搜索到
266
篇与
的结果
-
 Jenkins+Docker 实现一键自动化部署项目!步骤齐全,少走坑路 本文章实现最简单全面的 Jenkins+docker+springboot 一键自动部署项目,步骤齐全,少走坑路。环境:Centos7+Git(Gitee)简述实现步骤:在 docker 安装 jenkins,配置 jenkins 基本信息,利用 Dockerfile 和 shell 脚本实现项目自动拉取打包并运行。安装 dockerdocker 安装社区版本 CE确保 yum 包更新到最新。yum update卸载旧版本(如果安装过旧版本的话)yum remove docker docker-common docker-selinux docker-engine安装需要的软件包yum install -y yum-utils device-mapper-persistent-data lvm2设置 yum 源yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo安装 dockeryum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0 yum install <自己的版本> # 例如:sudo yum install docker-ce-17.12.0.ce启动和开机启动systemctl start docker systemctl enable docker验证安装是否成功docker version安装 JenkinsJenkins 中文官网安装 Jenkinsdocker 安装一切都是那么简单,注意检查 8080 是否已经占用!如果占用修改端口docker run --name jenkins -u root --rm -d -p 8080:8080 -p 50000:50000 -v /var/jenkins_home:/var/jenkins_home -v /var/run/docker.sock:/var/run/docker.sock jenkinsci/blueocean如果没改端口号的话安装完成后访问地址=> http://{部署Jenkins所在服务IP}:8080此处会有几分钟的等待时间。初始化 Jenkins详情见官网教程=> https://www.jenkins.io解锁 Jenkins进入 Jenkins 容器:docker exec -it {Jenkins容器名} bash # 例如 `docker exec -it jenkins bash`查看密码:cat /var/lib/jenkins/secrets/initialAdminPassword复制密码到输入框里面安装插件选择第一个:安装推荐的插件创建管理员用户此账户一定要记住哦系统配置安装需要插件进入【首页】–【系统管理】–【插件管理】–【可选插件】搜索以下需要安装的插件,点击安装即可。安装 Maven Integration安装 Publish Over SSH(如果不需要远程推送,不用安装)如果使用 Gitee 码云,安装插件 Gitee(Git 自带不用安装)配置 Maven进入【首页】–【系统管理】–【全局配置】,拉到最下面 maven–maven 安装创建任务新建任务点击【新建任务】,输入任务名称,点击构建一个自由风格的软件项目源码管理点击【源码管理】–【Git】,输入仓库地址,添加凭证,选择好凭证即可。构建触发器点击【构建触发器】–【构建】–【增加构建步骤】–【调用顶层Maven目标】–【填写配置】–【保存】此处命令只是 install,看是否能生成 jar 包clean install -Dmaven.test.skip=true保存点击【保存】按钮即可测试该功能测试是否能正常打包构建查看日志点击正在构建的任务,或者点击任务名称,进入详情页面,查看控制台输出,看是否能成功打成 jar 包。该处日志第一次可能下载依赖 jar 包失败,再次点击构建即可成功。查看项目位置cd /var/jenkins_home/workspacell 命令即可查看是否存在运行项目因为我们项目和 jenkins 在同一台服务器,所以我们用 shell 脚本运行项目,原理既是通过 dockerfile 打包镜像,然后 docker 运行即可。Dockerfile在 springboot 项目根目录新建一个名为 Dockerfile 的文件,注意没有后缀名,其内容如下:(大致就是使用 jdk8,把 jar 包添加到 docker 然后运行 prd 配置文件)FROM jdk:8 VOLUME /tmp ADD target/zx-order-0.0.1-SNAPSHOT.jar app.jar EXPOSE 8888 ENTRYPOINT ["Bash","-DBash.security.egd=file:/dev/./urandom","-jar","/app.jar","--spring.profiles.active=prd"]修改 jenkins 任务配置配置如下:-t:指定新镜像名.:表示Dockfile在当前路径cd /var/jenkins_home/workspace/zx-order-api docker stop zx-order || true docker rm zx-order || true docker rmi zx-order || true docker build -t zx-order . docker run -d -p 8888:8888 --name zx-order zx-order:latest备注:我上图用了 docker logs -f 是为了方便看日志,真实不要用,因为会一直等待日志,构建任务会失败加|| true 是如果命令执行失败也会继续实行,为了防止第一次没有该镜像报错保存点击 保存 即可构建查看 jenkins 控制台输出,输出如下,证明成功!验证docker ps 查看是否有自己的容器 docker logs 自己的容器名 查看日志是否正确浏览器访问项目试一试
Jenkins+Docker 实现一键自动化部署项目!步骤齐全,少走坑路 本文章实现最简单全面的 Jenkins+docker+springboot 一键自动部署项目,步骤齐全,少走坑路。环境:Centos7+Git(Gitee)简述实现步骤:在 docker 安装 jenkins,配置 jenkins 基本信息,利用 Dockerfile 和 shell 脚本实现项目自动拉取打包并运行。安装 dockerdocker 安装社区版本 CE确保 yum 包更新到最新。yum update卸载旧版本(如果安装过旧版本的话)yum remove docker docker-common docker-selinux docker-engine安装需要的软件包yum install -y yum-utils device-mapper-persistent-data lvm2设置 yum 源yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo安装 dockeryum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0 yum install <自己的版本> # 例如:sudo yum install docker-ce-17.12.0.ce启动和开机启动systemctl start docker systemctl enable docker验证安装是否成功docker version安装 JenkinsJenkins 中文官网安装 Jenkinsdocker 安装一切都是那么简单,注意检查 8080 是否已经占用!如果占用修改端口docker run --name jenkins -u root --rm -d -p 8080:8080 -p 50000:50000 -v /var/jenkins_home:/var/jenkins_home -v /var/run/docker.sock:/var/run/docker.sock jenkinsci/blueocean如果没改端口号的话安装完成后访问地址=> http://{部署Jenkins所在服务IP}:8080此处会有几分钟的等待时间。初始化 Jenkins详情见官网教程=> https://www.jenkins.io解锁 Jenkins进入 Jenkins 容器:docker exec -it {Jenkins容器名} bash # 例如 `docker exec -it jenkins bash`查看密码:cat /var/lib/jenkins/secrets/initialAdminPassword复制密码到输入框里面安装插件选择第一个:安装推荐的插件创建管理员用户此账户一定要记住哦系统配置安装需要插件进入【首页】–【系统管理】–【插件管理】–【可选插件】搜索以下需要安装的插件,点击安装即可。安装 Maven Integration安装 Publish Over SSH(如果不需要远程推送,不用安装)如果使用 Gitee 码云,安装插件 Gitee(Git 自带不用安装)配置 Maven进入【首页】–【系统管理】–【全局配置】,拉到最下面 maven–maven 安装创建任务新建任务点击【新建任务】,输入任务名称,点击构建一个自由风格的软件项目源码管理点击【源码管理】–【Git】,输入仓库地址,添加凭证,选择好凭证即可。构建触发器点击【构建触发器】–【构建】–【增加构建步骤】–【调用顶层Maven目标】–【填写配置】–【保存】此处命令只是 install,看是否能生成 jar 包clean install -Dmaven.test.skip=true保存点击【保存】按钮即可测试该功能测试是否能正常打包构建查看日志点击正在构建的任务,或者点击任务名称,进入详情页面,查看控制台输出,看是否能成功打成 jar 包。该处日志第一次可能下载依赖 jar 包失败,再次点击构建即可成功。查看项目位置cd /var/jenkins_home/workspacell 命令即可查看是否存在运行项目因为我们项目和 jenkins 在同一台服务器,所以我们用 shell 脚本运行项目,原理既是通过 dockerfile 打包镜像,然后 docker 运行即可。Dockerfile在 springboot 项目根目录新建一个名为 Dockerfile 的文件,注意没有后缀名,其内容如下:(大致就是使用 jdk8,把 jar 包添加到 docker 然后运行 prd 配置文件)FROM jdk:8 VOLUME /tmp ADD target/zx-order-0.0.1-SNAPSHOT.jar app.jar EXPOSE 8888 ENTRYPOINT ["Bash","-DBash.security.egd=file:/dev/./urandom","-jar","/app.jar","--spring.profiles.active=prd"]修改 jenkins 任务配置配置如下:-t:指定新镜像名.:表示Dockfile在当前路径cd /var/jenkins_home/workspace/zx-order-api docker stop zx-order || true docker rm zx-order || true docker rmi zx-order || true docker build -t zx-order . docker run -d -p 8888:8888 --name zx-order zx-order:latest备注:我上图用了 docker logs -f 是为了方便看日志,真实不要用,因为会一直等待日志,构建任务会失败加|| true 是如果命令执行失败也会继续实行,为了防止第一次没有该镜像报错保存点击 保存 即可构建查看 jenkins 控制台输出,输出如下,证明成功!验证docker ps 查看是否有自己的容器 docker logs 自己的容器名 查看日志是否正确浏览器访问项目试一试 -
