搜索到
266
篇与
的结果
-
 Debian10 配置镜像源(外网、内网) 一.备份默认源由于默认源都在国外,速度非常慢,需要把默认的源配置文件备份后删除。# 进入配置文件目录 cd /etc/apt # 复制配置文件 cp sources.list sources.list.bak二、配置外网源(阿里)nano /etc/apt/sources.list配置文件内容:deb http://mirrors.aliyun.com/debian/ buster main non-free contrib deb http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib deb http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib deb http://mirrors.aliyun.com/debian-security/ buster/updates main non-free contrib deb-src http://mirrors.aliyun.com/debian-security/ buster/updates main non-free contrib清理缓存|更新仓库文件列表# 清除缓存 apt clean # 更新列表 apt update三、配置本地源(内网环境)在非联网环境可以通过安装包光盘配置本地源。# 创建挂载目录 mkdir /mnt/debian-cd # 挂载光盘 mount /dev/cdrom /mnt/debian-cd # 验证是否挂载成功 ls -l /mnt/debian-cd # 添加光盘镜像源 apt-cdrom add # 清除缓存 apt clean # 更新列表 apt update
Debian10 配置镜像源(外网、内网) 一.备份默认源由于默认源都在国外,速度非常慢,需要把默认的源配置文件备份后删除。# 进入配置文件目录 cd /etc/apt # 复制配置文件 cp sources.list sources.list.bak二、配置外网源(阿里)nano /etc/apt/sources.list配置文件内容:deb http://mirrors.aliyun.com/debian/ buster main non-free contrib deb http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib deb http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib deb-src http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib deb http://mirrors.aliyun.com/debian-security/ buster/updates main non-free contrib deb-src http://mirrors.aliyun.com/debian-security/ buster/updates main non-free contrib清理缓存|更新仓库文件列表# 清除缓存 apt clean # 更新列表 apt update三、配置本地源(内网环境)在非联网环境可以通过安装包光盘配置本地源。# 创建挂载目录 mkdir /mnt/debian-cd # 挂载光盘 mount /dev/cdrom /mnt/debian-cd # 验证是否挂载成功 ls -l /mnt/debian-cd # 添加光盘镜像源 apt-cdrom add # 清除缓存 apt clean # 更新列表 apt update -
Docker 安装 Nginx Proxy Manager 1.背景对于想自己搭建网站的朋友,使用自己个性化域名的朋友,使用Nginx的不在少数,可能也会使用Apache来管理自己的网站,但Nginx轻量又好用,还支持正向/反向代理,谁不喜欢呢?Nginx Proxy Manager就是一款让你能通过网页的一些设置,完成网站的代理配置,无需自己再手动安装Nginx修改配置文件了,大大提高了效率。项目也是开源的,不用担心项目的安全性。2.安装docker安装依然使用我们的老伙计 docker ,但这次要使用到 docker 的伙计: docker-compose,使用 docker-compose 可以帮助我们编排自己的容器,通过一个简单的脚本启动复杂的程序,自动处理依赖项目,从而简化操作。服务器上执行以下命令安装 docker, 安装完成后执行第二条命令,启动并设置开机启动 docker。curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun systemctl enable --now docker安装docker-composesudo curl -L "https://github.com/docker/compose/releases/download/v2.1.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose检查一下安装是否成功# 查看docker版本 docker -v # 查看docker-compose版本 docker-compose -v如果未能查看 docker-compose 版本可能是因为 /usr/local/bin 没有加入到系统环境变量export PATH=/usr/local/bin:$PATH3.部署Nginx Proxy Manager创建一个目录用于存放 Nginx Proxy Manager 的配置和项目文件mkdir -p /opt/docker/NginxProxyManager && cd /opt/docker/NginxProxyManager创建一个 docker-compose.yml 文件vi docker-compose.yml粘贴以下内容:version: '3' services: app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: - '80:80' - '81:81' - '443:443' volumes: - ./data:/data - ./letsencrypt:/etc/letsencrypt按下键盘上的 ESC 键和 SHIFT+: 键,输入 wq 保存退出。请注意文件间的缩进,如果缩进不正确,可以使用文本编辑器编辑好后上传到服务器上。创建 docker 容器docker-compose up -d4.访问控制页面浏览器输入你的ip:81,如果有防火墙,可以临时开放 81 的 tcp 端口。初始的用户和密码如下:Email: admin@example.com Password: changeme
-
彻底解决Ubuntu SSH 无法远程登录及root 登录ACCESS Denied 问题 采用VM虚拟机安装了Ubuntu 16.04 ,采用SSH远程连接发现了两个问题(与Centos不一样)。第一,是SSH无法连接上刚建立的虚拟服务器。原因是Ubuntu没有默认安装SSH服务,需要手动安装下。1、 sudo ps -e|grep ssh #查看是否安装了SSH服务(如果显示为空则没安装)2、sudo apt-get update #先更新下资源列表3、sudo apt-get install openssh-server #安装openssh-server4、sudo ps -e|grep ssh #查看是否安装成功5、sudo service sshd start #重新启动SSH服务第二,root 登录ACCESS Denied 问题第一问题解决后,发现远程SSH连接root 登录缓慢并出现如下问题:解决办法如下:sudo vi /etc/ssh/sshd_config把 PermitRootLogin prohibit-password 注释掉增加一行 PermitRootLogin yes 如下图:重启systemctl restart sshd重新登录 SSH 远程用 root 就解决了 ok!
