搜索到
266
篇与
的结果
-
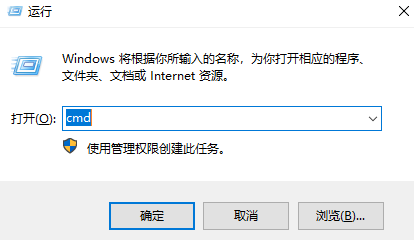
 windows通过cmd查看端口占用,并停止该端口,杀死进程kill等命令 通过cmd查看端口占用,并停止该端口,杀死进程kill等命令首先需要打开cmd命令窗口方式一:使用 win + R 快捷键方式打开运行窗口,输入 “cmd”,然后点击确定按钮打开命令提示符;如图所示:方式二:按 win 键会弹出一个窗口,这时直接输入 “cmd”,可直接打开cmd窗口,也可以使用管理员身份打开cmd进入命令提示符窗口后,输入 netstat -ano 并按下回车执行,之后就会显示电脑上运行的 所有端口号 。【Tip:如果已知被占用的端口时,可以用命令 netstat -aon|findstr 9201 直接找到端口号为9201的进程PID 】接下来,输入 tasklist | findstr "14488" 并按下回车,查询 PID 为 14488 的进程名称,如图所示:结束指定进程,输入以下其中一种命令,按回车执行即可。命令一:根据PID进程号结束进程taskkill /pid 14488 -t -f命令二:根据进程名称结束进程taskkill /f /t /im java.exe
windows通过cmd查看端口占用,并停止该端口,杀死进程kill等命令 通过cmd查看端口占用,并停止该端口,杀死进程kill等命令首先需要打开cmd命令窗口方式一:使用 win + R 快捷键方式打开运行窗口,输入 “cmd”,然后点击确定按钮打开命令提示符;如图所示:方式二:按 win 键会弹出一个窗口,这时直接输入 “cmd”,可直接打开cmd窗口,也可以使用管理员身份打开cmd进入命令提示符窗口后,输入 netstat -ano 并按下回车执行,之后就会显示电脑上运行的 所有端口号 。【Tip:如果已知被占用的端口时,可以用命令 netstat -aon|findstr 9201 直接找到端口号为9201的进程PID 】接下来,输入 tasklist | findstr "14488" 并按下回车,查询 PID 为 14488 的进程名称,如图所示:结束指定进程,输入以下其中一种命令,按回车执行即可。命令一:根据PID进程号结束进程taskkill /pid 14488 -t -f命令二:根据进程名称结束进程taskkill /f /t /im java.exe -
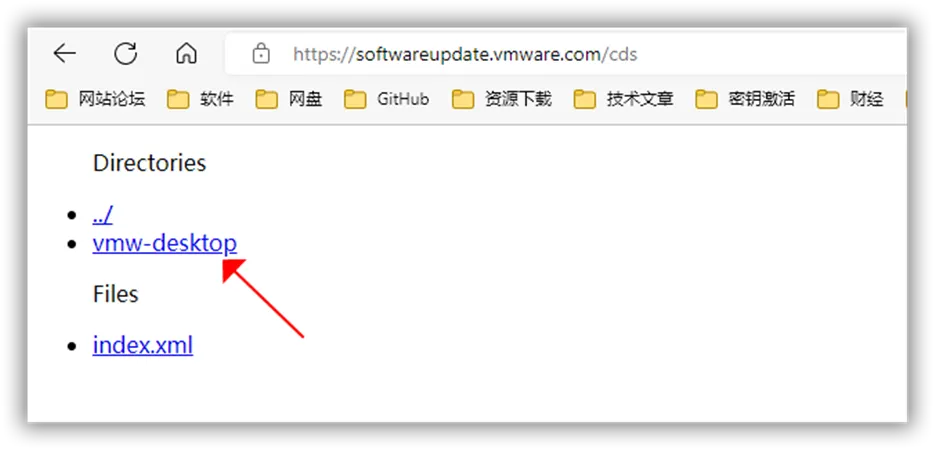
无需密钥,直接永久激活!VMware虚拟机 VMware被博通收购后,VMware Workstation Pro和VMware Fusion Pro对于商业用户采取了订阅制,但对个人用户已经彻底免费。以前免费的Workstation Player和Fusion Player 已经不再更新,因为没必要了(Fusion是用于MacOS上的虚拟机)。这么多年VMware Workstation直接使用密钥就可以激活,反正也没有从个人用户那挣过钱,搞成完全免费,格局一下就打开了。不过下载有一些麻烦,原来可以在官网直接下载,现在需要免费注册一个博通的账号,然后才可以下载。近日更新到了17.6.0版本,主要更新内容如下:1.引入vmcli,vmcli是VMware Workstation Pro中包含的命令行工具,使用户可以直接从Linux或macOS终端或Windows命令提示符与hypervisor进行交互。通过vmcli,可以创建新的虚拟机、生成虚拟机模板、上电虚拟机、修改虚拟机的各种设置等。此外,您还可以创建脚本来依次运行多个命令; 2.新增支持:Windows Server 2025、Windows 11 23H2、Ubuntu 24.04、Fedora 40; 3.默认情况下不再包含旧的VMTools iso,但可以下载; 4.蓝牙集线器、物理主机并行端口、Unity模式、增强型键盘驱动程序已被移除。