否有自己的容器 docker logs 自己的容器名 查看日志是否正确浏览器访问项目试一试
-
顶级Javaer都在使用的类库,真香! 1.日志库2.JSON 解析库3.单元测试库4.通用库5.HTTP 库6.XML 解析库7.Excel 阅读库8.字节码库9.数据库连接池库10.消息库11.PDF 库12.日期和时间库13.集合库14.电子邮件 API15.HTML 解析库16.密码库17.嵌入式 SQL 数据库库18.JDBC 故障排除库19.序列化库20.网络库优秀且经验丰富的 Java 开发人员的特点之一是对 API 的广泛了解,包括 JDK 和第三方库。如何使用现有的 API 进行开发,而不是为常见的东西编写新的代码。是提升开发效率必选之路。一般来说,我会为日常项目提供有用的库,包括 Log4j 等日志库、Jackson 等 JSON 解析库以及 JUnit 和 Mockito 等单元测试 API。如果您需要在项目中使用它们,则可以在项目的类路径中包含这些库的 JAR 以开始使用它们,也可以使用 Maven 进行依赖管理。对 Java 程序员有用的开源库下面是收集的一些有用的第三方库,Java 开发人员可以在他们的应用程序中使用它们来完成很多有用的任务。为了使用这些库,Java 开发人员应该熟悉这一点,这就是本文的重点。如果您有一个想法,那么您可以研究该库并使用它。1. 日志库日志库非常常见,因为您在每个项目中都需要它们。它们对于服务器端应用程序来说是最重要的,因为日志只放置在您可以看到应用程序正在发生什么的地方。尽管 JDK 附带了自己的日志库,但仍有更好的替代方案可用,例如 Log4j、SLF4j 和 LogBack。Java 开发人员应该熟悉日志库的优缺点,并知道为什么使用 SLF4j 比普通的 Log4j 更好。2. JSON 解析库在当今的 Web 服务和物联网世界中,JSON 已成为将信息从客户端传输到服务器的首选协议。它们已取代 XML,成为以独立于平台的方式传输信息的首选方式。不幸的是,JDK 没有 JSON 库。但是,有许多优秀的第三方库可以让您解析和创建 JSON 消息,例如 Jackson 和 Gson。Java Web 开发人员应该至少熟悉这些库中的一个。3. 单元测试库单元测试是将普通开发人员与优秀开发人员区分开来的最重要的事情。程序员经常得到不编写单元测试的借口,但避免单元测试的最常见借口是缺乏流行单元测试库的经验和知识,包括 JUnit、Mockito 和 PowerMock。4. 通用库Java 开发人员可以使用一些优秀的通用第三方库,例如 Apache Commons 和 Google Guava。我总是在我的项目中包含这些库,因为它们简化了很多任务。重新发明轮子是没有意义的。我们应该更喜欢使用久经考验的库,而不是时不时地编写我们自己的例程。Java 开发人员最好熟悉 Google Guava 和 Apache Commons 库。5. HTTP 库我不喜欢 JDK 的一件事是它们缺乏对 HTTP 的支持。虽然您可以使用包中的类建立 HTTP 连接 java.net,但使用开源第三方库(如 Apache HttpClient 和 HttpCore)并不容易或无缝。尽管 JDK 9 带来了对 HTTP 2.0 的支持以及对 HTTP 的更好支持,但我强烈建议所有 Java 开发人员熟悉流行的 HTTP 客户端库,包括 HttpClient 和 HttpCore。6. XML 解析库有许多 XML 解析库,包括 Xerces、JAXB、JAXP、Dom4j 和 Xstream。Xerces2 是 Apache Xerces 系列中的下一代高性能、完全兼容的 XML 解析器。这个新版本的 Xerces 引入了 Xerces Native Interface (XNI),这是一个用于构建解析器组件和配置的完整框架,它非常模块化且易于编程。Apache Xerces2 解析器是 XNI 的参考实现,但其他解析器组件、配置和解析器可以使用 Xerces Native Interface 编写。Dom4j 是另一个用于 Java 应用程序的灵活 XML 框架。7. Excel 阅读库信不信由你——所有现实世界的应用程序都必须以某种形式与 Microsoft Office 交互。许多应用程序需要提供在 Excel 中导出数据的功能,如果您必须从 Java 应用程序中执行相同操作,则需要 Apache POI API。这是一个非常丰富的库,允许您 从 Java 程序读取和写入 XLS 文件。您可以查看该链接以获取在核心 Java 应用程序中读取 Excel 文件的工作示例。8. 字节码库如果您正在编写生成代码或与字节码交互的框架或库,那么您需要一个字节码库。它们允许您读取和修改应用程序生成的字节码。Java 世界中一些流行的字节码库是 javassist 和 Cglib Nodep。