-
ubuntu 使用root用户登录系统 Ubuntu20.04 安装完成之后,默认是没有 root 账户登录权限的,不过我们可以通过创建的普通用户获取管理员权限,然后修改配置和 root 账户的密码,最后实现登录 root 账户,具体操作步骤如下:1. 以普通用户登录系统,创建 root 用户的密码在终端输入命令:sudo passwd root先输入当前管理用户(如用户 coco )的密码,用于提权。然后再输入为 root 用户所设置的密码,输入两次,这样就完成设置 root 用户密码了(注意 Linux 系统下密码是没有回显的)2. 修改50-ubuntu.conf文件在终端输入命令:sudo vim /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf在文件末尾增加如下两行并保存:greeter-show-manual-login=true #手工输入登陆系统的用户名和密码 allow-guest=false #不允许guest登录(可选)3. 修改gdm-autologin文件在终端输入命令:sudo vim /etc/pam.d/gdm-autologin在第三行前面加#以注释掉auth required pam_succeed_if.so user != root quiet_success,随后保存并退出4. 修改gdm-password文件在终端输入命令:sudo vim /etc/pam.d/gdm-password在第三行前面加#以注释掉auth required pam_succeed_if.so user != root quiet_success,随后保存并退出5. 修改/root/.profile文件在终端输入命令:sudo vim /root/.profile将文件末尾的mesg n 2> /dev/null || true这一行注释掉,并随后添加:tty -s&&mesg n || true6. 注销当前用户,登录 root 用户一般修改完配置后最好重启一下reboot点击未列出?输入 root 然后按回车键登录系统
-
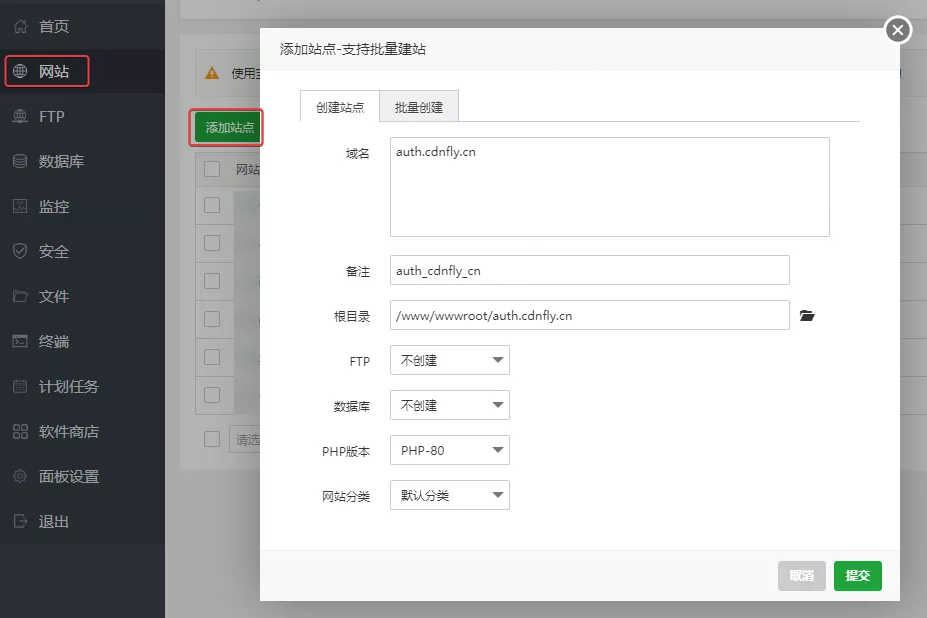
Cdnfly 通过修改 hosts 破解授权保姆级教程 Cdnfly 官方文档:http://doc.cdnfly.cn/1790334Cdnfly 是基于 Openresty ,以 lua 脚本语言开发的防 CC 攻击软件。而 Openresty 是集成了高性能 Web 服务器 Nginx ,以及一系列的 Nginx 模块,这其中最重要的,也是我们主要用到的 Nginx lua 模块。Cdnfly 基于 Nginx lua 开发,继承了 nginx 高并发,高性能的特点,可以以非常小的性能损耗来防范大规模的 CC 攻击主控端目前仅支持 Centos-7 和 Ubuntu 1604 系统。因本次教程用到两台服务器演示,故未测试在同一台服务器配置网站及主控端安装。网站搭建A 服务器在宝塔面板新建网站,绑定域名:auth.cdnfly.cn 和 monitor.cdnfly.cn 。设置网站伪静态。location / { if (!-e $request_filename) { rewrite ^(.*)$ /index.php/$1 last; break; } } 上传本文附件内压缩包至网站根目录解压。下载地址:https://115.com/s/sw6rlch3hlg?password=g507&#Cdnfly-v5.1.11.zip访问码:g507主控端安装B 服务器在宝塔面板 /etc 目录下编辑 host 文件。设置 auth.cdnfly.cn 指向刚才配置网站的服务器 IP 。设置完可通过 ping 命令验证。*.*.*.* auth.cdnfly.cn 通过 Xshell 或其他 SSH 工具执行以下命令安装主控:curl http://auth.cdnfly.cn/master.sh -o master.sh && chmod +x master.sh && ./master.sh --es-dir /home/es 安装完成访问主控端 IP 即可访问后台。修改授权节点数量及到期时间。节点安装命令在后台 系统管理 - 系统升级 。错误提示如提示:Job forlma riadb . service failed because the control process exited with error code.See "systemctl status mariadb . servic and "journalctl -xe" for details. 不如重装下系统吧。变更日志2022-7-14 更新修复节点监控功能
-
Spring Boot + Redis 解决重复提交问题,一定用的到 前言在实际的开发项目中,一个对外暴露的接口往往会面临很多次请求,我们来解释一下幂等的概念:任意多次执行所产生的影响均与一次执行的影响相同。按照这个含义,最终的含义就是 对数据库的影响只能是一次性的,不能重复处理。如何保证其幂等性,通常有以下手段:数据库建立唯一性索引,可以保证最终插入数据库的只有一条数据token机制,每次接口请求前先获取一个token,然后再下次请求的时候在请求的header体中加上这个token,后台进行验证,如果验证通过删除token,下次请求再次判断token悲观锁或者乐观锁,悲观锁可以保证每次for update的时候其他sql无法update数据(在数据库引擎是innodb的时候,select的条件必须是唯一索引,防止锁全表)先查询后判断,首先通过查询数据库是否存在数据,如果存在证明已经请求过了,直接拒绝该请求,如果没有存在,就证明是第一次进来,直接放行。