关于VMware Workstation的版本,我以前介绍过,官方提供了两种:①全功能版本(Full) ,包含所有功能,完全版大家使用的最多。已经上传到网盘,17.6.0全功能版下载:{cloud title="全功能版本(Full)" type="ct" url="https://www.123pan.com/s/xY3DVv-oqdAA?" password="HKGZ"/}②核心版(Core) ,精简掉了Prew2k/PreVista/Solaris等工具,体积小了一半,如果需要的话,可以单独下载这些工具进行安装。估计这些工具用的人不多。下载后为tar格式的压缩文件,使用WinRAR等解压缩软件解压,然后双击exe安装即可。17.6.0核心版下载:https://softwareupdate.vmware.com/cds/vmw-desktop/ws/17.6.0/24238078/windows/core/VMware-workstation-17.6.0-24238078.exe.tarCore版 在官网提供了所有历史版本下载,大家也可以自行去下载。但需要注意的是,下载的时候需要一些技巧:https://softwareupdate.vmware.com/cds打开上面的地址后,如下所示。直接点击可能无法进入,在网址栏中最后输入"/+名称"回车即可。每一个层级都要这样才能进入。如下图所示:
-
一条命令,永久激活!Office 2024! 微软已经率先发布 Office 2024英文版(零售版) 。众所周知,零售版是有微软正式发布的离线镜像,目前中文版的镜像微软尚未发布。而对于批量授权版,自从Office 2019开始,微软就已经不再单独发布镜像文件了。所采用的方式均为在线部署安装。很多第三方软件基于微软提供的ODT部署方式,开发了操作更加便捷的Office部署程序。但是最近收到很多小伙伴的留言提问,为什么安装了Office 2024 批量版后,显示preview字样?还是预览版吗?首先,微软至今尚未宣布正式发布Office 2024,它包含零售版和批量授权版两大类,零售版中也仅仅是英文版的Office 2024镜像已经可以在官网下载,但中文版依旧未正式发布。批量授权版的Office 2024均未正式发布,因此现在依然是预览版。其次,现在的预览版可以安装体验了吗?可以!它已经很接近正式版,是准正式版。为什么有的人安装后没有preview字样,这是怎么回事?下面先把安装过程截图展示一下~安装完毕后,默认情况显示 preview 字样,虽然还是预览版,但是当前版本自带的许可证已经包含了正式版的许可证。就好比Windows10或11系统一样,安装专业版密钥它就是专业版,安装企业版密钥它就是企业版。Office 2024这里也一样,安装正式版的密钥,它就不再显示preview字样了。下面这几个是几枚MAK密钥,看起来怪怪的,但确实能够安装。ProPlus2024:NBBBB-BBBBB-BBBBB-BBBJD-VXRPM Standard2024:V28N4-JG22K-W66P8-VTMGK-H6HGR ProjectPro2024:NBBBB-BBBBB-BBBBB-BBBH4-GX3R4 ProjectStd2024:PD3TT-NTHQQ-VC7CY-MFXK3-G87F8 VisioPro2024:NBBBB-BBBBB-BBBBB-BBBCW-6MX6T VisioStd2024:JMMVY-XFNQC-KK4HK-9H7R3-WQQTV更改密钥后,再重新打开Office,preview字样就消失了~最后,使用一条命令激活Office 2024,在 Powershell 中,首先输入以下命令,然后输入 "2" ,最后输入 "1" 即可。irm https://get.activated.win | iex注意:该命令需要联网,其原理是下载MAS激活软件的最新版,目前2.7版已经发布。MAS激活Office的方法是使用了Ohook,为永久激活!