Javassist(JAVA 编程助手)使 Java 字节码操作变得非常简单。它是一个用于在 Java 中编辑字节码的类库。ASM 是另一个有用的字节码编辑库。9. 数据库连接池库如果您从 Java 应用程序与数据库进行交互,但不使用数据库连接池库,那么,您会丢失一些东西。由于在运行时创建数据库连接需要时间并且使请求处理速度变慢,因此始终建议使用数据库连接库。一些流行的是 Commons Pool 和 DBCP。在 Web 应用程序中,它的 Web 服务器通常提供这些功能,但在核心 Java 应用程序中,您需要将这些连接池库包含到您的类路径中才能使用数据库连接池。10. 消息库与日志记录和数据库连接类似,消息传递也是许多实际 Java 应用程序的共同特征。Java 提供 JMS 或 Java 消息传递服务,它不是 JDK 的一部分。对于此组件,您需要包含一个单独的 jms.jar同样,如果您使用第三方消息传递协议,例如 Tibco RV,那么您需要 tibrv.jar 在应用程序类路径中使用第三方 JAR 。11. PDF 库与 Microsoft Excel 类似,PDF 库是另一种普遍存在的格式。如果您需要在应用程序中支持 PDF 功能,例如 在 PDF 文件中导出数据,您可以使用 iText 和 Apache FOP 库。两者都提供有用的 PDF 相关功能,但 iText 更丰富更好。12. 日期和时间库在 Java 8 之前,JDK 的数据和时间库有很多缺陷,因为它们不是线程安全的、不可变的和容易出错的。许多 Java 开发人员依靠 JodaTime 来实现他们的日期和时间要求。从 JDK 8 开始,没有理由使用 Joda,因为您可以在 JDK 8 的新日期和时间 API 中获得所有这些功能,但是如果您使用的是较旧的 Java 版本,那么 JodaTime 是一个值得学习的库。13. 集合库尽管 JDK 拥有丰富的集合库,但也有一些第三方库提供了更多选项,例如 Apache Commons 集合、Goldman Sachs 集合、Google 集合和 Trove。Trove 库特别有用,因为它为 Java 提供了高速的常规和原始集合。FastUtil 是另一个类似的 API。它通过提供特定类型的映射、集合、列表和优先级队列来扩展 Java 集合框架,这些映射、集合、列表和优先级队列具有较小的内存占用、快速访问和插入;它还提供大(64 位)数组、集合和列表,以及用于二进制和文本文件的快速、实用的 I/O 类。14. 电子邮件 APIjavax.mail 和 Apache Commons Email 都提供了用于从 Java 发送电子邮件的 API 。它建立在 JavaMail API 之上,旨在简化它。15. HTML 解析库与 JSON 和 XML 类似,HMTL 是我们许多人必须处理的另一种常见格式。值得庆幸的是,我们有 JSoup,它极大地简化了在 Java 应用程序中使用 HTML。您可以使用 JSoup 不仅解析 HTML,还可以创建 HTML 文档它提供了一个非常方便的 API 用于提取和操作数据,使用最好的 DOM、CSS 和类似 jquery 的方法。JSoup 实现了 WHATWG HTML5 规范并将 HTML 解析为与现代浏览器相同的 DOM。16.密码库Apache Commons Codec 包包含各种格式的简单编码器和解码器,例如 Base64 和 Hexadecimal。除了这些广泛使用的编码器和解码器之外,编解码器包还维护了一组语音编码实用程序。17. 嵌入式 SQL 数据库库我真的很喜欢像 H2 这样的内存数据库,你可以将它嵌入到你的 Java 应用程序中。它们非常适合测试您的 SQL 脚本和运行需要数据库的单元测试。但是,H2 不是唯一的 DB,您还可以选择 Apache Derby 和 HSQL。18. JDBC 故障排除库有一些很好的 JDBC 扩展库可以让调试更容易,比如 P6spy。这是一个库,可以无缝拦截和记录数据库数据,而无需更改应用程序的代码。您可以使用它们来记录 SQL 查询及其时间。例如,如果您在代码中使用 PreparedStatment 和 CallableStatement,这些库可以记录带有参数的准确调用以及执行所需的时间。19. 序列化库Google 协议缓冲区是一种以高效且可扩展的格式对结构化数据进行编码的方法。它是 Java 序列化的更丰富和更好的替代方案。我强烈建议有经验的 Java 开发人员学习 Google Protobuf。20. 网络库一些有用的网络库是 Netty 和 Apache MINA。如果您正在编写需要执行低级网络任务的应用程序,请考虑使用这些库。以上就是今天分享给大家的一些工作中常用的库,了解并熟练的运用他们,不仅可以大大提高你的开发效率,也可以学习优秀代码的设计,提高自己的编码能力。