Linux 命令复习 常用命令1、目录操作cd 切换目录cd / 切换到根目录cd ~ 回到个人用户的主目录ls 查看当前目录下所有文件的详细信息 list 的意思ll 查看当前目录下所有文件的详细信息pwd 显示当前目录的全路径. 当前目录.. 上级目录2、文件操作cp 复制mv 重命名、剪切移动位置rm 删除 加上 -rf 就不会出现提示直接删除mkdir test 在当前目录下创建一个 test 文件夹touch a.txt 在当前目录下创建一个文件 a.txt./文件名 执行文件(切换到那个目录然后执行)3、文件编辑vi a.txt 编辑,文件编辑器进入后只能查看,按 i 进入编辑模式,可以移动光标进行文本编辑操作按 esc 退出编辑模式输入:wq 保存并退出(w 代表保存,q 代表退出)输入/abc 回车 搜索文件中包含 abc 的内存4、文件查看cat a.txt 一次性读取并打印 a.txt 文件里的所有信息more a.txt 读取 a.txt 文件,每次读取一屏幕,按空格键翻页tail -200 a.txt 读取后面两百行(看日志排查错误的时候,后面是最新的)tail 是尾巴的意思tail -f a.txt 实时读取这个文件(监控日志用)head -10 a.txt 从前往后读 10 行5、搜索find / -name a.txt 从根目录全局搜索(当问你我想找系统有没有 a.txt 这个文件的时候用)我给你一个日志文件,你给我找出出现错误的那行数据,怎么操作?grep "ClassLoaderLogManager" 日志文件名grep "ERROR" 日志文件名grep "EXCEPTION" 日志文件名有时候只看这行数据没用,因为错误信息太长太多了,我们怎么筛选grep -A 10 "error" test.log -A 表 after 包含这个行以及后面 10 行grep -B 10 "error" test.log -B 表示 before 包含这行和前面 10 行grep -C 10 "error" test.log -C 表示 A 和 B 的结合 包含前 10 和后 10 行其实这样看还是乱,用sz error.log 把日志下载到本地看6、其他命令tar 和 rpm 可以安装 mysql、jdk 等环境ifconfig 查看网络设备信息free -h 检查服务器内存是否足够df -lh 查看磁盘空间大小uname -a 查看系统版本yum install 安装 javajava -jar 可以启动项,但是这个是不是后台启动nohup java -jar 后台启动项目7、进程命令top 查看所有线程 像 window任务管理器ps -ef 看看有没有进程ps -ef|grep 'java' 直接 ps -ef 搜到太多,通过管道符加 grep 只看 java 项目kill -9 进程 id 看查看出进程 id 然后用 kill 删除-9 强行删除ps 和 top 的区别?ps 是查看瞬间的信息,主要查看需要查看的进程top 可以持续监控进程信息,还可以看到性能,还可以操作进程,主要看内存和 cpu 占用情况netstat -anp | grep 8080 查看 8080 端口占用情况8、文件权限文字设定法 1)u:表示属主(user) 2)g:表示同组人(group) 3)o:其他人 (other) 4)a:所有人 (all) 5)+:表示增加权限 -:表示去掉权限 例如:修改 main.c 文件的所有者权限:1).取消写权限:chmod u-w main.c2).成为可写可读的chmod u=rw main.c3).同时修改 main.c 的属主权限和组用户权限:chmod u-w,g+x main.c2)数字设定法 采用数字设定法时,权限通常由三位数字组成,每一位数字代表一种角色的权限。每个角色的数值由其所具有的权限对应的数值之和构成;1)写权限 r : (read)读权限 ,值为 4(100)2)读权限 w : (write)写权限 ,值为 2(010)3)执行权限 x: (execute)执行权限 ,值为 1(001)4)格式: chmod nnn 文件名
-
你知道 ping 命令是如何工作的吗? 你知道 ping 命令是如何工作的吗?一、介绍 ICMP 协议二、为什么需要 ICMP?三、ICMP 的格式四、查询报文五、差错报文3-目的不可达4-原点抑制消息11-ICMP 超时5-重定向六、ping 的发送和接收过程1.向目的主机发送回显请求2.目的服务器发送回显应答3.源主机显示相关信息七、ICMP—Traceroute 命令你知道 ping 命令是如何工作的吗?我们用来测试一台机器与另一台机器的网络连通性一般会使用 ping 命令,那么你知道 ping 命令是如何工作的吗?ping 命令是基于 ICMP 协议工作的。一、介绍 ICMP 协议因特网控制报文协议ICMP(Internet Control Message Protocol)是一个「差错报告机制」 ,其主要用在 IP 机器与路由器之间传递控制信息,其一般用于报告主机是否可达、路由是否可用。二、为什么需要 ICMP?在网络数据包的传输过程中,经常会遇到各种各样的问题,IP 协议提供 Best-Effort(尽力而为)的服务,尽力而为的意思是当网络发生拥塞的时候,会立刻丢弃网络数据包,一直到网络拥塞现象减轻时。所以经常有些数据包中途被丢弃,可能还有其他更多的问题,所以需要网络数据包在出现问题时,机器向上层协议报告异常,以便进行流量控制和差错控制,使用 ICMP 就可以实现这一功能。三、ICMP 的格式ICMP 的格式上图是 ICMP 的格式,IP 数据报由 IP 头和 ICMP 报文组成。ICMP 报文由 8 位的类型、8 位的代码、16 位的校验和 ICMP 都数据部分组成。ICMP 的数据部分根据类型和代码不同而不同,如果是请求与响应的数据包,那么数据部分由 16 位的标识符、16 位的序号以及数据组成。如果是差错报文,那么数据部分由两个 16 位的 unused 部分和 IP 头、8 字节的正文组成。ICMP 报文分类大家可以看华为的文档,我这里不在叙述: 《什么是 ICMP?ICMP 如何工作?》四、查询报文我们的 ping 命令就是查询报文,如果一切顺利,我们发送 8.echo 请求,然后会收到 0.echo 响应,这就证明两机器之间是连通的。但是这个数据包比原生的 ICMP,多了两个字段——标识符、序号。怎么理解呢?如果你搞过装修,你应该知道建材店之间组成的销售联盟,联盟派出去两拨人,一批是跑业务的,一批是做广告的,都穿着同样的广告衫,需要一个标识区分这两批人。而派出去的人需要编号,如果到了吃午饭的时间,出去跑业务的 20 个人回来一小部分,说明情况不妙,如果全部回来,说明情况很好。在「选项数据」 中,ping 还会存放发送请求的时间值,来计算往返时间,说明路程的长短。五、差错报文根据《什么是 ICMP?ICMP 如何工作?》这篇文章我们可以了解下面几种常见的 ICMP 差错报文:3-目的不可达4-原点抑制消息11-ICMP 超时5-重定向3-目的不可达当类型 3 目的不可达,有以下几种常见代码:Code描述查询/差错0目标网络不可达报文差错1目标主机不可达报文差错2目标协议不可达报文差错3目标端口不可达报文差错4要求分段并设置DF flag标志报文差错出现 目标网络不可达报文 的情况是数据包到达路由器,但是路由表中没有数据包中 IP 地址的网络号。目标主机不可达报文 是路由器中没有找到目标主机的信息,也有可能是目标主机没有连接到网络。目标协议不可达报文 情况当你给目标主机发送 UDP 报文时,目标主机的防火墙禁止 UDP 协议数据包进入,于是 ICMP 通知目标协议不可达。目标端口不可达报文 是你的数据包要进入目标主机的 22 端口,建立 SSH 连接,而目标主机的 22 端口没有开放,这时候 ICMP 就会返回目标端口不可达报文给源主机。要求分段并设置DF flag标志报文 的情况如下:源主机发送的IP数据包首部的「分片禁止标志位」设置为1之后,路由器遇到超过MTU大小的数据包会直接抛弃,不会分片,然后 ICMP给源主机发送要求分段并设置DF flag标志报文4-原点抑制消息如果网络中遇到拥塞,就能向源主机发送一个 ICMP 原点抑制消息,收到该消息的机器就会增大数据包的传输间隔。是为原点抑制。11-ICMP 超时为了限制 IP 数据包在计算机网络中的存在的时间,我们给数据包设计一个值TTL,能够避免 IP 包在网络中的无限循环和收发,节省了网络资源。但是为了能使 IP 包的发送者能收到告警消息,ICMP 开始大显身手,路由器会发送一个 ICMP 「超时消息」 给源主机。5-重定向如若路由器发现源主机不是使用「最优路径」 发送数据,路由器就会发送重定向消息给源主机。六、ping 的发送和接收过程我们使用 ping 命令去请求同一个子网的目的主机。1. 向目的主机发送回显请求首先,机器会构建一个类型为 8、代号为 0 的 Echo 请求报文。向目的主机发送回显请求通过上图,我们可以了解,ICMP 的类型是 8,代码是 0 等数据。2. 目的服务器发送回显应答目的服务器发送回显应答通过比较,我们可以看到在 ICMP 报文层,Echo 请求报文与 Echo 响应报文除了 Type、Code(看起来没变化,其实含义已经不同)发生变化,其他基本上都是一样的。ICMP 报文3. 源主机显示相关信息源主机显示相关信息源主机显示相关信息发送回显请求数据包的时间,与接收到回显应答数据包的时间差,就能计算出数据包一去一回所需要的时间。七、ICMP—Traceroute 命令Traceroute 能够利用 ICMP 的规则,故意制造一些产生错误的场景。Traceroute 的第一个作用为「故意设置特殊的 TTL,来追踪去往目的地时沿途经过的路由器。」思路很骚啊~我给你慢慢道来:先设置 TTL 为 1,数据包到第一个路由器就嗝屁,临死前把第一个路由器的 IP 搞到手了。返回时间超时的 ICMP 差错报文。然后设置 TTL 为 2,数据包到第二个路由器嗝屁,临死前把第二个路由器的 IP 搞到手。再设置 TTL 为 3...以此类推,直到到达目的主机,如此就拿到了线路上所有路由器的 IP。那么 Traceroute 怎么知道自己发送的 UDP 包到达目的主机呢?思路也很骚啊!!!它用不可能出现的值作为 UDP 的端口号,数据报达到目的主机,就会返回 ICMP 差错报文,类型为端口不可达。「Traceroute 还有一个作用是故意设置不分片,从而确定路径的 MTU。」这个很容易想到啊,一旦返回类型为“需要进行分片但设置了不分片位”的 ICMP 差错报文就减小分组长度,直到达到目的主机,这不就测试出了整个路径的 MTU 吗?好家伙好家伙,思路真棒!点赞!别忘了给咱家点个赞啊!