-
还学鸿蒙原生?vue3 + uniapp 可以直接开发鸿蒙啦! 前言7月20号,uniapp 官网 “悄咪咪” 的上线了 uniapp 开发鸿蒙应用 的文档,算是正式开启了 Vue3 + uniapp 开发鸿蒙应用 的时代。开发鸿蒙的前置准备想要使用 uniapp 开发鸿蒙,我们需要具备三个条件:DevEco-Studio 5.0.3.400 以上(下载地址:https://developer.huawei.com/consumer/cn/deveco-studio/)鸿蒙系统版本 API 12 以上 (DevEco-Studio有内置鸿蒙模拟器)HBuilderX-alpha-4.22 以上PS: 这里不得不吐槽一下,一个 DevEco-Studio 竟然有 10 个 G......[安装好之后,我们就可以通过 开发工具 运行 示例代码]运行时,需要用到 鸿蒙真机或者模拟器。但是这里需要 注意: Windows系统需要经过特殊配置才可以启动,mac 系统最好保证系统版本在 mac os 12 以上windows 系统配置方式(非 windows 用户可跳过): 打开控制面板 - 程序与功能 - 开启以下功能Hyper-VWindows 虚拟机监控程序平台虚拟机平台注意: 需要win10专业版或win11专业版才能开启以上功能,家庭版需先升级成专业版或企业版启动鸿蒙模拟器整个过程分为三步(中间会涉及到鸿蒙开发者申请):下载 uni-app 鸿蒙离线SDK template-1.3.4.tgz (下载地址:https://web-ext-storage.dcloud.net.cn/uni-app/harmony/zip/template-1.3.4.tgz)解压刚下载的压缩包,将解压后的模板工程在 DevEco-Studio 中打开等待 Sync 结束,再 启动鸿蒙模拟器 或 连接鸿蒙真机(如无权限,则需要申请(一般 3 个工作日),申请地址:https://developer.huawei.com/consumer/cn/activity/201714466699051861/signup)配置 HBuilderX 吊起 DevEco-Studio打开HBuilderX,点击上方菜单 - 工具 - 设置,在出现的弹窗右侧窗体新增如下配置[注意:值填你自己的 DevEco-Studio 启动路径]"harmony.devTools.path" : "/Applications/DevEco-Studio.app"创建 uni-app 工程BuilderX 新建一个空白的 uniapp 项目,选vue3在 manifest.json 文件中配置鸿蒙离线SDK路径(SDK 路径可在 DevEco-Studio -> Preferences(设置) z中获取)编辑 manifest.json 文件,新增如下配置:然后点击 运行到鸿蒙即可最后这样我们就有了一个初始的鸿蒙项目,并且可以在鸿蒙模拟器上运行。关于更多 uniapp 开发鸿蒙的 API,大家可以直接参考 uniapp 官方文档:https://zh.uniapp.dcloud.io/tutorial/harmony/dev.html#nativeapi
-
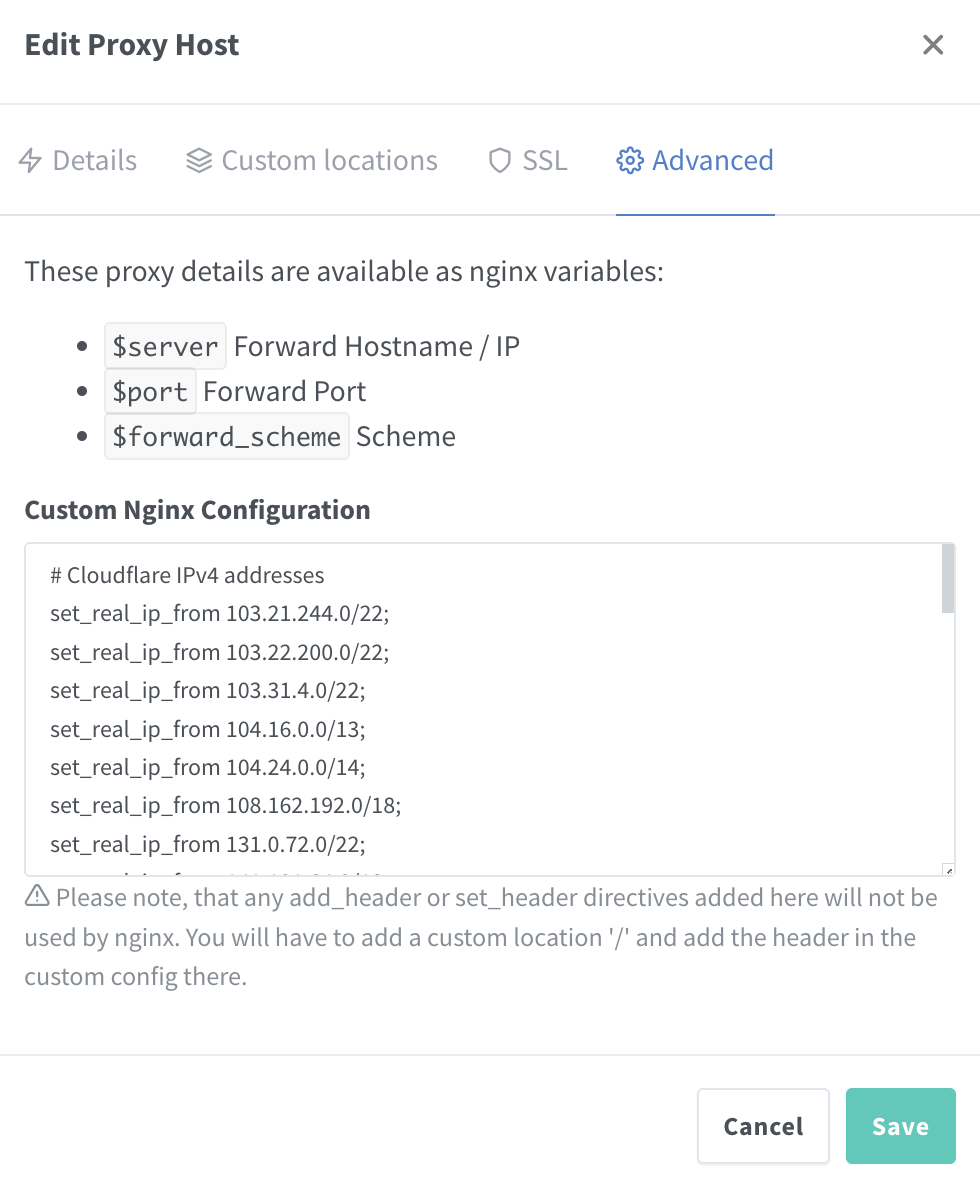
Cloudflare橙色云启用后 Nginx Proxy Manager的IP白名单和黑名单配置指南 在使用Cloudflare的橙色云(即启用CDN功能)后,许多用户发现Nginx Proxy Manager中的Access Lists(IP地址白名单/黑名单)失效。这通常是因为Cloudflare的代理服务器屏蔽了真实的客户端IP地址,导致Nginx无法直接获取客户端的真实IP,而只能看到Cloudflare的IP地址。本文将介绍如何配置Nginx,以便它能够正确识别和使用Cloudflare传递的真实客户端IP地址,从而确保访问控制列表的正常工作。配置Cloudflare的真实IP头要解决这一问题,首先需要在Nginx中配置,以便它能够识别Cloudflare传递的真实客户端IP地址。Cloudflare通常通过CF-Connecting-IP或X-Forwarded-For头传递真实的客户端IP。以下是具体步骤:在Nginx配置文件中添加以下内容# Cloudflare IPv4 addresses set_real_ip_from 103.21.244.0/22; set_real_ip_from 103.22.200.0/22; set_real_ip_from 103.31.4.0/22; set_real_ip_from 104.16.0.0/13; set_real_ip_from 104.24.0.0/14; set_real_ip_from 108.162.192.0/18; set_real_ip_from 131.0.72.0/22; set_real_ip_from 141.101.64.0/18; set_real_ip_from 162.158.0.0/15; set_real_ip_from 172.64.0.0/13; set_real_ip_from 173.245.48.0/20; set_real_ip_from 188.114.96.0/20; set_real_ip_from 190.93.240.0/20; set_real_ip_from 197.234.240.0/22; set_real_ip_from 198.41.128.0/17; # Cloudflare IPv6 addresses set_real_ip_from 2400:cb00::/32; set_real_ip_from 2606:4700::/32; set_real_ip_from 2803:f800::/32; set_real_ip_from 2405:b500::/32; set_real_ip_from 2405:8100::/32; set_real_ip_from 2a06:98c0::/29; set_real_ip_from 2c0f:f248::/32; real_ip_header CF-Connecting-IP;CloudflareIP 范围 https://www.cloudflare.com/zh-tw/ips/这些IP段是Cloudflare的代理服务器IP地址,通过set_real_ip_from指令,Nginx将信任这些IP地址,并从CF-Connecting-IP头中获取真实的客户端IP。