-
Java零基础的学习路线 Java作为IT行业的核心技术职位之一,需要坚实的技术基础知识,良好的编码能力以及富有责任心和团队精神。尤其是在竞争越来越激烈的当下和未来,除了自身技术必须过硬以外,还需要软实力的提升,为公司创造更多的价值的技术人才更受用人单位的喜爱。今天主要跟大家聊的技术学习路线,至于软实力部分的学习提升主要还是要靠个人的实践积累而来的,只是靠单纯的职业素养能力培训无法全面提升的,所以稍后只是简单的提一下,更多的是先关注技术学习,毕竟行业门槛要先满足,再有机会说到提升的问题。Java开发是个高技术含量的活,也被称作高级技工,技术本身不过硬,那肯定是无法胜任的,这也决定了Java开发人员的不可替代性。企业在招聘Java开发岗位时都是非常慎重的,所以很多转行的零基础的在了解Java时也会心生恐惧,觉得学不会,难度大,这也很正常。因为很多大学生在面对选开发还是学UI测试时,都会选择后者,技术难度低好上手的。但其实也高估了开发的难度,下面分享一些关于零基础小白路如何学习Java的经验,希望能让大家更平常心的面对Java的学习。Java的学习路线概括虽然Java课程内容非常多,但可以大致概括为四个主要部分:(1)JavaSE基础阶段,主要是要掌握Java的基础语法、面向对象、Java高级语言等。面向对象是Java的基础必须要掌握的;其次重点就是集合、IO、反射、泛型等。Java基础打好了,后期的内容学习才能摸得着方向。(2)JavaWeb,主要是掌握HTML、CSS、JS、ajax以及数据库(MySQL、oracle)相关内容。学习前端课程一定要多练习,不然记不住。重点需要掌握的tomcat的使用和配置、Http协议和Servlet、cookie、session、JSP、ajax、request和response等。虽然这个阶段的内容繁杂,但是你也必须要把重点都掌握好,做综合型项目,反复练习。毕竟学到Javaweb阶段也是可以直接就业从事前端开发工作的,没有难度那怎么行,你说是不是。(3)Java主流框架学习,主要是掌握SpringMVC、mybatis、Springboot、Git、maven等,本阶段基本上都需要重点掌握,SSM是当下的发展趋势,掌握好了也关乎到你以后的薪资高低和入行起点。(4)中间件和微服务,主要掌握Springcloud、redis、rabbit、docker等。这是Java的发展,还在继续向大数据、人工智能领域漫延,不断扩展开发边界。Java的知识大纲:————————————————版权声明:本文为CSDN博主「课工场成都基地」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/kgccd/article/details/128458730
-
零基础java入门教程(入门篇) Java 语言是一种应用性广但又枯燥的一门语言,想要学好 java 开发语言,那么在进入 java 行业之前,就需要做好充足的准备。目前Java 学习分为入门、初级、中级、高级四个阶段,每个阶段都有不同的学习重点。今天小编先来为大家分享零基础 java 入门教程(入门篇)。一、前期准备工作1.开发环境设置首先,你需要一台电脑,然后安装 JDK 和 JRE。JDK 提供了 Java 开发工具,也就是一些必要的 jar 包。JRE 是 Java 的运行环境组件,我们熟悉的 JVM 就在这里。安装完这两个东西后,一般都需要配置环境变量,否则有的目录可能找不到正确的。2.IDE 选择和安装IDE 是指本地开发编辑器。如果没有这个开发编辑器,就只能在记事本等工具中直接键入代码。IDE 最大的优势在于集成了大量的工具和功能模块,让我们可以非常轻松地完成开发。之前大家都用过 eclipse,但是 eclipse 已经不流行了,现在推荐大家直接用 Intellij idea 作为自己的第一个代码编辑器。如果你是用过 eclipse 的同学,基本可以无痛切换。Intellij idea 可以直接从官网下载,试用版为 30 天。如果你想永久使用它,可以在网上查找一些方法。3.关于 jar 包什么是 jar 包,其实就是打包一堆 class 格式的文件,在 Java 中称为 jar 包。这些 jar 包可以直接在编译器中识别出来供开发者使用。对于初学者来说,可能只需要使用 JDK 自带的一些 API,但是如果要引用外部的 jar 包,可能会遇到一些困难。对于 idea 来说,导入外部 jar 包有两种方式,一种是手动导入 jar 包,另一种是使用 maven。后者将在 Java Web 相关文章中介绍。手动导入 jar 包其实并不难。需要先下载 jar 包,然后在对应项目下选择导入 jar 包。具体方法这里就不描述了,大家可以去网上查。二、Java 入门必备知识点在 Java 的入门阶段,你可能需要接触到以下部分知识。