-
Typecho开启Gzip压缩加速网站 Gzip简介GZip压缩,是一种网站速度优化技术,也是一把SEO优化利器,许多网站都采用了这种技术,以达到提升网页打开速度、缩短网页打开时间的目的。网站采用Gzip压缩,还有一个好处,就是让你少了一份流量超标的担心。因为Gzip开启以后会将输出到用户浏览器的数据进行压缩的处理,这样就会减小通过网络传输的数据量,而这个,也正是提升网页打开时间的原因所在。首先看未开启的效果(本主题为例)从上图可以看到,这个api接口的大小是21kb,请求时间539ms接着开启gzip压缩很明显的可以看到区别,压缩后只有4.5kb大小,并且时间缩短到了99ms,极大的优化了网站速度开启方法打开typecho目录下的 index.php,并在开头添加 ob_start('ob_gzhandler'); 即可。
-
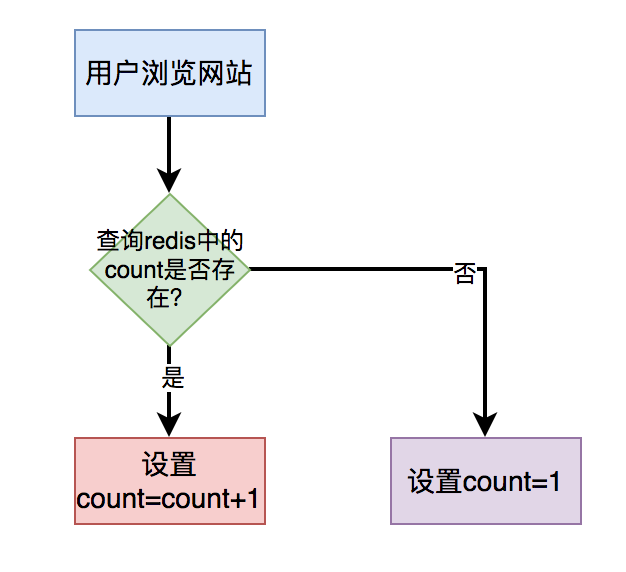
count(*) 导致接口性能差可能是这个原因! 最近我在公司优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助。我们使用的数据库是Mysql8,使用的存储引擎是Innodb。这次优化除了优化索引之外,更多的是在优化count(*)。通常情况下,分页接口一般会查询两次数据库,第一次是获取具体数据,第二次是获取总的记录行数,然后把结果整合之后,再返回。查询具体数据的 sql,比如是这样的:select id,name from user limit 1,20;它没有性能问题。但另外一条使用 count(*)查询总记录行数的 sql,例如:select count(\*) from user;却存在性能差的问题。为什么会出现这种情况呢?1. count(*)为什么性能差?在 Mysql 中,count(*)的作用是统计表中记录的总行数。而count(*)的性能跟存储引擎有直接关系,并非所有的存储引擎,count(*)的性能都很差。在 Mysql 中使用最多的存储引擎是:innodb和myisam。在 myisam 中会把总行数保存到磁盘上,使用 count(*)时,只需要返回那个数据即可,无需额外的计算,所以执行效率很高。而 innodb 则不同,由于它支持事务,有MVCC(即多版本并发控制)的存在,在同一个时间点的不同事务中,同一条查询 sql,返回的记录行数可能是不确定的。在 innodb 使用 count(*)时,需要从存储引擎中一行行的读出数据,然后累加起来,所以执行效率很低。如果表中数据量小还好,一旦表中数据量很大,innodb 存储引擎使用 count(*)统计数据时,性能就会很差。2. 如何优化 count(*)性能?从上面得知,既然count(*)存在性能问题,那么我们该如何优化呢?我们可以从以下几个方面着手。2.1 增加 redis 缓存对于简单的 count(*),比如:统计浏览总次数或者浏览总人数,我们可以直接将接口使用 redis 缓存起来,没必要实时统计。当用户打开指定页面时,在缓存中每次都设置成 count = count+1 即可。用户第一次访问页面时,redis 中的 count 值设置成 1。用户以后每访问一次页面,都让 count 加 1,最后重新设置到 redis 中。这样在需要展示数量的地方,从 redis 中查出 count 值返回即可。该场景无需从数据埋点表中使用 count(*)实时统计数据,性能将会得到极大的提升。不过在高并发的情况下,可能会存在缓存和数据库的数据不一致的问题。但对于统计浏览总次数或者浏览总人数这种业务场景,对数据的准确性要求并不高,容忍数据不一致的情况存在。2.2 加二级缓存对于有些业务场景,新增数据很少,大部分是统计数量操作,而且查询条件很多。这时候使用传统的 count(*)实时统计数据,性能肯定不会好。假如在页面中可以通过 id、name、状态、时间、来源等,一个或多个条件,统计品牌数量。这种情况下用户的组合条件比较多,增加联合索引也没用,用户可以选择其中一个或者多个查询条件,有时候联合索引也会失效,只能尽量满足用户使用频率最高的条件增加索引。也就是有些组合条件可以走索引,有些组合条件没法走索引,这些没法走索引的场景,该如何优化呢?答:使用二级缓存。二级缓存其实就是内存缓存。我们可以使用caffine或者guava实现二级缓存的功能。目前SpringBoot已经集成了 caffine,使用起来非常方便。只需在需要增加二级缓存的查询方法中,使用@Cacheable注解即可。@Cacheable(value = "brand", , keyGenerator = "cacheKeyGenerator") public BrandModel getBrand(Condition condition) { return getBrandByCondition(condition); }然后自定义 cacheKeyGenerator,用于指定缓存的 key。public class CacheKeyGenerator implements KeyGenerator { @Override public Object generate(Object target, Method method, Object... params) { return target.getClass().getSimpleName() + UNDERLINE + method.getName() + "," + StringUtils.arrayToDelimitedString(params, ","); } }这个 key 是由各个条件组合而成。这样通过某个条件组合查询出品牌的数据之后,会把结果缓存到内存中,设置过期时间为 5 分钟。后面用户在 5 分钟内,使用相同的条件,重新查询数据时,可以直接从二级缓存中查出数据,直接返回了。这样能够极大的提示 count(*)的查询效率。但是如果使用二级缓存,可能存在不同的服务器上,数据不一样的情况。我们需要根据实际业务场景来选择,没法适用于所有业务场景。2.3 多线程执行不知道你有没有做过这样的需求:统计有效订单有多少,无效订单有多少。这种情况一般需要写两条 sql,统计有效订单的 sql 如下:select count(\*) from order where status=1;统计无效订单的 sql 如下:select count(\*) from order where status=0;但如果在一个接口中,同步执行这两条 sql 效率会非常低。这时候,可以改成成一条 sql:select count(\*),status from order group by status;使用group by关键字分组统计相同 status 的数量,只会产生两条记录,一条记录是有效订单数量,另外一条记录是无效订单数量。但有个问题:status 字段只有 1 和 0 两个值,重复度很高,区分度非常低,不能走索引,会全表扫描,效率也不高。还有其他的解决方案不?答:使用多线程处理。我们可以使用CompleteFuture使用两个线程异步调用统计有效订单的 sql 和统计无效订单的 sql,最后汇总数据,这样能够提升查询接口的性能。2.4 减少 join 的表大部分的情况下,使用 count(*)是为了实时统计总数量的。但如果表本身的数据量不多,但 join 的表太多,也可能会影响 count(*)的效率。比如在查询商品信息时,需要根据商品名称、单位、品牌、分类等信息查询数据。这时候写一条 sql 可以查出想要的数据,比如下面这样的:select count(\*) from product p inner join unit u on p.unit_id = u.id inner join brand b on p.brand_id = b.id inner join category c on p.category_id = c.id where p.name='测试商品' and u.id=123 and b.id=124 and c.id=125;使用 product 表去join了 unit、brand 和 category 这三张表。其实这些查询条件,在 product 表中都能查询出数据,没必要 join 额外的表。我们可以把 sql 改成这样:select count(\*) from product where name='测试商品' and unit_id=123 and brand_id=124 and category_id=125;在 count(*)时只查 product 单表即可,去掉多余的表 join,让查询效率可以提升不少。2.5 改成 ClickHouse有些时候,join 的表实在太多,没法去掉多余的 join,该怎么办呢?比如上面的例子中,查询商品信息时,需要根据商品名称、单位名称、品牌名称、分类名称等信息查询数据。这时候根据 product 单表是没法查询出数据的,必须要去join:unit、brand 和 category 这三张表,这时候该如何优化呢?答:可以将数据保存到ClickHouse。ClickHouse 是基于列存储的数据库,不支持事务,查询性能非常高,号称查询十几亿的数据,能够秒级返回。为了避免对业务代码的嵌入性,可以使用Canal监听Mysql的binlog日志。当 product 表有数据新增时,需要同时查询出单位、品牌和分类的数据,生成一个新的结果集,保存到 ClickHouse 当中。查询数据时,从 ClickHouse 当中查询,这样使用 count(*)的查询效率能够提升 N 倍。需要特别提醒一下:使用 ClickHouse 时,新增数据不要太频繁,尽量批量插入数据。其实如果查询条件非常多,使用 ClickHouse 也不是特别合适,这时候可以改成ElasticSearch,不过它跟 Mysql 一样,存在深分页问题。3. count 的各种用法性能对比既然说到 count(*),就不能不说一下 count 家族的其他成员,比如:count(1)、count(id)、count(普通索引列)、count(未加索引列)。那么它们有什么区别呢?count(*) :它会获取所有行的数据,不做任何处理,行数加 1。count(1):它会获取所有行的数据,每行固定值 1,也是行数加 1。count(id):id 代表主键,它需要从所有行的数据中解析出 id 字段,其中 id 肯定都不为 NULL,行数加 1。count(普通索引列):它需要从所有行的数据中解析出普通索引列,然后判断是否为 NULL,如果不是 NULL,则行数+1。count(未加索引列):它会全表扫描获取所有数据,解析中未加索引列,然后判断是否为 NULL,如果不是 NULL,则行数+1。由此,最后 count 的性能从高到低是:count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)所以,其实count(*)是最快的。意不意外,惊不惊喜?千万别跟select * 搞混了
-
别总低头写代码,这128个网站收藏起来 大家好,推荐一些学习资源给大家当然大家可以留言评论自己发现的优秀资源地址搞学习TED(最优质的演讲):https://www.ted.com/谷粉学术:https://gfsoso.99lb.net/scholar.html大学资源网:http://www.dxzy163.com/简答题:http://www.jiandati.com/网易公开课:https://open.163.com/ted/网易云课堂:https://study.163.com/中国大学MOOC:http://www.icourse163.org哔哩哔哩弹幕网:https://www.bilibili.com我要自学网:http://www.51zxw.net知乎:https://www.zhihu.com学堂在线:http://www.xuetangx.com爱课程:http://www.icourses.cn猫咪论文:https://lunwen.im/iData(论文搜索):http://www.cn-ki.net文泉考试:https://www.wqkaoshi.comCSDN:https://www.csdn.net/找书籍书栈网(极力推荐):https://www.bookstack.cn/码农之家(计算机电子书下载):http://www.xz577.com鸠摩搜书:http://www.jiumodiary.com云海电子图书馆:http://www.pdfbook.cn周读(书籍搜索):http://ireadweek.com知轩藏书:http://www.zxcs.me/脚本之家电子书下载:https://www.jb51.net/books/搜书VIP-电子书搜索:http://www.soshuvip.com/all.html书格(在线古籍图书馆):https://new.shuge.org/caj云阅读:http://cajviewer.cnki.net/cajcloud/必看网(人生必看的书籍):https://www.biikan.com/冷知识 / 黑科技上班摸鱼必备(假装电脑系统升级):http://fakeupdate.net/PIECES 拼图(30 个 CSS 碎片进行拼图,呈现 30 种濒临灭绝的动物):http://www.species-in-pieces.com/图片立体像素画:https://pissang.github.io/voxelize-image/福利单词(一个不太正经的背单词网站):http://dict.ftqq.com查无此人(刷新网站,展现一张AI 生成的人脸照片):https://thispersondoesnotexist.com/在线制作地图图例:https://mapchart.net/创意光线绘画:http://weavesilk.com/星系观察:https://stellarium-web.org/煎蛋:http://jandan.net/渣男-说话的艺术:https://lovelive.tools/全历史:https://www.allhistory.com/iData:https://www.cn-ki.net/术语在线:http://www.termonline.cn/写代码GitHub:https://github.com/码云:https://gitee.com/源码之家:https://www.mycodes.net/JSON to Dart:https://javiercbk.github.io/json_to_dart/Json在线解析验证:https://www.json.cn/在线接口测试(Getman):https://getman.cn/资源搜索DogeDoge搜索引擎:https://www.dogedoge.com秘迹搜索:https://mijisou.com/小白盘:https://www.xiaobaipan.com/云盘精灵(资源搜索):http://www.yunpanjingling.com虫部落(资源搜索):http://www.chongbuluo.com如风搜(资源搜索):http://www.rufengso.net/爱扒:https://www.zyboe.com/小工具奶牛快传(在线传输文件利器):http://cowtransfer.com文叔叔(大文件传输,不限速):https://www.wenshushu.cn/云端超级应用空间(PS,PPT,Excel,Ai):https://uzer.me/香当网(年终总结,个人简历,事迹材料,租赁合同,演讲稿):https://www.xiangdang.net/二维码生成:https://cli.im/搜狗翻译:http://fanyi.sogou.com熵数(图表制作,数据可视化):https://dydata.io/appv2/#/pages/index/home拷贝兔:https://cp.anyknew.com/图片无限变放大:http://bigjpg.com/zh幕布(在线大纲笔记工具):http://mubu.com在线转换器(在线转换器转换任何测量单位):https://zh.justcnw.com/调查问卷制作:https://www.wenjuan.com/果核剥壳(软件下载):https://www.ghpym.com/软件下载:https://www.unyoo.com/MSDN我告诉你(windows10系统镜像下载):https://msdn.itellyou.cn/导航页(工具集)世界各国网址大全:http://www.world68.com/小森林导航:http://www.xsldh6.com/简捷工具:http://www.shulijp.com/NiceTool.net 好工具网:http://www.nicetool.net/现实君工具箱(综合型在线工具集成网站):http://tool.uixsj.cn/蓝调网站:http://lcoc.top/偷渡鱼:https://touduyu.com/牛导航:http://www.ziliao6.com/小呆导航:https://www.webjike.com/index.html简法主页:http://www.jianfast.com/KIM主页:https://kim.plopco.com/聚BT:https://jubt.net/cn/index.html精准云工具合集:https://jingzhunyun.com/兔2工具合集:https://www.tool2.cn/爱资料工具(在线实用工具集合):http://www.toolnb.com工具导航:https://hao.logosc.cn/看视频阿木影视:https://www.aosk.online/电影推荐(分类别致):http://www.mvcat.comAPP影院:https://app.movie动漫视频网:http://www.zzzfun.com/NO视频官网:http://www.novipnoad.com/大数据导航:http://hao.199it.com/VideoFk解析视频:http://www.videofk.com/学设计码力全开(产品/设计师/独立开发者的资源库):https://www.maliquankai.com/designnav/免费音频素材:https://icons8.cn/music新CG儿(视频素材模板,无水印+免费下载):https://www.newcger.com/Iconfont(阿里巴巴矢量图标库):https://www.iconfont.cn/小图标下载:https://www.easyicon.net/Flight Icon:https://www.flighticon.co/第一字体转换器:http://www.diyiziti.com/doyoudosh(平面设计):http://www.doyoudo.com企业宣传视频在线制作:https://duomu.tv/MAKE海报设计官网:http://maka.im/一键海报神器:https://www.logosc.cn/photo/utm_source=hao.logosc.cn&utm_medium=referral字由(字体设计):http://www.hellofont.cn/查字体网站:https://fonts.safe.360.cn/爱给网(免费素材下载的网站,包括音效、配乐,3D、视频、游戏,平面、教程):http://www.aigei.com/在线视频剪辑:https://bilibili.clipchamp.com/editor搞文档即书(在线制作PPT):https://www.keysuper.com/PDF处理:https://smallpdf.com/cnPDF处理:https://www.ilovepdf.com/zh-cnPDF处理:https://www.pdfpai.com/PDF处理:https://www.hipdf.cn/图片压缩,PDF处理:https://docsmall.com/腾讯文档(在线协作编辑和管理文档):http://docs.qq.comProcessOn(在线协作制作结构图):http://www.processon.comiLovePDF(在线转换PDF利器):http://www.ilovepdf.comPPT在线制作:https://www.woodo.cn/PDF24工具(pdf处理工具):https://tools.pdf24.org/enIMGBOT(在线图片处理):http://www.imgbot.ai福昕云编辑(在线编辑PDF):http://edit.foxitcloud.cnTinyPNG(在线压缩图片):http://tinypng.com优品PPT(模板下载):http://www.ypppt.com/第一PPT(模板下载):http://www.1ppt.com/xiazai/三顿PPT导航:http://sandunppt.comExcel函数表:https://support.office.com/zh-cn/office/excel-函数-按字母顺序-b3944572-255d-4efb-bb96-c6d90033e188找图片电脑壁纸:https://unsplash.com/https://pixabay.com/https://visualhunt.com/https://www.ssyer.com/http://lcoc.top/bizhi/彼岸图网:http://pic.netbian.com/极像素(超高清大图):https://www.sigoo.com/免费版权图片搜索:https://www.logosc.cn/so/大家如果有好的网站,可在下方留言分享~
-
前端 Promise 最佳实践 本文将从 Web 前端入手,介绍如何使用 JavaScript 中的 Promise 对象来处理异步请求,同时提供一些使用 Promise 的最佳实践。如何使用 Promise 处理异步请求Web 前端开发经常涉及到处理异步请求的场景,例如从后端获取数据或调用浏览器 API 等。在 JavaScript 中,Promise 对象是一种用于处理异步操作的特殊对象,它可以使异步操作更加简单和可读。下面将介绍如何使用 Promise 处理异步请求,并提供一些最佳实践供您参考。Promise 简介Promise 对象是一种用于处理异步操作的特殊对象,它有三种状态:pending(进行中):初始状态,不是成功或失败状态。fulfilled(已成功):意味着操作成功完成。rejected(已失败):意味着操作失败。当 Promise对象 处于 pending 状态时,可以使用 then() 方法指定成功和失败的回调函数。如果 Promise对象 已经处于 fulfilled 或 rejected 状态,将立即执行相应的回调函数。下面是一个使用 Promise 处理异步请求的示例代码:function getData(url) { return new Promise((resolve, reject) => { const xhr = new XMLHttpRequest(); xhr.open("GET", url); xhr.onload = () => { if (xhr.status === 200) { resolve(xhr.responseText); } else { reject(new Error(xhr.statusText)); } }; xhr.onerror = () => reject(new Error("Network Error")); xhr.send(); }); } getData("https://example.com/todos/1") .then((data) => console.log(data)) .catch((error) => console.error(error));Promise 的最佳实践下面是一些使用 Promise 的最佳实践:1. 将 Promise 封装在函数中将 Promise 封装在函数中可以使代码更易读和易维护。下面是一个获取用户信息的函数示例:function getUserInfo(userId) { return new Promise((resolve, reject) => { const xhr = new XMLHttpRequest(); xhr.open("GET", `/api/users/${userId}`); xhr.onload = () => { if (xhr.status === 200) { resolve(JSON.parse(xhr.responseText)); } else { reject(new Error(xhr.statusText)); } }; xhr.onerror = () => reject(new Error("Network Error")); xhr.send(); }); } getUserInfo(1) .then((userInfo) => console.log(userInfo)) .catch((error) => console.error(error));2. 使用 Promise.all() 并行执行多个请求Promise.all() 方法可以并行执行多个 Promise 对象,并在所有 Promise 对象都成功时返回结果。下面是一个并行执行多个请求的示例代码:const promise1 = getData("/api/data1"); const promise2 = getData("/api/data2"); Promise.all([promise1, promise2]) .then(([data1, data2]) => { console.log(data1); console.log(data2); }) .catch((error) => console.error(error));3. 