更新Nginx Proxy Manager配置确保Nginx Proxy Manager能够正确使用上述配置。如果Nginx Proxy Manager允许自定义Nginx配置片段,将上述配置片段添加到相应位置。调整访问控制列表确保你的访问控制列表(白名单/黑名单)中的IP地址策略基于真实的客户端IP,而不是Cloudflare的IP地址。实际使用场景访问控制公司A希望只允许公司内部IP地址访问其网站。他们启用了Cloudflare的CDN加速,但发现所有访问请求的IP地址都显示为Cloudflare的代理服务器IP,导致访问控制列表失效。通过上述配置,Nginx能够正确识别真实的客户端IP,从而确保只有公司内部IP地址能够访问网站。日志记录和分析公司B使用Nginx记录访问日志以进行流量分析和安全监控。在启用Cloudflare CDN后,访问日志中显示的IP地址都是Cloudflare的代理服务器IP。通过上述配置,Nginx能够记录真实的客户端IP,从而提供准确的流量分析和安全监控数据。防止DDoS攻击公司C遇到DDoS攻击,攻击流量通过Cloudflare的代理服务器进入,导致Nginx的防护措施失效。通过正确配置Nginx以识别真实的客户端IP,公司C可以更有效地应用防火墙规则,识别并阻止攻击IP,从而提升防护效果。结论通过正确配置 Nginx 以识别 Cloudflare 传递的真实客户端IP地址,可以解决因启用 Cloudflare CDN 功能导致的访问控制列表失效问题。这不仅能确保访问控制列表的正常工作,还能提升日志记录、流量分析和安全防护的准确性。希望本文对你配置 Nginx Proxy Manager 以支持 Cloudflare CDN 功能有所帮助。
-
200 行 Rust 代码实现简单 CF Workers AI Bot | Rust 学习日记 本文由 High Ping Network 的小伙伴 GenshinMinecraft 进行编撰前言这次主要是用 Rust 重写了之前用 Python3 写的 Cloudflare Workers AI Telegram 机器人一边看着 《Rust 圣经》 一边 Coding,还是挺好玩的当然,因为我是 Rust 新手,所以代码中有问题的地方还请多多包涵请注意,本文会一步步讲解这一 Bot 的实现过程,也算是我学习 Rust 的一个阶段性总结如果你不想看实现过程,请直接翻到本文末尾开干!如何开启一个项目? 那当然是: 新建文件夹!环境环境配置请看 Rust 官方文档 新建文件夹并在终端输入以下命令来初始化一个项目:cargo new [文件夹名字]去 Telegram 申请一个新的 Bot ,保存 Bot Token 以留作备用 (这么简单懒得说了)然后前往这里来创建 Workers AI API 令牌 和 帐户 ID ,也是复制保存备用配置依赖在项目根目录下有个 Cargo.toml ,里面是有关项目信息的内容,在最底下添加如下内容:[dependencies] reqwest = { version = "0.12.4", features = ["json","blocking"] } serde_json = "1.0" teloxide = { version = "0.12", features = ["macros"] } tokio = { version = "1.38.0", features = ["rt-multi-thread", "macros"] } log = "0.4.21" simple_logger = "5.0.0"这里表示了项目需要用到这堆东西,如果之前有用过 Python ,那这玩意就可以理解为 requirements.txt然后删除 src/main.rs 中所有内容,并在开头引用这些库:use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; 这样就算引用完成了!PS: 你可能还需要去终端来安装一下依赖:cargo add reqwest serde_json teloxide log simple_logger常量定义// 初始化全局常量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = "";API_KEY: Workers AI API 令牌USER_ID: 帐户 IDPROMPT: AI 提示词MODEL: 对话使用的大模型,默认是阿里云的通义千问,可以在这里查看支持的模型,更改即可,非必要无需更改TELEGRAM_BOTTOKEN: Telegram Bot Token按照要求将 Workers AI API 令牌 和 帐户 ID 还有 Telegram Bot Token 放入对应的位置中,以便于下面调用如果有需要,也可以根据文档来修改 MODEL 模型和 PROMPT 提示词编写 GPT 请求函数先不着急编写 Bot 主体部分,来看下有关网络请求的调用函数定义// GPT 