无论你从哪一种方式学习,这些内容都是你在学习 Java 基础知识时绕不开的重点。Java 基础这部分内容是你必须掌握的内容。在入门阶段,你需要打下坚实的基础,以便在学习后面的内容时能够更上一层楼。如何打好基础?最好的方法是在 IDE 上实现书中或视频中的每个示例。当然,有时你也可以自己写一些有趣的例子。1.基本数据类型例如 int、double、char 及其包装类。熟悉基本数据类型的使用,了解每种类型占用多少字节,以及如何在它们与包装类之间进行转换。2.过程控制比如 for 循环、if else、while 循环等。如果你是学过 C 语言的同学,可以跳过这一部分。3.字符串类型 String 的使用字符串类型是 Java 中非常重要的类型。它不是基本的数据类型,但非常常用。熟悉和练习字符串相关的 API,开始你的字符串学习。4.数组数组的初始化方法有哪些,二维数组怎么写,数组作为方法参数怎么处理?5.类和对象Java 中最重要的两个概念:类和对象,它们是干什么用的,有什么区别和联系,请在代码中练习。Java 核心技术对于这一部分,我相信很多新手只能了解它们的基本用法,但不了解它们背后的一些原理:比如接口和抽象类为什么会有这些区别,多态是什么意思,为什么会有是反思?新手在学习这部分的时候,只需要知道怎么用就可以了。至于为什么会有这些特性,这些特性背后的原理是什么,可以在初、中级的时候进行了解。1.接口和抽象类写一些接口,写一些实现类来实现这些接口,明白为什么我们需要接口,为什么子类需要实现接口中的方法。同理,我们来实现一些抽象类。然后,看看它与界面有何不同。2.继承、封装和多态如何理解继承,子类和父类是什么关系?封装是保护代码的一种方式。实现封装的方法有哪些?多态性一般分为重载和重写,它们是如何使用的?3.异常处理Java 中的异常处理主要用于捕获和处理错误。请编写一些 try catch 代码块来捕获错误。4.集合类Collection 类是我们经常需要处理的东西,List、Map、Set 等,赶紧熟悉 API,然后写一些测试示例。5.IO 输入流和输出流IO 输入流和输出流可以操作文件、网络数据等,如何在 Java 代码中完成如此复杂的操作呢?实际上,只需要几个简单的 API。6.多线程为了对系统资源进行最合理的分配和调度,我们需要多线程。多线程让程序变得有趣,也带来了很多问题。使用 Thread 和相关 API 来尝试这些有趣的事情。零基础 Java 入门主要需要做好两项工作,第一是前期准备工作,包括开发环境的布置、IDE选择和安装、导入 jar 包,第二项工作是了解并掌握 java 入门必知知识点,例如基础数据类型、流程控制、字符串类型 String 的使用等等内容。
-
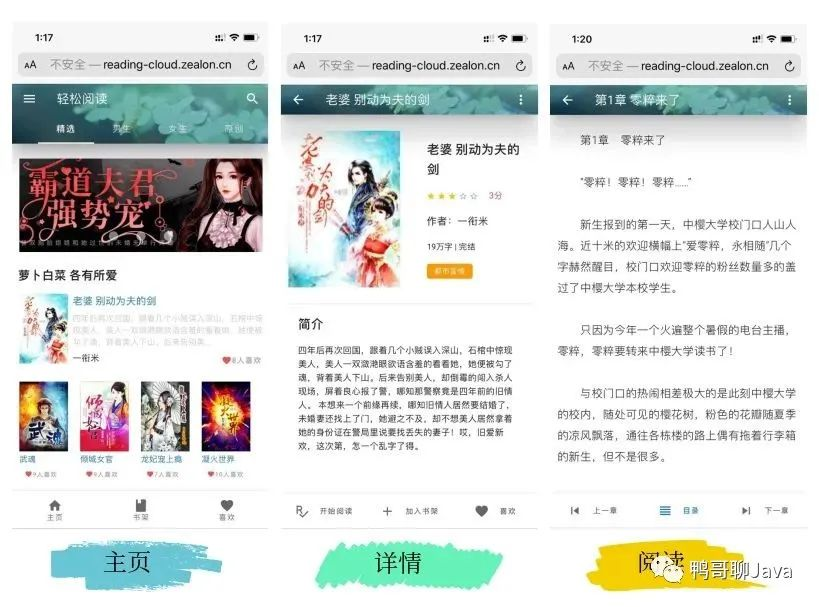
太强了,推荐7个牛哄哄 Spring Cloud 实战项目,拿来即用(附源码) 今天,推荐几个GitHub上7个非常火的开源微服务项目。这是我目前见过的最好的微服务项目。功能完整,代码结构清晰。值得推荐。微服务的基本思想在于考虑围绕着业务领域组件来创建应用,这些应用可独立地进行开发、管理和加速。在分散的组件中使用微服务云架构和平台,使部署、管理和服务功能交付变得更加简单。轻松阅读light reading cloud(轻松阅读)是一款图书阅读类APP,基于 SpringCloud 生态开发的微服务实践项目。涉及 SpringCloud-Gateway、Nacos、Hystrix、OpenFeign、Jwt、ElasticSearch 等技术栈的应用。项目的侧重点主要是基于实际业务场景使用微服务架构落地的思路,图+文的方式介绍每个服务或接口的原理以及为什么使用这种方式实现,想入门微服务的朋友可以试试。核心架构图:客户端:https://github.com/Zealon159/light-reading-cloud-clientapi:https://github.com/Zealon159/light-reading-cloudPiggyMetricsPiggyMetrics ,一个开源项目,适合微服务入门,可以指导开发者使用 Spring Boot、Spring Cloud 和 Docker 搭建微服务架构。该开源项目有一个典型的微服务实现案例 - 个人理财微服务系统。采用Spring Boot/Spring Cloud等技术栈,来实现微服务的开发、构建和治理。页面还很简洁,非常奈斯~PiggyMetrics 被分解为三个核心微服务,它们都是可独立部署的应用程序,围绕特定的业务领域进行组织。这个项目很适合积累微服务的实战经验。项目地址:https://github.com/sqshq/piggymetrics分布式电商项目基于 Spring Cloud 的分布式电商项目,目标打造顶级多模块,高可用,高扩展电商项目。