Redis实现自动幂等的原理图:搭建Redis的服务Api1、首先是搭建 Redis 服务器。2、引入 springboot 中到的 redis 的 stater ,或者 Spring 封装的 jedis 也可以,后面主要用到的 api 就是它的 set 方法和 exists 方法,这里我们使用 springboot 的封装好的 redisTemplate/** * redis工具类 */ @Component public class RedisService { @Autowired private RedisTemplate redisTemplate; /** * 写入缓存 * @param key * @param value * @return */ public boolean set(final String key, Object value) { boolean result = false; try { ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue(); operations.set(key, value); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 写入缓存设置时效时间 * @param key * @param value * @return */ public boolean setEx(final String key, Object value, Long expireTime) { boolean result = false; try { ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue(); operations.set(key, value); redisTemplate.expire(key, expireTime, TimeUnit.SECONDS); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 判断缓存中是否有对应的value * @param key * @return */ public boolean exists(final String key) { return redisTemplate.hasKey(key); } /** * 读取缓存 * @param key * @return */ public Object get(final String key) { Object result = null; ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue(); result = operations.get(key); return result; } /** * 删除对应的value * @param key */ public boolean remove(final String key) { if (exists(key)) { Boolean delete = redisTemplate.delete(key); return delete; } return false; } }自定义注解AutoIdempotent自定义一个注解,定义此注解的主要目的是把它添加在需要实现幂等的方法上,凡是某个方法注解了它,都会实现自动幂等。后台利用反射如果扫描到这个注解,就会处理这个方法实现自动幂等,使用元注解 ElementType.METHOD 表示它只能放在方法上, etentionPolicy.RUNTIME 表示它在运行时@Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface AutoIdempotent { }Token创建和检验1、Token服务接口 我们新建一个接口,创建 token 服务,里面主要是两个方法,一个用来创建 token ,一个用来验证 token 。创建 token 主要产生的是一个字符串,检验 token 的话主要是传达 request 对象,为什么要传 request 对象呢?主要作用就是获取 header 里面的 token ,然后检验,通过抛出的 Exception 来获取具体的报错信息返回给前端public interface TokenService { /** * 创建token * @return */ public String createToken(); /** * 检验token * @param request * @return */ public boolean checkToken(HttpServletRequest request) throws Exception; }2、Token的服务实现类 token 引用了 redis 服务,创建 token 采用随机算法工具类生成随机 uuid 字符串,然后放入到 redis 中(为了防止数据的冗余保留,这里设置过期时间为10000秒,具体可视业务而定),如果放入成功,最后返回这个 token 值。 checkToken 方法就是从 header 中获取 token 到值(如果 header 中拿不到,就从 paramter 中获取),如若不存在,直接抛出异常。这个异常信息可以被拦截器捕捉到,然后返回给前端。