对话函数,用于请求 API 并返回async fn gpt(question: &str) -> Result<String, String> {}简单介绍一下:这句定义了一个名为 gpt 的异步函数,question 是参数返回值是 String 但是不确定是返回正常结果还是错误信息,这种做法有助于错误处理构建 Headers玩过大模型 API 的都知道,鉴权 (也就是 API_Tokens 这类东西) 一般是放在 Headers 里面的,所以我们要来构建 Headers而 Workers AI 的 API Headers 格式类似这样:Authorization: Bearer {API_TOKEN}于是,就有了下面的代码:// 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), );这里定义了一个变量 headers ,并用 insert 插入两条键值对其中 Authorization 用于存放 API_KEY ,用到了 format!() 宏格式化它的值,运用到了最开始定义的 API_KEY 常量Content-Type 则是表明了发送的数据格式,用于指示资源的MIME类型.parse() : 将字符串转化为 HeaderValue 类型,这是 reqwest 库用来存储 Headers 的类型.unwrap() : 直接获取结果而不进行错误处理 (有错误就退出,不过这段代码没有必要进行错误处理)构建请求体接下来是请求体:let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); 简单易懂,调用 `PROMPT` 和函数参数中的 `question` 即可,简单的 Json [发送请求] 终于可以发送请求了,首先,来初始化一个 HTTP Client: '''rust let client = reqwest::Client::new();随后就可以发送请求了:let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?;这里声明了一个 api 变量,用于存储获取到的数据client.post(): 则是发送 Post 请求的主要语句,URL 中的 Workers AI API 令牌 和 模型 还是一样使用 format!() 来构建headers(headers): 传递 Headers.json(&data): 将 data 转换为 Json 作为请求体.send().await: 这一步就相当于发送请求了,并等待异步操作完成.map_err(|_| "请求出现问题".to_string())?: 错误处理,如果发生问题则直接返回 请求出现问题 而不继续执行,如果出现错误则直接赋值给变量 api.text().await: 将收到的数据转换为文本信息,并等待异步操作完成.map_err(|_| "解析响应体时出错".to_string())?: 作用和上面那个差不多这样就算发送完一个请求并把接收到的信息赋值给 api 了解析 Json经过上面的请求,api 应该是一个 Json 格式的字符串,我们需要在里面提取出需要的答案Json 大概长这样:{ "result": {"response": "我是来自阿里云的超大规模语言模型,我叫通义千问。"}, "success": true, "errors": [], "messages": []}let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string())第一行代码尝试将变量 api 中存储的字符串解析为 JSON 格式,同样的 .map_err() 就不再解释了第一次从 Json 中获取信息返回的是 Option<&Value> 即可能有或可能没有,所以我们使用 .ok_or() 来判断有或无,当有时则直接赋值,没有则返回错误第二次从 Json 中获取信息也一样,不多赘述最后,返回 result 即可编写主程序呼呼,终于等待编写主程序了,不过主要的信息处理程序并不在 main 函数中,main 函数在代码中只起到一个引导的作用async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; }首先定义一个 main 异步函数,这是主程序的入口初始化一个 Log 记录器,这里使用了 simple_logger 库,该库无需繁琐地配置 Log 信息即可做到美观的输出,定义 Log Level 为 Debuginfo!() 宏是用来记录 Log 的,相同的,还有 debug!() warn!() error!() 等,分别记录不同等级的日志,下面不再赘述let bot = Bot::new(TELEGRAM_BOTTOKEN): 定义了一个名为 bot 的 Bot Client,它可以接收消息、发送消息等teloxide::repl:异步函数,可以启动一个 REPL 循环 (简要理解成可以处理新信息的循环即可),传入 Bot 并接受名为 msg 的信息提供给下面的代码。