目前这个项目使用分库设计方案,不同的模块依赖不同的数据库实例。技术栈基于 Spring Boot、Spring Cloud、Spring Oauth2 和 Spring Cloud Netflix 等框架,有助于进一步学习Spring Cloud 技术栈。项目截图项目地址:https://github.com/SiGuiyang/spring-cloud-shopCloud-PlatformCloud-Platform是国内首个Spring Cloud微服务化RBAC的管理平台,核心采用Spring Boot 2.4、Spring Cloud 2020.0.0 & Alibaba,前端采用d2-admin中台框架。其具有统一授权、认证后台管理系统,其中包含具备用户管理、资源权限管理、网关API 管理等多个模块,支持多业务系统并行开发,可以作为后端服务的开发脚手架。代码简洁,架构清晰,适合学习和直接项目中使用。模块说明功能截图项目地址:https://gitee.com/geek_qi/cloud-platformSpringBlade 微服务开发平台SpringBlade 是一个由商业级项目升级优化而来的SpringCloud分布式微服务架构、SpringBoot单体式微服务架构并存的综合型项目,采用Java8 API重构了业务代码,完全遵循阿里巴巴编码规范。采用Spring Boot 2.4 、Spring Cloud 2020 、Mybatis 等核心技术,同时提供基于React和Vue的两个前端框架用于快速搭建企业级的SaaS多租户微服务平台。部分界面截图项目地址:https://gitee.com/smallc/SpringBlade互联网云快速开发框架互联网云快速开发框架,微服务分布式代码生成的敏捷开发系统架构。项目代码简洁,注释丰富,上手容易,还同时集中分布式、微服务,同时包含许多基础模块和监控、服务模块。基于SpringBoot2.0的后台权限管理系统,界面简洁美观,核心技术采用Spring、MyBatis、Shiro没有任何其它重度依赖。还被评为 2018 年度最受欢迎中国开源软件项目~项目地址:https://gitee.com/JeeHuangBingGui/jeeSpringCloudOnlineTaxi项目演示项目地址:https://github.com/OiPunk/OnlineTaxi
-
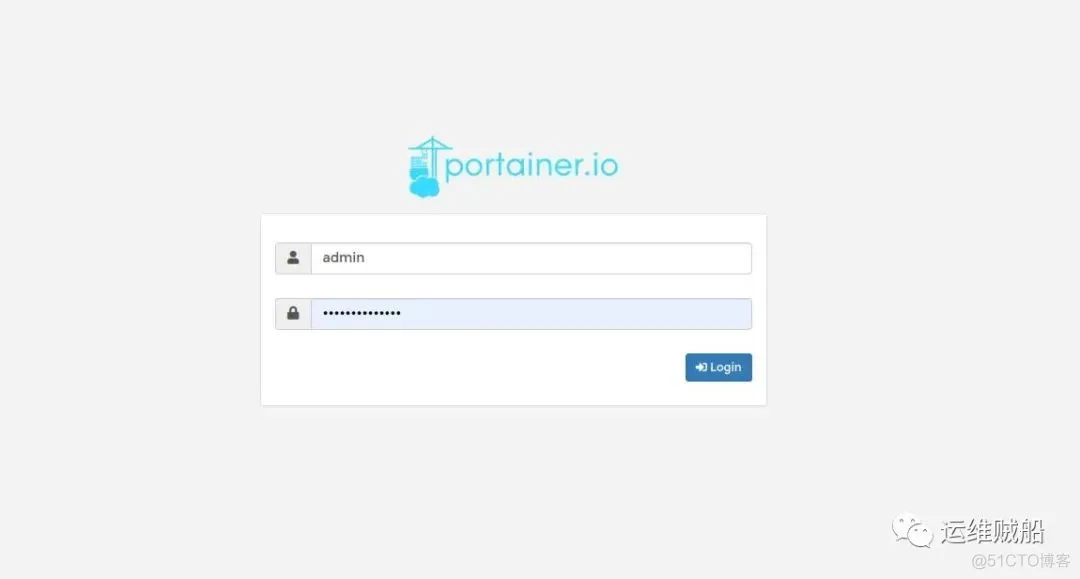
Docker部署 Mysql、redis、Rabbitmq、Vue、Java 项目 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux 或 Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。本文主要讲解如何在Linux环境下使用 Docker 部署前后端分离项目,其中涉及到使用 Docker 安装本人项目相关的一些环境 ,例如mysql、rabbitmq、redis,基于CenterOS7.0。Docker 环境安装1.安装 Docker 客户端# step 1: 安装必要的一些系统工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # Step 2: 添加软件源信息 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # Step 3: 更新并安装 Docker-CE sudo yum makecache fast sudo yum -y install docker-ce # Step 4: 开启Docker服务 sudo service docker start2.配置镜像加速器sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://sq2b0kv9.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker安装 PortainerPortainer 是一个轻量级 Web 端的 Docker 管理 UI,Portainer 够轻松地管理不同的 Docker 环境(Docker 主机或集群)。Portainer 的部署和使用十分简单。Portainer 可以部署为 Linux 容器或 Windows 本机容器,也支持其他平台。Portainer 允许您管理所有 Docker 资源(容器、映像、卷、网络等)!它与独立的 Docker 引擎和 Docker 集群模式兼容。1.