使用 Promise.race() 竞速执行多个请求Promise.race() 方法可以 竞速执行多个Promise对象 ,并返回第一个完成的 Promise 对象的结果。下面是一个竞速执行多个请求的示例代码:const promise1 = new Promise((resolve) => setTimeout(() => resolve("result1"), 1000)); const promise2 = new Promise((resolve) => setTimeout(() => resolve("result2"), 500)); Promise.race([promise1, promise2]) .then((result) => console.log(result)) .catch((error) => console.error(error));4. 使用 async/await 简化 Promise 的使用async/await 是一种基于 Promise 的语法糖,可以更简单地编写异步代码。使用 async/await,可以将 Promise 链式调用改为顺序调用,并使用 try/catch 语句处理错误。下面是一个使用 async/await 处理异步请求的示例代码:async function getUserInfo(userId) { try { const response = await fetch(`/api/users/${userId}`); const userInfo = await response.json(); return userInfo; } catch (error) { console.error(error); } } getUserInfo(1).then((userInfo) => console.log(userInfo));总结Promise 是一种用于处理异步操作的特殊对象,它可以使异步操作更加简单和可读。最佳实践包括将 Promise 封装在函数中、使用 Promise.all() 并行执行多个请求、使用 Promise.race() 竞速执行多个请求和使用 async/await 简化 Promise 的使用。使用这些技巧可以使异步代码更加易读和易维护。希望本篇文章对您有所帮助,如果您有任何疑问或建议,请随时在评论区留言。
-
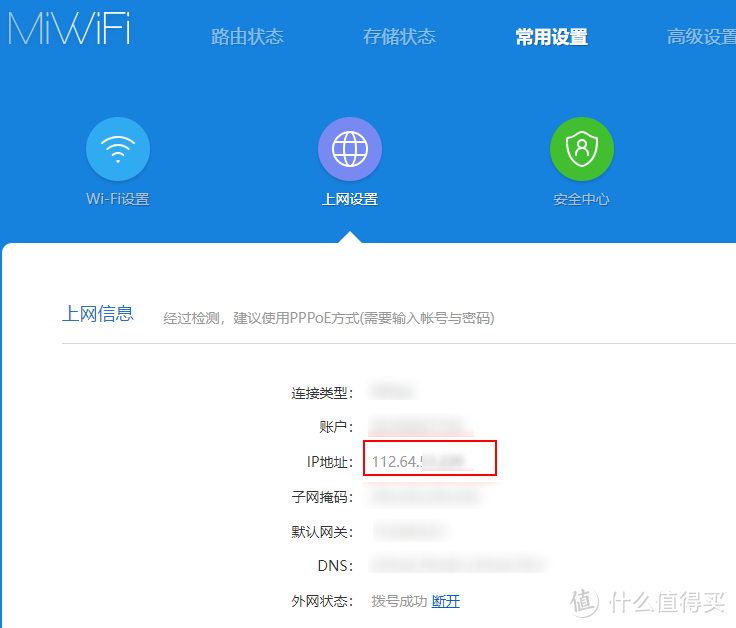
有了公网IP后该如何设置光猫和路由器,远程访问家中威联通NAS 使用官方提供的远程连接方案,速度普遍较慢,推荐还是搞一个公网IP来远程访问家中NAS。这样远程使用体验就和家中直接连接NAS差不多,墙裂推荐配置。那么我就简单分享下如何利用公网IP,远程访问家中NAS。一、申请公网IP公网IP现在申请应该都不难,多联系客服尝试下即可。我是打联通客服电话申请的,客服甚至都没问为什么,就给我提交了。之后另外一位客服打电话过来,问我是否确认要开通公网IP,得到确切答复后挂了电话,几分钟后收到短信显示公网IP已开通。如何查看公网IP是否已开通?首先登录路由器管理界面,查看本地IP地址。(演示截图来自小米路由器,其他路由器应该都类似)搜索引擎输入IP,第一个结果,就会显示本机IP。和上面的IP地址核对下,发现地址一致,表示公网IP已经有了。二、光猫改桥接模式因为现在宽带默认都是路由连接,无法设置端口转发,这样通过公网IP还是找不到家里的具体设备。这个时候我们就可以通过把光猫改成桥接模式,让路由器去拨号上网,就可以在路由器上设置端口转发,实现远程公网IP的访问。这一步我最终是找安装师傅帮忙完成了,所以这里无法分享详细过程。(白天上班,安装师傅不进家门,在门口连接我家WIFI就调好的,还是很方便的)`下面的是我之前自己尝试时候的一些经验,可以跳过不看,在此记录下,用于自己日后查询使用:过程我刚开始是自己尝试改的,但是因为家里联通宽带密码,不是默认的123456,登录光猫后台,密码被掩码加密了,无法直接查看。导致自己设置桥接后,无法成功拨号。光猫改桥接后,输入192.168.1.1进不去管理后台了,想恢复都不行。于是用网线将光猫和电脑连接,来勉强恢复到之前的状态,但是因为宽带密码问题还是无法连接宽带。经验折腾了很久,可以分享下自己学到的一些经验:其实超级管理员密码都比较好拿到,网上搜搜都能找到。比如上海联通超级管理员密码是:CUAdmin登录超级管理员后台后,可以在基本配置,上行线路配置中,查看到用户名、VLAN ID和密码,记下他们(如下图)。然后删除旧的配置,新建一个,连接模式改成桥接,其他的参考之前的配置。然后在LAN配置中,关闭DHCP。之后在路由器上网方式里面,选择PPPoE,输入账号和密码,不出意外,应该就可以正常上网了。`三、路由器设置端口转发添加端口转发规则(以小米路由器做演示,其它路由后台操作应该类似,可作为参考)我们登录路由器后台,找到端口转发,点击添加规则然后点击保存并生效即可设置完成!这个时候,我们在浏览器,输入公网IP:5000,即可快速访问家里的NAS了。类似这样:http://114.177.65.27:5000/打开后,就可以看到NAS的登录界面。这样就可以实现远程访问家里的NAS了,使用起来和家里局域网访问是一样的,速度也很快,体验不错!四、设置动态DNS虽然有公网IP,但是在重启路由器或者断网重连后,会自动更换,如果在外地,IP更改后,就无法通过直接的IP访问家里的NAS了。我们可以利用动态DNS,也就是DDNS,通过一个固定的域名,来实现访问,这样就避免了公网IP更换的烦恼。威联通有提供官方的动态DNS域名,我们可以直接配置使用。首先,我们打开威联通的云连通:找到My DDNS,点击启用即可。之后就可以通过类似:XX.myqnapcloud.cn:5000 来远程访问家中的NAS了。威联通DDNS会自动获取最新的DDNS。拓展内容:如何设置自定义域名(内容留存,未实际配置)打开威联通控制台,找到网络与虚拟交换机,点击打开。打开后,找到DDNS,点击新增可以自己选择免费的DDNS服务(实际列表中大部分都是收费的),推荐No-IP,国内的PubYun(3322)等都开始收费了。或者选择Customized(自定义),使用腾讯云或者阿里云注册的域名来配置。阿里云的可以直接用这个Github项目来配置:aliyun-ddns注意DDNS自定义中的用户名和密码,实际上是平台ID和私钥,主机名称就是自己配置的域名。
-
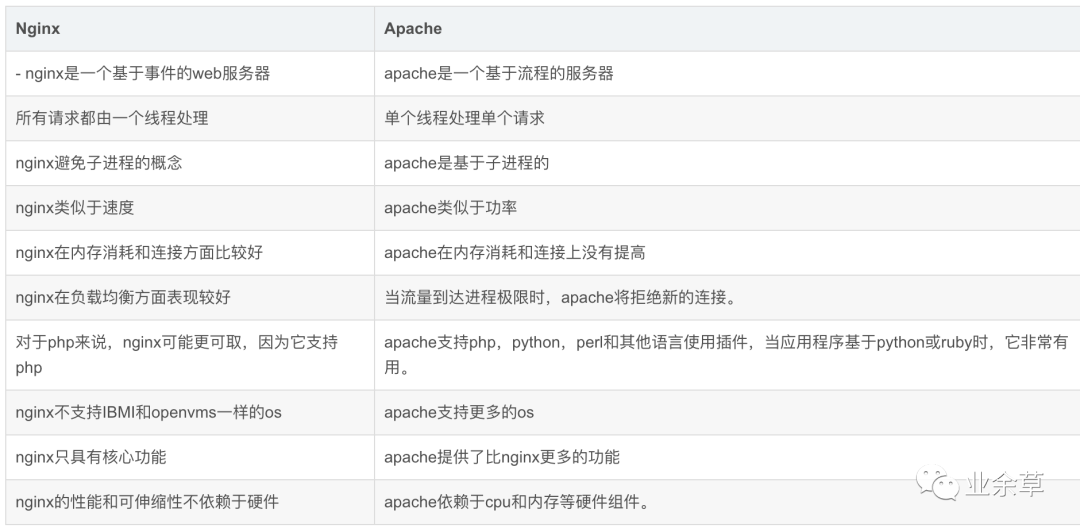
Nginx核心面试题40问,含答案! Nginx核心面试题40问,含答案!什么是Nginx?Nginx 有哪些优点?Nginx应用场景?Nginx怎么处理请求的?Nginx 是如何实现高并发的?什么是正向代理?什么是反向代理?反向代理服务器的优点是什么?Nginx目录结构有哪些?Nginx配置文件nginx.conf有哪些属性模块?cookie和session区别?为什么 Nginx 不使用多线程?nginx和apache的区别什么是动态资源、静态资源分离?为什么要做动、静分离?什么叫 CDN 服务?Nginx怎么做的动静分离?Nginx负载均衡的算法怎么实现的?策略有哪些?如何用Nginx解决前端跨域问题?Nginx虚拟主机怎么配置?location的作用是什么?限流怎么做的?漏桶流算法和令牌桶算法知道?Nginx配置高可用性怎么配置?Nginx怎么判断别IP不可访问?在nginx中,如何使用未定义的服务器名称来阻止处理请求?怎么限制浏览器访问?Rewrite全局变量是什么?Nginx 如何实现后端服务的健康检查?Nginx 如何开启压缩?ngx\_http\_upstream_module的作用是什么?什么是C10K问题?Nginx是否支持将请求压缩到上游?如何在Nginx中获得当前的时间?用Nginx服务器解释-s的目的是什么?如何在Nginx服务器上添加模块?生产中如何设置worker进程的数量呢?nginx状态什么是Nginx?Nginx是一个 轻量级/高性能的反向代理Web服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发,现在中国使用nginx网站用户有很多,例如:新浪、网易、 腾讯等。Nginx 有哪些优点?跨平台、配置简单。非阻塞、高并发连接:处理 2-3 万并发连接数,官方监测能支持 5 万并发。内存消耗小:开启 10 个 Nginx 才占 150M 内存。成本低廉,且开源。稳定性高,宕机的概率非常小。内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上Nginx应用场景?http服务器。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。虚拟主机。可以实现在一台服务器虚拟出多个网站,例如个人网站使用的虚拟机。反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会应为某台服务器负载高宕机而某台服务器闲置的情况。nginz 中也可以配置安全管理、比如可以使用Nginx搭建API接口网关,对每个接口服务进行拦截。Nginx怎么处理请求的?server { # 第一个Server区块开始,表示一个独立的虚拟主机站点 listen 80; # 提供服务的端口,默认80 server_name localhost; # 提供服务的域名主机名 location / { # 第一个location区块开始 root html; # 站点的根目录,相当于Nginx的安装目录 index index.html index.html; # 默认的首页文件,多个用空格分开 } # 第一个location区块结果 首先,Nginx 在启动时,会解析配置文件,得到需要监听的端口与 IP 地址,然后在 Nginx 的 Master 进程里面先初始化好这个监控的Socket(创建 S ocket,设置 addr、reuse 等选项,绑定到指定的 ip 地址端口,再 listen 监听)。然后,再 fork(一个现有进程可以调用 fork 函数创建一个新进程。由 fork 创建的新进程被称为子进程)出多个子进程出来。之后,子进程会竞争 accept 新的连接。此时,客户端就可以向 nginx 发起连接了。当客户端与nginx进行三次握手,与 nginx 建立好一个连接后。此时,某一个子进程会 accept 成功,得到这个建立好的连接的 Socket ,然后创建 nginx 对连接的封装,即 ngx\_connection\_t 结构体。接着,设置读写事件处理函数,并添加读写事件来与客户端进行数据的交换。最后,Nginx 或客户端来主动关掉连接,到此,一个连接就寿终正寝了。Nginx 是如何实现高并发的?如果一个 server 采用一个进程(或者线程)负责一个request的方式,那么进程数就是并发数。那么显而易见的,就是会有很多进程在等待中。等什么?最多的应该是等待网络传输。而 Nginx 的异步非阻塞工作方式正是利用了这点等待的时间。在需要等待的时候,这些进程就空闲出来待命了。因此表现为少数几个进程就解决了大量的并发问题。Nginx是如何利用的呢,简单来说:同样的 4 个进程,如果采用一个进程负责一个 request 的方式,那么,同时进来 4 个 request 之后,每个进程就负责其中一个,直至会话关闭。期间,如果有第 5 个request进来了。就无法及时反应了,因为 4 个进程都没干完活呢,因此,一般有个调度进程,每当新进来了一个 request ,就新开个进程来处理。「回想下,BIO 是不是存在酱紫的问题?」Nginx 不这样,每进来一个 request ,会有一个 worker 进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发 request ,并等待请求返回。那么,这个处理的 worker 不会这么傻等着,他会在发送完请求后,注册一个事件:“如果 upstream 返回了,告诉我一声,我再接着干”。于是他就休息去了。此时,如果再有 request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker 才会来接手,这个 request 才会接着往下走。这就是为什么说,Nginx 基于事件模型。由于 web server 的工作性质决定了每个 request 的大部份生命都是在网络传输中,实际上花费在 server 机器上的时间片不多。这是几个进程就解决高并发的秘密所在。即:webserver 刚好属于网络 IO 密集型应用,不算是计算密集型。异步,非阻塞,使用 epoll ,和大量细节处的优化。也正是 Nginx 之所以然的技术基石。什么是正向代理?一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。正向代理总结就一句话:代理端代理的是客户端。例如说:我们使用的OpenVPN 等等。什么是反向代理?反向代理(Reverse Proxy)方式,是指以代理服务器来接受 Internet上的连接请求,然后将请求,发给内部网络上的服务器并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。