@Service public class TokenServiceImpl implements TokenService { @Autowired private RedisService redisService; /** * 创建token * * @return */ @Override public String createToken() { String str = RandomUtil.randomUUID(); StrBuilder token = new StrBuilder(); try { token.append(Constant.Redis.TOKEN_PREFIX).append(str); redisService.setEx(token.toString(), token.toString(),10000L); boolean notEmpty = StrUtil.isNotEmpty(token.toString()); if (notEmpty) { return token.toString(); } }catch (Exception ex){ ex.printStackTrace(); } return null; } /** * 检验token * * @param request * @return */ @Override public boolean checkToken(HttpServletRequest request) throws Exception { String token = request.getHeader(Constant.TOKEN_NAME); if (StrUtil.isBlank(token)) {// header中不存在token token = request.getParameter(Constant.TOKEN_NAME); if (StrUtil.isBlank(token)) {// parameter中也不存在token throw new ServiceException(Constant.ResponseCode.ILLEGAL_ARGUMENT, 100); } } if (!redisService.exists(token)) { throw new ServiceException(Constant.ResponseCode.REPETITIVE_OPERATION, 200); } boolean remove = redisService.remove(token); if (!remove) { throw new ServiceException(Constant.ResponseCode.REPETITIVE_OPERATION, 200); } return true; } }拦截器的配置1、Web配置类 实现WebMvcConfigurerAdapter,主要作用就是添加autoIdempotentInterceptor到配置类中,这样我们到拦截器才能生效,注意使用@Configuration注解,这样在容器启动是时候就可以添加进入context中@Configuration public class WebConfiguration extends WebMvcConfigurerAdapter { @Resource private AutoIdempotentInterceptor autoIdempotentInterceptor; /** * 添加拦截器 * @param registry */ @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(autoIdempotentInterceptor); super.addInterceptors(registry); } }2、拦截处理器 主要的功能是拦截扫描到 AutoIdempotent 到注解到方法,然后调用 tokenService 的 checkToken() 方法校验token是否正确,如果捕捉到异常就将异常信息渲染成json返回给前端/** * 拦截器 */ @Component public class AutoIdempotentInterceptor implements HandlerInterceptor { @Autowired private TokenService tokenService; /** * 预处理 * * @param request * @param response * @param handler * @return * @throws Exception */ @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { if (!(handler instanceof HandlerMethod)) { return true; } HandlerMethod handlerMethod = (HandlerMethod) handler; Method method = handlerMethod.getMethod(); //被ApiIdempotment标记的扫描 AutoIdempotent methodAnnotation = method.getAnnotation(AutoIdempotent.class); if (methodAnnotation != null) { try { return tokenService.checkToken(request);// 幂等性校验, 校验通过则放行, 校验失败则抛出异常, 并通过统一异常处理返回友好提示 }catch (Exception ex){ ResultVo failedResult = ResultVo.getFailedResult(101, ex.getMessage()); writeReturnJson(response, JSONUtil.toJsonStr(failedResult)); throw