安装# 拉取官方镜像 docker pull portainer/portainer # 运行镜像到容器 docker run -d -p 9000:9000\ --restart=always\ -v /var/run/docker.sock:/var/run/docker.sock\ -m 20M --oom-kill-disable --memory-swap=-1\ --name portainer\ portainer/portainer2.访问页面访问地址:http://localhost:9000,第一次打开需要设置用户名、密码,docker 模式我一般选择 Local 本机模式。通过此工具我们可以更加简便的对镜像和容器进行操作和管理。登录页 面板页 安装 mysql# docker search mysql 可通过此命令查看可用版本 # 拉取mysql镜像,默认会拉取最新版本,我这里加上版本号 docker pull mysql:8.0.0 # 查看镜像是否拉取成功 docker images # 在/home/docker/mysql目录下创建mysql挂载目录 mkdir {data,logs,conf} # 运行容器 docker run -d -p 3306:3306 -v /home/docker/mysql/my.cnf:/etc/mysql/conf.d/mysqld.cnf -v /home/docker/mysql/data:/var/lib/mysql -v /home/docker/mysql/logs:/var/log/mysql -e MYSQL_ROOT_PASSWORD=12345 --name mysql_test mysql:8.0.0说明:--name:容器名-e:配置信息,此处配置 mysql 的 root 用户登陆密码-d:后台运行容器,保证在退出终端后容器继续运行-p:端口映射,此处映射 主机 3306 端口 到 容器的 3306 端口-v:挂载目录此处需要注意不要直接挂载容器中的 mysql 配置文件目录,可能会将容器内的配置文件目录清空。个人建议将容器中的 my.cnf 文件复制出来进行选择性的修改,再挂载 mysql.cnf 文件即可。docker cp :用于容器与主机之间的数据拷贝。# 语法 docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|- # 实例 docker cp 96f7f14e99ab:/etc/mysql/conf.d/mysqld.cnf /home/docker/mysql/my.cnf安装 redis因为 redis 默认配置只能够本地连接,不能进行远程访问,使用 Redis 客户端工具连接都会报错,因此需要手动挂载 redis 配置文件。# /home/docker/redis目录下新增挂载文件夹 mkdir {data,conf} # 下载最新版本的Redis镜像 docker pull redis # 新增redis配置文件 cd /home/docker/redis/conf touch redis.conf vim redis.conf添加以下内容#bind 127.0.0.1 protected-mode no appendonly yes requirepass 123456说明:bind 127.0.0.1 ,注释掉这部分,这是限制 redis 只能本地访问protected-mode:默认 yes,开启保护模式,限制为本地访问appendonly:redis 持久化(可选)requirepass:设置访问密码为 123456运行容器docker run --name myredis -p 6379:6379 -v /home/docker/redis/data:/data -v /home/docker/redis/conf/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf说明:--name:容器名称-p :表示将服务器的 6379(冒号前的 6379)端口映射到 docker 的 6379(冒号后的 6379)端口-d :表示以后台服务的形式运行 redis-v :挂载宿主机目录redis redis-server /etc/redis/redis.conf:表示运行 redis 服务器程序,并且指定运行时的配置文件经过以上步骤,便可以通过 redis 客户端工具进行连接,如果连接不上,检查安全组和服务器防火墙端口是否开放安装 rabbitmq# 拉取带图形化管理界面的镜像 docker pull rabbitmq:3.7.7-management # 根据下载的镜像创建和启动容器 docker run -d --name rabbitmq3.7.7 -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq --hostname myRabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin df80af9ca0c9说明:-d:后台运行容器;--name:指定容器名;-p:指定服务运行的端口(5672:应用访问端口;15672:控制台 Web 端口号);-v:映射目录或文件;--hostname :主机名(RabbitMQ 的一个重要注意事项是它根据所谓的 “节点名称” 存储数据,默认为主机名);-e:指定环境变量;(RABBITMQ_DEFAULT_VHOST:默认虚拟机名;RABBITMQ_DEFAULT_USER:默认的用户名;RABBITMQ_DEFAULT_PASS:默认用户名的密码)Rabbitmq 访问地址:http://localhost:15672 至此,基本的运行环境都安装完毕,下面就是关键的打包步骤了。Vue 前端项目打包将 dist 下的所有文件目录拷贝到 SpringBoot 后端项目的 resources\static 目录下,static 目录需要新建。如果你的项目中用到了 shiro 或者 spring security 等安全框架,需要对静态资源放行。以上配置完成后,先在本地运行,再用 maven 进行打包。将 jar 包上传到服务器后,就要开始制作自己的镜像了,首先在与 jar 包同目录下新建 Dockerfile 文件。# 新建Dockerfile文件 touch Dockerfile # 编写Dockerfile文件 vim Dockerfile加入以下内容# Docker image for springboot file run # VERSION 0.0.1 FROM java:8 # VOLUME 指定了临时文件目录为/tmp。 # 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp VOLUME /tmp # 将jar包添加到容器中并更名为app.jar ADD demo-01.jar app.jar # 运行jar包 RUN bash -c 'touch /app.jar' ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]执行 docker build -t [镜像名称] . ,至此镜像文件就制作完成了。docker images查看镜像是否存在。最后一步,创建并启动容器,docker run --name [容器名称] -d -p 80:8080 [镜像名]。
-
-
jodconvert 配置 版本: 4.2.0端口 和 管道文档转换使用TCP端口或者管道 . 管道比TCP更快, 但是需要为jvm指定本地库, 因此默认使用TCP端口模式.要为jvm配置本地库, 即配置 java.library.path 系统属性.On Linux it's e.g.: java -Djava.library.path=/opt/openoffice.org/ure/lib On Windows it's e.g.: java "-Djava.library.path=C:\Program Files (x86)\OpenOffice 4\program" 默认的TCP端口是2002 :OfficeManager officeManager = LocalOfficeManager.builder() .portNumbers(2002, 2003, 2004, 2005) .build(); 上面的代码指定了4个端口, 因此在OfficeManager启动时, 将启动4个office进程来进行处理转换.officeHome该属性是office的安装目录 .// This example will force JODConverter to use the OpenOffice 4 // installation that can be found using the specified path. // 示例设置officeHome OfficeManager officeManager = LocalOfficeManager.builder() .officeHome("D:\\Program Files (x86)\\OpenOffice 4") .build(); processManager当jodconvert需要工作时, 需要一个processManager , 用于在需要时关闭进程.默认情况下: 会根据os寻找最佳的processManager . 也可以自己实现ProcessManager接口来改变之.