❝反向代理总结就一句话:代理端代理的是服务端。❞反向代理服务器的优点是什么?反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。「Nginx目录结构有哪些?」tree /usr/local/nginx /usr/local/nginx ├── client_body_temp ├── conf # Nginx所有配置文件的目录 │ ├── fastcgi.conf # fastcgi相关参数的配置文件 │ ├── fastcgi.conf.default # fastcgi.conf的原始备份文件 │ ├── fastcgi_params # fastcgi的参数文件 │ ├── fastcgi_params.default │ ├── koi-utf │ ├── koi-win │ ├── mime.types # 媒体类型 │ ├── mime.types.default │ ├── nginx.conf # Nginx主配置文件 │ ├── nginx.conf.default │ ├── scgi_params # scgi相关参数文件 │ ├── scgi_params.default │ ├── uwsgi_params # uwsgi相关参数文件 │ ├── uwsgi_params.default │ └── win-utf ├── fastcgi_temp # fastcgi临时数据目录 ├── html # Nginx默认站点目录 │ ├── 50x.html # 错误页面优雅替代显示文件,例如当出现502错误时会调用此页面 │ └── index.html # 默认的首页文件 ├── logs # Nginx日志目录 │ ├── access.log # 访问日志文件 │ ├── error.log # 错误日志文件 │ └── nginx.pid # pid文件,Nginx进程启动后,会把所有进程的ID号写到此文件 ├── proxy_temp # 临时目录 ├── sbin # Nginx命令目录 │ └── nginx # Nginx的启动命令 ├── scgi_temp # 临时目录 └── uwsgi_temp # 临时目录 Nginx配置文件nginx.conf有哪些属性模块?worker_processes 1;# worker进程的数量 events { # 事件区块开始 worker_connections 1024;# 每个worker进程支持的最大连接数 } # 事件区块结束 http { # HTTP区块开始 include mime.types;# Nginx支持的媒体类型库文件 default_type application/octet-stream;# 默认的媒体类型 sendfile on;# 开启高效传输模式 keepalive_timeout 65;# 连接超时 server { # 第一个Server区块开始,表示一个独立的虚拟主机站点 listen 80;# 提供服务的端口,默认80 server_name localhost;# 提供服务的域名主机名 location / { # 第一个location区块开始 root html;# 站点的根目录,相当于Nginx的安装目录 index index.html index.htm;# 默认的首页文件,多个用空格分开 } # 第一个location区块结果 error_page 500502503504 /50x.html;# 出现对应的http状态码时,使用50x.html回应客户 location = /50x.html { # location区块开始,访问50x.html root html;# 指定对应的站点目录为html } } ...... cookie和session区别?共同:存放用户信息。存放的形式:key-value格式 变量和变量内容键值对。区别:cookie存放在客户端浏览器每个域名对应一个cookie,不能跨跃域名访问其他cookie用户可以查看或修改cookiehttp响应报文里面给你浏览器设置钥匙(用于打开浏览器上锁头)session:存放在服务器(文件,数据库,redis)存放敏感信息锁头为什么 Nginx 不使用多线程?Apache: 创建多个进程或线程,而每个进程或线程都会为其分配 cpu 和内存(线程要比进程小的多,所以 worker 支持比 perfork 高的并发),并发过大会榨干服务器资源。Nginx: 采用单线程来异步非阻塞处理请求(管理员可以配置 Nginx 主进程的工作进程的数量)(epoll),不会为每个请求分配 cpu 和内存资源,节省了大量资源,同时也减少了大量的 CPU 的上下文切换。所以才使得 Nginx 支持更高的并发。nginx和apache的区别轻量级,同样起web服务,比apache占用更少的内存和资源。抗并发,nginx处理请求是异步非阻塞的,而apache则是阻塞性的,在高并发下nginx能保持低资源,低消耗高性能。高度模块化的设计,编写模块相对简单。最核心的区别在于apache是同步多进程模型,一个连接对应一个进程,nginx是异步的,多个连接可以对应一个进程。什么是动态资源、静态资源分离?动态资源、静态资源分离,是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路。动态资源、静态资源分离简单的概括是:动态文件与静态文件的分离。为什么要做动、静分离?在我们的软件开发中,有些请求是需要后台处理的(如:.jsp,.do 等等),有些请求是不需要经过后台处理的(如:css、html、jpg、js 等等文件),这些不需要经过后台处理的文件称为静态文件,否则动态文件。因此我们后台处理忽略静态文件。这会有人又说那我后台忽略静态文件不就完了吗?当然这是可以的,但是这样后台的请求次数就明显增多了。在我们对资源的响应速度有要求的时候,我们应该使用这种动静分离的策略去解决动、静分离将网站静态资源(HTML,JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问这里我们将静态资源放到 Nginx 中,动态资源转发到 Tomcat 服务器中去。当然,因为现在七牛、阿里云等 CDN 服务已经很成熟,主流的做法,是把静态资源缓存到 CDN 服务中,从而提升访问速度。相比本地的 Nginx 来说,CDN 服务器由于在国内有更多的节点,可以实现用户的就近访问。并且,CDN 服务可以提供更大的带宽,不像我们自己的应用服务,提供的带宽是有限的。什么叫 CDN 服务?CDN ,即内容分发网络。其目的是,通过在现有的 Internet中 增加一层新的网络架构,将网站的内容发布到最接近用户的网络边缘,使用户可就近取得所需的内容,提高用户访问网站的速度。一般来说,因为现在 CDN 服务比较大众,所以基本所有公司都会使用 CDN 服务。「Nginx怎么做的动静分离?」只需要指定路径对应的目录。location可以使用正则表达式匹配。并指定对应的硬盘中的目录。如下:(操作都是在Linux上)location /image/ { root /usr/local/static/; autoindex on; } 步骤:# 创建目录 mkdir /usr/local/static/image # 进入目录 cd /usr/local/static/image # 上传照片 photo.jpg # 重启nginx sudo nginx -s reload 打开浏览器 输入 server_name/image/1.jpg 就可以访问该静态图片了Nginx负载均衡的算法怎么实现的?策略有哪些?为了避免服务器崩溃,大家会通过负载均衡的方式来分担服务器压力。将对台服务器组成一个集群,当用户访问时,先访问到一个转发服务器,再由转发服务器将访问分发到压力更小的服务器。Nginx负载均衡实现的策略有以下五种:轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某个服务器宕机,能自动剔除故障系统。upstream backserver { server 192.168.0.12; server 192.168.0.13; } 权重 weightweight的值越大,分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。其次是为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。# 权重越高,在被访问的概率越大,如上例,分别是20%,80%。 upstream backserver { server 192.168.0.12 weight=2; server 192.168.0.13 weight=8; } ip_hash(IP绑定)每个请求按访问IP的哈希结果分配,使来自同一个IP的访客固定访问一台后端服务器,并且可以有效解决动态网页存在的session共享问题upstream backserver { ip_hash; server 192.168.0.12:88; server 192.168.0.13:80; } fair(第三方插件)必须安装upstream\_fair模块。对比 weight、ip\_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,响应时间短的优先分配。# 哪个服务器的响应速度快,就将请求分配到那个服务器上。 upstream backserver { server server1; server server2; fair; } url_hash(第三方插件)必须安装Nginx的hash软件包按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。upstream backserver { server squid1:3128; server squid2:3128; hash $request_uri; hash_method crc32; } 如何用Nginx解决前端跨域问题?使用Nginx转发请求。把跨域的接口写成调本域的接口,然后将这些接口转发到真正的请求地址。Nginx虚拟主机怎么配置?基于域名的虚拟主机,通过域名来区分虚拟主机——应用:外部网站基于端口的虚拟主机,通过端口来区分虚拟主机——应用:公司内部网站,外部网站的管理后台基于 ip 的虚拟主机。基于虚拟主机配置域名需要建立/data/www /data/bbs目录,windows本地hosts添加虚拟机ip地址对应的域名解析;对应域名网站目录下新增index.html文件;# 当客户端访问www.lijie.com,监听端口号为80,直接跳转到data/www目录下文件 server { listen 80; server_name www.lijie.com; location / { root data/www; index index.html index.htm; } } # 当客户端访问www.lijie.com,监听端口号为80,直接跳转到data/bbs目录下文件 server { listen 80; server_name bbs.lijie.com; location / { root data/bbs; index index.html index.htm; } } 基于端口的虚拟主机使用端口来区分,浏览器使用域名或ip地址:端口号 访问# 当客户端访问www.lijie.com,监听端口号为8080,直接跳转到data/www目录下文件 server { listen 8080; server_name 8080.lijie.com; location / { root data/www; index index.html index.htm; } } # 当客户端访问www.lijie.com,监听端口号为80直接跳转到真实ip服务器地址 127.0.0.1:8080 server { listen 80; server_name www.lijie.com; location / { proxy_pass http://127.0.0.1:8080; index index.html index.htm; } } location的作用是什么?location指令的作用是根据用户请求的URI来执行不同的应用,也就是根据用户请求的网站URL进行匹配,匹配成功即进行相关的操作。location的语法能说出来吗?❝注意:~ 代表自己输入的英文字母❞Location正则案例# 优先级1,精确匹配,根路径 location =/ { return 400; } # 优先级2,以某个字符串开头,以av开头的,优先匹配这里,区分大小写 location ^~ /av { root /data/av/; } # 优先级3,区分大小写的正则匹配,匹配/media*****路径 location ~ /media { alias /data/static/; } # 优先级4,不区分大小写的正则匹配,所有的****.jpg|gif|png 都走这里 location ~* .