下面的代码即为消息处理程序msg.chat.is_private(): 返回一个布尔值,是否为私聊信息if msg.chat.is_private() {} else {}: 消息处理程序分成了两个部分,即判断是否为私聊 Bot,如果是则执行上半部分代码,否则执行下半部分msg.text(): 返回一个字符串,消息的文本内容因为 msg.text() 的类型为 Option<&str>,即可能有或没有 (没有文本信息的话可能为图片、文件、贴纸等),所以需要使用 match 做判断,如果有文本信息则将 bot 和 msg 传入 matchmsgprivate 或者 matchmsgpublic 函数中 (之后会定义这两个函数)当没有文本消息时候,则 Log Debug 输出总的来说,main 函数主要就是接受信息并交给其他函数处理 (尽管是小项目我个人还是建议不要全堆在 main 函数里面)处理私聊信息私聊信息需要做到:/start 发送帮助信息当直接对话 (不是 / 命令时),直接返回结果/ai 问题 返回问题的结果主要思路是判断消息是否为 / 开头,如果不是则直接返回 GPT 回答,如果是再进行指令判断async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } }先定义一个 text 用于储存文本信息,便于调用 (因为在主函数调用该函数时候已经做过检测,所以这里使用 .unwrap() 并无不妥)随后进行 / 开头命令检测,为否直接调用 replyai 函数 (等会定义),传入 msg, bot, msg.text() (不想处理借用问题,msg 用 .clone() 就好)如果为是,则使用 .splitn() 分割命令,command 为指令部分 (如 /start),argument 为参数部分 (可能没有,所以用 Option<&str>)如果命令开头为 /ai,则传入 replyai 函数;如果开头为 /start,则传入 replystart 函数 (等会定义)如果都不是机器人的指令,则不做处理,输出 Debug 信息处理群组信息这一部分和处理私聊信息差不多,区别只是非指令消息不回复async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }同样的逻辑,只是检测为非指令仅输出 Debug 消息而已AI 回复这里要实现一个函数需要传入 msg、bot、text 信息,调用 gpt 函数并发送回 Telegramasync fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; }定义异步函数不再赘述,需要注意 optiontext: Option<&str> 需要传入的是 Option<&str>,对应着消息处理函数的 argument既然 optiontext 为可能有可能没有的,那就先来检测一下。使用 match,当有值时赋值给 text;无值时输出 warn 信息并回复给用户,提示请查看 /start 指令,并退出检测成功后,调用 gpt 函数,也是使用 match。如果正常则赋值给 answer,有错误则输出 error 信息输出几条 info 信息,随后就可以将结果发送回 Telegram 了 (GPT 返回内容多使用 Markdown 格式,所以这里指定使用 MarkdownV2 格式发送)就这么简单,主要的代码还是错误处理,不然没有必要写这么多Start 回复最最最最简单的一部分,传入 bot 和 msg 即可async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; }定义一个字符串,作为帮助信息info 输出基本信息发送帮助信息完整代码 use reqwest::header; use serde_json::{from_str, json, Value}; use teloxide::{prelude::*,types::ParseMode}; use log::{Level, info, warn, error, debug}; use simple_logger; // 初始化全局变量 static API_KEY: &str = ""; static USER_ID: &str = ""; static PROMPT: &str = "你是一个中文大模型,不管我用什么语言提出问题,你必须使用中文回答!"; static MODEL: &str = "@cf/qwen/qwen1.5-14b-chat-awq"; static TELEGRAM_BOTTOKEN: &str = ""; // GPT 对话函数,用于请求 API 并返回 async fn gpt(question: &str) -> Result<String, String> { // 初始化 Headers,包含 API KEY let mut headers = header::HeaderMap::new(); headers.insert( "Authorization", format!("Bearer {}", API_KEY).parse().unwrap(), ); headers.insert( "Content-Type", "application/x-www-form-urlencoded".parse().unwrap(), ); // 初始化问题 let data = json!({ "messages": [ {"role": "system", "content": PROMPT}, {"role": "user", "content": question}, ] }); // 初始化 Client let client = reqwest::Client::new(); // 请求 CF API let api: String = client .post(format!