// This example will create an instance of the com.example.foo.CustomProcessManager // class that will be used by the created OfficeManager. OfficeManager officeManager = LocalOfficeManager.builder() .processManager("com.example.foo.CustomProcessManager") .build(); workingDir当每个office进程启动时都会创建一个临时目录. 临时目录创建在workingDir中. 该目录也用来存放转换的中间结果.默认使用: java.io.tmpdir 目录templateProfileDir每个LocalOfficeManager都会创建一个临时文件夹来存放当前进程属性, 从而可以避免多个进程间的相互干扰. 通过该属性可以提供一个属性模板来定制属性. OfficeManager 将从模板拷贝属性到临时文件夹中, 这样进程间使用相同的设置的同时避免相互干扰.这些设置可以是 Tools>Options菜单中的 . 如:Load/Save > General: 可以禁用保存互联网urlLoad/Save > Microsoft Office : 这个可以避免文档中的excel被丢失.默认: 创建时使用新的, 受 -nofirststartwizard命令影响.killExistingProcess在新进程启动时是否杀死已存在进程. 默认 : trueprocessTimeout处理超时时间, 单位毫秒 . 默认 : 120000 (2分钟)processRetryInterval重试执行的时间间隔, 毫秒.默认: 250taskExecutionTimeout允许进程执行一个task的最大时间 . 超时将终止, 然后处理下一个task.默认 : 120000(2分钟)maxTasksPerProcess每个office进程可执行的最大task数, 超过将重启. 默认: 200disableOpengl设置当前office进程启动时是否需要禁用opengl ( 仅 libreOffice) . 若opengl已禁止则不会进行任何处理 . 当该属性改变时, office必须重启. 若你遇到LO挂掉, 可以测试该属性.默认: falsetaskQueueTimeout设置task在队列的最大存活时间 , 超时将被从队列移除 并抛出 OiffceException .默认: 30000(30分钟)
-
记Ubuntu16.04 下 LibreOffice的安装与使用 LibreOffice主包和语言包wget http://mirrors.ustc.edu.cn/tdf/libreoffice/stable/6.4.6/deb/x86_64/LibreOffice_6.4.6_Linux_x86-64_deb.tar.gzwget http://mirrors.ustc.edu.cn/tdf/libreoffice/stable/6.4.6/deb/x86_64/LibreOffice_6.4.6_Linux_x86-64_deb_langpack_zh-CN.tar.gztar xf LibreOffice_6.4.6_Linux_x86-64_deb.tar.gzsudo dpkg -i LibreOffice_6.4.6.2_Linux_x86-64_deb/DEBS/*.debtar xf LibreOffice_6.4.6_Linux_x86-64_deb_langpack_zh-CN.tar.gzsudo dpkg -i LibreOffice_6.4.6.2_Linux_x86-64_deb_langpack_zh-CN/DEBS/*.deb字体wget https://mirrors.tuna.tsinghua.edu.cn/adobe-fonts/source-han-serif/SubsetOTF/SourceHanSerifCN.zipwget https://mirrors.tuna.tsinghua.edu.cn/adobe-fonts/source-han-sans/SubsetOTF/SourceHanSansCN.zipunzip SourceHanSansCN.zipunzip SourceHanSerifCN.zipsudo cp -r SourceHanSansCN /usr/share/fonts/sudo cp -r SourceHanSerifCN /usr/share/fonts/sudo apt install fontconfigfc-cache -fv其它依赖sudo apt install -y openjdk-8-jdk libxinerama1 libcairo2 libcups2 libsm6使用(word转pdf)libreoffice6.4 --invisible --convert-to pdf input.docx --outdir .