*\.(jpg|gif|png|js|css)$ { root /data/av/; } # 优先级5,通用匹配 location / { return 403; } 限流怎么做的?Nginx限流就是限制用户请求速度,防止服务器受不了限流有3种正常限制访问频率(正常流量)突发限制访问频率(突发流量)限制并发连接数Nginx的限流都是基于漏桶流算法❝实现三种限流算法❞1、正常限制访问频率(正常流量):限制一个用户发送的请求,我Nginx多久接收一个请求。Nginx中使用ngx_http_limit_req_module模块来限制的访问频率,限制的原理实质是基于漏桶算法原理来实现的。在nginx.conf配置文件中可以使用limit_req_zone命令及limit_req命令限制单个IP的请求处理频率。# 定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m; # 绑定限流维度 server{ location/seckill.html{ limit_req zone=zone; proxy_pass http://lj_seckill; } } 1r/s代表1秒一个请求,1r/m一分钟接收一个请求, 如果Nginx这时还有别人的请求没有处理完,Nginx就会拒绝处理该用户请求。2、突发限制访问频率(突发流量):限制一个用户发送的请求,我Nginx多久接收一个。上面的配置一定程度可以限制访问频率,但是也存在着一个问题:如果突发流量超出请求被拒绝处理,无法处理活动时候的突发流量,这时候应该如何进一步处理呢?Nginx提供burst参数结合nodelay参数可以解决流量突发的问题,可以设置能处理的超过设置的请求数外能额外处理的请求数。我们可以将之前的例子添加burst参数以及nodelay参数:# 定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m; # 绑定限流维度 server{ location /seckill.html{ limit_req zone=zone burst=5 nodelay; proxy_pass http://lj_seckill; } } 为什么就多了一个 burst=5 nodelay; 呢,多了这个可以代表Nginx对于一个用户的请求会立即处理前五个,多余的就慢慢来落,没有其他用户的请求我就处理你的,有其他的请求的话我Nginx就漏掉不接受你的请求3、 限制并发连接数Nginx中的ngx\_http\_limit\_conn\_module模块提供了限制并发连接数的功能,可以使用limit\_conn\_zone指令以及limit_conn执行进行配置。接下来我们可以通过一个简单的例子来看下:http { limit_conn_zone $binary_remote_addr zone=myip:10m; limit_conn_zone $server_name zone=myServerName:10m; } server { location / { limit_conn myip 10; limit_conn myServerName 100; rewrite / http://www.lijie.net permanent; } } 上面配置了单个IP同时并发连接数最多只能10个连接,并且设置了整个虚拟服务器同时最大并发数最多只能100个链接。当然,只有当请求的header被服务器处理后,虚拟服务器的连接数才会计数。刚才有提到过Nginx是基于漏桶算法原理实现的,实际上限流一般都是基于漏桶算法和令牌桶算法实现的。漏桶流算法和令牌桶算法知道?漏桶算法漏桶算法思路很简单,我们把水比作是请求,漏桶比作是系统处理能力极限,水先进入到漏桶里,漏桶里的水按一定速率流出,当流出的速率小于流入的速率时,由于漏桶容量有限,后续进入的水直接溢出(拒绝请求),以此实现限流。漏桶算法令牌桶算法令牌桶算法的原理也比较简单,我们可以理解成医院的挂号看病,只有拿到号以后才可以进行诊病。系统会维护一个令牌(token)桶,以一个恒定的速度往桶里放入令牌(token),这时如果有请求进来想要被处理,则需要先从桶里获取一个令牌(token),当桶里没有令牌(token)可取时,则该请求将被拒绝服务。令牌桶算法通过控制桶的容量、发放令牌的速率,来达到对请求的限制。Nginx配置高可用性怎么配置?当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮训到下一台服务器,保证服务器的高可用Nginx配置代码:server { listen 80; server_name www.lijie.com; location / { ### 指定上游服务器负载均衡服务器 proxy_pass http://backServer; ###nginx与上游服务器(真实访问的服务器)超时时间 后端服务器连接的超时时间_发起握手等候响应超时时间 proxy_connect_timeout 1s; ###nginx发送给上游服务器(真实访问的服务器)超时时间 proxy_send_timeout 1s; ### nginx接受上游服务器(真实访问的服务器)超时时间 proxy_read_timeout 1s; index index.html index.htm; } } Nginx怎么判断别IP不可访问?# 如果访问的ip地址为192.168.9.115,则返回403 if ($remote_addr = 192.168.9.115) { return 403; } 在nginx中,如何使用未定义的服务器名称来阻止处理请求?只需将请求删除的服务器就可以定义为:服务器名被保留一个空字符串,他在没有主机头字段的情况下匹配请求,而一个特殊的nginx的非标准代码被返回,从而终止连接。怎么限制浏览器访问?## 不允许谷歌浏览器访问 如果是谷歌浏览器返回500 if ($http_user_agent ~ Chrome) { return 500; } Rewrite全局变量是什么?$remote_addr //获取客户端ip $binary_remote_addr //客户端ip(二进制) $remote_port //客户端port,如:50472 $remote_user //已经经过Auth Basic Module验证的用户名 $host //请求主机头字段,否则为服务器名称,如:blog.sakmon.com $request //用户请求信息,如:GET ?a=1&b=2 HTTP/1.1 $request_filename //当前请求的文件的路径名,由root或alias和URI request组合而成,如:/2013/81.html $status //请求的响应状态码,如:200 $body_bytes_sent // 响应时送出的body字节数数量。即使连接中断,这个数据也是精确的,如:40 $content_length // 等于请求行的“Content_Length”的值 $content_type // 等于请求行的“Content_Type”的值 $http_referer // 引用地址 $http_user_agent // 客户端agent信息,如:Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.76 Safari/537.36 $args //与$query_string相同 等于当中URL的参数(GET),如a=1&b=2 $document_uri //与$uri相同 这个变量指当前的请求URI,不包括任何参数(见$args) 如:/2013/81.html $document_root //针对当前请求的根路径设置值 $hostname //如:centos53.localdomain $http_cookie //客户端cookie信息 $cookie_COOKIE //cookie COOKIE变量的值 $is_args //如果有$args参数,这个变量等于”?”,否则等于”",空值,如? $limit_rate //这个变量可以限制连接速率,0表示不限速 $query_string // 与$args相同 等于当中URL的参数(GET),如a=1&b=2 $request_body // 记录POST过来的数据信息 $request_body_file //客户端请求主体信息的临时文件名 $request_method //客户端请求的动作,通常为GET或POST,如:GET $request_uri //包含请求参数的原始URI,不包含主机名,如:/2013/81.html?a=1&b=2 $scheme //HTTP方法(如http,https),如:http $uri //这个变量指当前的请求URI,不包括任何参数(见$args) 如:/2013/81.html $request_completion //如果请求结束,设置为OK. 当请求未结束或如果该请求不是请求链串的最后一个时,为空(Empty),如:OK $server_protocol //请求使用的协议,通常是HTTP/1.0或HTTP/1.1,如:HTTP/1.1 $server_addr //服务器IP地址,在完成一次系统调用后可以确定这个值 $server_name //服务器名称,如:blog.sakmon.com $server_port //请求到达服务器的端口号,如:80 Nginx 如何实现后端服务的健康检查?方式一 利用 nginx 自带模块 ngx\_http\_proxy\_module 和 ngx\_http\_upstream\_module 对后端节点做健康检查。方式二(推荐) 利用 nginx\_upstream\_check_module 模块对后端节点做健康检查。Nginx 如何开启压缩?开启nginx gzip压缩后,网页、css、js等静态资源的大小会大大的减少,从而可以节约大量的带宽,提高传输效率,给用户快的体验。虽然会消耗cpu资源,但是为了给用户更好的体验是值得的。开启的配置如下:http { # 开启gzip gzip on; # 启用gzip压缩的最小文件;小于设置值的文件将不会被压缩 gzip_min_length 1k; # gzip 压缩级别 1-10 gzip_comp_level 2; # 进行压缩的文件类型。 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; # 是否在http header中添加Vary: Accept-Encoding,建议开启 gzip_vary on; } 保存并重启nginx,刷新页面(为了避免缓存,请强制刷新)就能看到效果了。以谷歌浏览器为例,通过F12看请求的响应头部:我们可以先来对比下,如果我们没有开启zip压缩之前,我们的对应的文件大小,如下所示:现在我们开启了gzip进行压缩后的文件的大小,可以看到如下所示:并且我们查看响应头会看到gzip这样的压缩。gzip压缩前后效果对比:jquery原大小90kb,压缩后只有30kb。gzip虽然好用,但是以下类型的资源不建议启用。1、图片类型原因:图片如jpg、png本身就会有压缩,所以就算开启gzip后,压缩前和压缩后大小没有多大区别,所以开启了反而会白白的浪费资源。(Tips:可以试试将一张jpg图片压缩为zip,观察大小并没有多大的变化。虽然zip和gzip算法不一样,但是可以看出压缩图片的价值并不大)2、大文件原因:会消耗大量的cpu资源,且不一定有明显的效果。ngx_http_upstream_module的作用是什么?ngx_http_upstream_module用于定义可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组。什么是C10K问题?C10K问题是指无法同时处理大量客户端(10,000)的网络套接字。Nginx是否支持将请求压缩到上游?您可以使用Nginx模块gunzip将请求压缩到上游。gunzip模块是一个过滤器,它可以对不支持“gzip”编码方法的客户机或服务器使用“内容编码:gzip”来解压缩响应。微信搜索公众号:信安黑客技术,回复:黑客 领取资料 。如何在Nginx中获得当前的时间?要获得Nginx的当前时间,必须使用SSI模块、和date_local的变量。Proxy_set_header THE-TIME $date_gmt; 用Nginx服务器解释-s的目的是什么?用于运行Nginx -s参数的可执行文件。如何在Nginx服务器上添加模块?在编译过程中,必须选择Nginx模块,因为Nginx不支持模块的运行时间选择。生产中如何设置worker进程的数量呢?在有多个cpu的情况下,可以设置多个worker,worker进程的数量可以设置到和cpu的核心数一样多,如果在单个cpu上起多个worker进程,那么操作系统会在多个worker之间进行调度,这种情况会降低系统性能,如果只有一个cpu,那么只启动一个worker进程就可以了。nginx状态码499:服务端处理时间过长,客户端主动关闭了连接。502:502 状态码的可能情况就比较多了。FastCGI 进程是否已经启动FastCGI worker进程数是否不够FastCGI 执行时间过长fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; FastCGI Buffer不够,nginx和apache一样,有前端缓冲限制,可以调整缓冲参数fastcgi_buffer_size 32k; fastcgi_buffers 8 32k; Proxy Buffer不够,如果你用了Proxying,调整proxy_buffer_size 16k; proxy_buffers 4 16k;php脚本执行时间过长将php-fpm.conf的0s的0s改成一个时间