( "https://api.cloudflare.com/client/v4/accounts/{}/ai/run/{}", USER_ID, MODEL )) .headers(headers) .json(&data) .send() .await .map_err(|_| "请求出现问题".to_string())? .text() .await .map_err(|_| "解析响应体时出错".to_string())?; // 解析 Json let json: Value = from_str(&api).map_err(|_| "解析 Json 时出错".to_string())?; let result_tmp = json .get("result") .ok_or("Json 中缺少 'result' 字段".to_string())?; let result = result_tmp .get("response") .ok_or("Json 中缺少 'response' 字段".to_string())?; Ok(result.to_string()) } // 主函数 #[tokio::main] async fn main() { // 日志初始化 simple_logger::init_with_level(Level::Debug).unwrap(); // 初始化 Bot info!("Bot 初始化中"); let bot = Bot::new(TELEGRAM_BOTTOKEN); info!("Bot 初始化完毕"); // 主程序 teloxide::repl(bot, |bot: Bot, msg: Message| async move { // 私聊 if msg.chat.is_private() { match msg.text() { Some(_text) => matchmsgprivate(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } else { // 非私聊 match msg.text() { Some(_text) => matchmsgpublic(msg, bot).await, None => debug!("消息没有文本内容,跳过"), } } Ok(()) }) .await; } // GPT 回复函数 async fn replyai(msg: Message, bot: Bot, optiontext: Option<&str>) { let text: &str; // 检测是否有参数 match optiontext { Some(texttmp) => text = texttmp, None => { warn!("{}", format!("用户 {:?} 使用方法不正确", msg.chat.id)); let _ = bot.send_message(msg.chat.id, "使用方法不正确!请使用 /start 来查看使用方法") .parse_mode(ParseMode::MarkdownV2) .await; return; } } let mut answer: String = String::new(); // 最重要的一部分 match gpt(text).await { Ok(response) => answer = response, Err(error) => error!("{}", error), } info!("{}", format!("用户 {} 使用了本 Bot, 问题是: {}", msg.chat.id, text)); info!("{}", format!("回答是: {}", answer)); // 回复 let _ = bot.send_message(msg.chat.id, answer) .parse_mode(ParseMode::MarkdownV2) .await; } // start 回复函数 async fn replystart(msg: Message, bot: Bot) { let startmessage: &str = r#" 命令帮助: /start: 显示本消息 /ai 问题: 获取由 Cloudflare Workers AI 驱动的 GPT 答案 PS: 私聊 Bot 可直接对话,无需 /ai 前缀 "#; info!("{}", format!("用户 {} 开始使用本 Bot", msg.chat.id)); let _ = bot.send_message(msg.chat.id, startmessage) .parse_mode(ParseMode::MarkdownV2) .await; } // 私聊检测 async fn matchmsgprivate(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { replyai(msg.clone(), bot, msg.text()).await; // 非命令直接当作问题 } } // 非私聊 async fn matchmsgpublic(msg: Message, bot: Bot) { let text: &str = msg.text().unwrap(); if text.starts_with('/') { // 是否为 "/" 开头的命令 let mut parts = text.splitn(2, ' '); let command: &str = parts.next().unwrap(); // 命令部分 let argument: Option<&str> = parts.next(); // 参数部分,可能为 None if command.starts_with("/ai") { replyai(msg.clone(), bot, argument).await; } else if command.starts_with("/start") { replystart(msg, bot).await; } else { debug!("非本 Bot 命令,跳过"); } } else { debug!("非命令,跳过"); } }保存后 执行下面指令即可编译运行:cargo build --release ./target/release/RUST总结这次主要是了解了 Rust 的基本语法,更深层次的还尚未触及到,对于代码中解释有误或代码有问题的请多多谅解