-
经常用得上的Linux Shell 脚本! nginx日志按天切割#!/bin/bash LOG_DIR=/usr/local/nginx/logsYESTERDAY_TIME=$(date -d "yesterday" +%F) LOG_MONTH_DIR=$LOG_DIR/$(date +"%Y-%m") LOG_FILE_LIST="default.access.log" for LOG_FILE in $LOG_FILE_LIST; do [ ! -d $LOG_MONTH_DIR ] && mkdir -p $LOG_MONTH_DIR mv $LOG_DIR/$LOG_FILE $LOG_MONTH_DIR/${LOG_FILE}_${YESTERDAY_TIME} done kill -USR1 $(cat /usr/local/nginx/nginx.pid)nginx acc日志分析#!/bin/bash # 日志格式: $remote_addr - $remote_user [$time_local] " $request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for" LOG_FILE=$1echo "统计访问最多的10个IP" awk '{a[$1]++}END{print "UV:",length(a);for(v in a)print v,a[v]}' $LOG_FILE | sort -k2 -nr | head -10 echo "----------------------" echo "统计时间段访问最多的IP" awk '$4>="[01/Dec/2018:13:20:25" && $4<="[27/Nov/2018:16:20:49"{a[$1]++}END{for(v in a)print v,a[v]}' $LOG_FILE | sort -k2 -nr|head -10 echo "----------------------" echo "统计访问最多的10个页面" awk '{a[$7]++}END{print "PV:",length(a);for(v in a){if(a[v]>10)print v,a[v]}}' $LOG_FILE | sort -k2 -nr echo "----------------------" echo "统计访问页面状态码数量" awk '{a[$7" "$9]++}END{for(v in a){if(a[v]>5) print v,a[v]}}'服务器初始化#/bin/bash # 设置时区并同步时间 ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtimeif ! crontab -l | grep ntpdate &>/dev/null ; then (echo "* 1 * * * ntpdate time.windows.com >/dev/null 2>&1";crontab -l) |crontabfi # 禁用selinux sed -i '/SELINUX/{s/permissive/disabled/}' /etc/selinux/config # 关闭防火墙 if egrep "7.[0-9]" /etc/redhat-release &>/dev/null; then systemctl stop firewalld systemctl disable firewalldelif egrep "6.[0-9]" /etc/redhat-release &>/dev/null; then service iptables stop chkconfig iptables off fi # 历史命令显示操作时间 if ! grep HISTTIMEFORMAT /etc/bashrc; then echo 'export HISTTIMEFORMAT="%F %T `whoami` "' >> /etc/bashrc fi # SSH超时时间 if ! grep "TMOUT=600" /etc/profile &>/dev/null; then echo "export TMOUT=600" >> /etc/profile fi # 禁止root远程登录 sed -i 's/#PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config # 禁止定时任务向发送邮件 sed -i 's/^MAILTO=root/MAILTO=""/' /etc/crontab # 设置最大打开文件数 if ! grep "* soft nofile 65535" /etc/security/limits.conf &>/dev/null; then cat >> /etc/security/limits.conf << EOF * soft nofile 65535 * hard nofile 65535EOF fi # 系统内核优化 cat >> /etc/sysctl.conf << EOFnet.ipv4.tcp_syncookies = 1net.ipv4.tcp_max_tw_buckets = 20480 net.ipv4.tcp_max_syn_backlog = 20480 net.core.netdev_max_backlog = 262144 net.ipv4.tcp_fin_timeout = 20 EOF # 减少SWAP使用 echo "0" > /proc/sys/vm/swappiness # 安装系统性能分析工具及其他 yum install gcc make autoconf vim sysstat net-tools iostat if查看网卡实时流量#!/bin/bash NIC=$1echo -e " In ------ Out"while true; do OLD_IN=$(awk '$0~"'$NIC'"{print $2}' /proc/net/dev) OLD_OUT=$(awk '$0~"'$NIC'"{print $10}' /proc/net/dev) sleep 1 NEW_IN=$(awk '$0~"'$NIC'"{print $2}' /proc/net/dev) NEW_OUT=$(awk '$0~"'$NIC'"{print $10}' /proc/net/dev) IN=$(printf "%.1f%s" "$((($NEW_IN-$OLD_IN)/1024))" "KB/s") OUT=$(printf "%.1f%s" "$((($NEW_OUT-$OLD_OUT)/1024))" "KB/s") echo "$IN $OUT" sleep 1 donemysql 备份#!/bin/bash DATE=$(date +%F_%H-%M-%S) HOST=localhost USER=backup PASS=passwd BACKUP_DIR=/data/db_backup DB_LIST=$(mysql -h$HOST -u$USER -p$PASS -s -e "show databases;" 2>/dev/null |egrep -v "Database|information_schema|mysql|performance_schema|sys") for DB in $DB_LIST; do BACKUP_DB_DIR=$BACKUP_DIR/${DB}_${DATE} [ ! -d $BACKUP_DB_DIR ] && mkdir -p $BACKUP_DB_DIR &>/dev/null TABLE_LIST=$(mysql -h$HOST -u$USER -p$PASS -s -e "use $DB;show tables;" 2>/dev/null) for TABLE in $TABLE_LIST; do BACKUP_NAME=$BACKUP_DB_DIR/${TABLE}.sql if ! mysqldump -h$HOST -u$USER -p$PASS $DB $TABLE > $BACKUP_NAME 2>/dev/null; then echo "$BACKUP_NAME 备份失败!" fi done done监控服务器磁盘利用率#!/bin/bash HOST_INFO=host.info # 主机列表,实现采集多台主机信息,需要能够ssh到目标主机 for IP in $(awk '/^[^#]/{print $1}' $HOST_INFO); do USER=$(awk -v ip=$IP 'ip==$1{print $2}' $HOST_INFO) PORT=$(awk -v ip=$IP 'ip==$1{print $3}' $HOST_INFO) TMP_FILE=/tmp/disk.tmp ssh -p $PORT $USER@$IP 'df -h' > $TMP_FILE USE_RATE_LIST=$(awk 'BEGIN{OFS="="}/^\/dev/{print $NF,int($5)}' $TMP_FILE) for USE_RATE in $USE_RATE_LIST; do PART_NAME=${USE_RATE%=*} USE_RATE=${USE_RATE#*=} if [ $USE_RATE -ge 80 ]; then echo "Warning: $PART_NAME Partition usage $USE_RATE%!" fi done done封禁大量恶意访问的IP#!/bin/bash DATE=$(date +%d/%b/%Y:%H:%M) LOG_FILE=/usr/local/nginx/logs/access.log ABNORMAL_IP=$(tail -n10000 $LOG_FILE |grep $DATE |awk '{a[$1]++}END{for(i in a)if(a[i]>10)print i}')for IP in $ABNORMAL_IP; do if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then iptables -I INPUT -s $IP -j DROP echo "$(date +'%F_%T') $IP" >> /tmp/drop_ip.log fi done统计进程数,找出并kill 僵尸进程#!/bin/ bash ALL_PROCESS=$(1s /proc/ l egrep "[0-9]+") running_count=0 stoped_count=0 s1eeping_count=0 zombie_count=O for pid in ${ALL_PROCESS[*]}dotest -f /proc/$pid/status && state=$(egrep "state"/proc/$pid/status / awk'{print $2}')case ""$state" inR)running_count=$ ((running_count+1));T)stoped_count=$((stoped_count+1));;s)sleeping_count=$((sleeping_count+1));z)zombie_count=$( (zombie_count+1)) echo "$pid" >>zombie.txtkill -9 "$pid";;esacdoneecho -e "total:$((running_count+stoped_count+sleeping_count+zombie_count))\nrunning:$running_count\nstoped: $stoped_count\nsleeping: $sleeping_count\nzombie:$zombie_count"