-
-
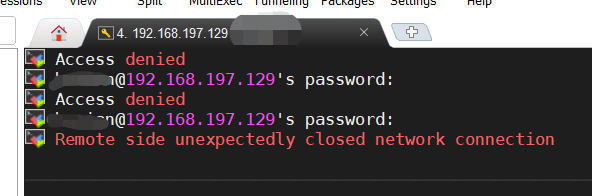
Linux SSH Access denied(拒绝访问)解决方案 新安装的 CentOS 7 使用 SSH 连接出现 Access denied,记录一下这个坑。详细问题如下(见图):解决方案查了下资料,Linux 系统默认就是禁止远程登录的。那就打开权限就行了。因为需要修改系统设置,普通用户会出现没有权限,所以在超级管理员下操作!编辑配置文件:vim /etc/ssh/sshd_config修改 PermitRootLogin 为 yes退出编辑:按下 'Esc' 键,输入 ':wq',回车保存即可。重启 SSH:systemctl restart sshd大功告成,可以使用 ssh 链接了~~
-
植物大战僵尸杂交版v2.0来了!附最新安装教程! 今天来给大家分享最新版的植物大战僵尸杂交版,此版本由B站UP主@潜艇伟伟迷个人制作,光宣传片而论,短短十几天的时间就在B站平台爆火,达到了500w的播放量,甚至引得各大直播平台的知名主播都在闲暇之余畅玩。很多小伙伴想玩却不知道如何下载安装,今天就来教大家详细的安装步骤,感兴趣的小伙伴抓紧跟我一起来看看吧!{lamp/}{mtitle title="植物大战僵尸杂交V2.0.88最新版(安装教程)"/}{lamp/}在网盘下载电脑后,鼠标右键压缩包选择解压到当前文件夹。鼠标右键选择管理员身份运行植物大战僵尸杂交版v2.0.88安装程序。耐心等待安装完成,点击开始使用。{lamp/}{mtitle title="全屏游戏教程"/}{lamp/}回到解压后的文件夹,找到【Magpiev0.5.2】压缩包-右键【magpie】-【解压到当前文件夹】。双击运行magpie程序。按照下面进行选项进行设置。设置完成后,点击【五秒后放大】。注:部分电脑可能出现无法放大报错,原因不明。这款植物大战僵尸杂交版游戏模式创意十足,可玩性相当高,非常容易上头,感兴趣的小伙伴抓紧下载体验吧!好了,本期的分享就到这里我们下期再见!游戏获取{cloud title="植物大战僵尸杂交版v2.0.88安装程序" type="ct" url="https://www.123pan.com/s/shFiVv-UTRKA.html" password="HPhp"/}
-
优选 Cloudflare 官方 / 中转 IP Cloudflare 官方的 IP 很好理解,就是各个边缘节点的 IP。哪怕在全球大部分地方使用了 Anycast 技术, 但不同 IP 在中国大陆的访问体验还是有很大差别。小站收集了很多使用官方 IP 的网站,我们可以通过 DNS 记录查询的方式得到这些 IP,并通过本地测速或者拨测的方式进行筛选。#来源:https://blog.misaka.rest/2023/08/12/pick-cf-best-domain/ #引用时删去部分无效域名 time.cloudflare.com shopify.com time.is icook.hk icook.tw ip.sb japan.com malaysia.com russia.com singapore.com skk.moe www.visa.com www.visa.com.sg www.visa.com.hk www.visa.com.tw www.visa.co.jp www.visakorea.com www.gco.gov.qa www.gov.se www.gov.ua www.digitalocean.com www.csgo.com www.shopify.com www.whoer.net www.whatismyip.com www.ipget.net www.hugedomains.com www.udacity.com www.4chan.org www.okcupid.com www.glassdoor.com www.udemy.com www.baipiao.eu.org alejandracaiccedo.com log.bpminecraft.com www.boba88slot.com gur.gov.ua www.zsu.gov.ua www.iakeys.com edtunnel-dgp.pages.dev www.d-555.com fbi.gov www.sean-now.com download.yunzhongzhuan.com whatismyipaddress.com www.ipaddress.my www.pcmag.com www.ipchicken.com www.iplocation.net iplocation.io www.who.int www.wto.org #其他选择,都是官方 IP 优选 jp.byun.eu.org un.goasa.top emby2.misakaf.org也有大佬做好了一个优选的结果,可以根据需要即取即用:https://stock.hostmonit.com/CloudFlareYes至于中转 IP,其实就是第二层「反向代理」,通过反代 Cloudflare 边缘节点提供服务。中转 IP 大都是个人自用,获取它们的方法大都是大批量的端口扫描,具体细节这里就不再展开了。也是因此,中转 IP 存活的时间都十分短暂,对于网站加速来说,除非自己拿服务器搭建反向代理,否则几乎没有使用价值。使用方法在域名解析里设置国内运营商线路 CNAME解析 到各个优选地址。