ex; } } //必须返回true,否则会被拦截一切请求 return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { } /** * 返回的json值 * @param response * @param json * @throws Exception */ private void writeReturnJson(HttpServletResponse response, String json) throws Exception{ PrintWriter writer = null; response.setCharacterEncoding("UTF-8"); response.setContentType("text/html; charset=utf-8"); try { writer = response.getWriter(); writer.print(json); } catch (IOException e) { } finally { if (writer != null) writer.close(); } } }测试用例1、模拟业务请求类 首先我们需要通过 /get/token 路径通过 getToken() 方法去获取具体的 token ,然后我们调用 testIdempotence 方法,这个方法上面注解了 @AutoIdempotent ,拦截器会拦截所有的请求,当判断到处理的方法上面有该注解的时候,就会调用 TokenService 中的 checkToken() 方法,如果捕获到异常会将异常抛出调用者,下面我们来模拟请求一下:@RestController public class BusinessController { @Resource private TokenService tokenService; @Resource private TestService testService; @PostMapping("/get/token") public String getToken(){ String token = tokenService.createToken(); if (StrUtil.isNotEmpty(token)) { ResultVo resultVo = new ResultVo(); resultVo.setCode(Constant.code_success); resultVo.setMessage(Constant.SUCCESS); resultVo.setData(token); return JSONUtil.toJsonStr(resultVo); } return StrUtil.EMPTY; } @AutoIdempotent @PostMapping("/test/Idempotence") public String testIdempotence() { String businessResult = testService.testIdempotence(); if (StrUtil.isNotEmpty(businessResult)) { ResultVo successResult = ResultVo.getSuccessResult(businessResult); return JSONUtil.toJsonStr(successResult); } return StrUtil.EMPTY; } }2、使用postman请求 首先访问get/token路径获取到具体到token:利用获取到到token,然后放到具体请求到header中,可以看到第一次请求成功,接着我们请求第二次:第二次请求,返回到是重复性操作,可见重复性验证通过,再多次请求到时候我们只让其第一次成功,第二次就是失败:总结本文介绍了使用 springboot 和 拦截器 、 redis 来优雅的实现接口幂等,对于幂等在实际的开发过程中是十分重要的,因为一个接口可能会被无数的客户端调用,如何保证其不影响后台的业务处理,如何保证其只影响数据一次是非常重要的,它可以防止产生脏数据或者乱数据,也可以减少并发量,实乃十分有益的一件事。而传统的做法是每次判断数据,这种做法不够智能化和自动化,比较麻烦。而今天的这种自动化处理也可以提升程序的伸缩性。
-
计算机网络期末复习提纲(全知识点总结) 计算机网络期末复习提纲全知识点总结第一章 概述1.基本概念- 链路,结点,协议和服务,实体和对等实体,各层PDU- C/S模式,B/S模式,P2P模式- LAN,WAN,MAN,PAN的划分- 网络性能参数:速率,带宽,吞吐量,时延,往返时间,信道利用率2.互联网的组成(边缘部分与核心部分的作用)3.电路交换与分组交换,数据报交换和虚电路交换的特点4.TCP/IP体系结构,数据的封装与解封装第二章 物理层1.信号编码:不归零编码,曼切斯特编码2.影响信号失真程度的因素3.传输介质:双绞线,同轴电缆,光纤(单模和多模),无线介质4.几种复用技术的特点:频分复用,时分复用,统计时分复用,波分复用,码分复用5.宽带接入技术:ADSL,HFC,FTTX第三章 数据链路层1.理解数据链路层的地位与作用,三个基本问题2.使用点对点信道的链路层:信道特点,PPP帧格式,零比特填充法和字节填充法,差错检测(CRC)3.使用广播信道的链路层:信道特点,CSMA/CD协议,MAC帧格式,最小帧长和最大帧长4.网卡的功能和MAC地址,帧的类型(单播帧,广播帧,多播帧)5.比较集线器与交换机,交换机的自学习功能及转发帧的过程6.广播域和碰撞域,VLAN,生成树协议STP第四章 网络层1.网络连接设备:中继器,集线器,交换机,路由器的工作层次2.IP地址:分类IP地址;互联网中的IP地址,特殊IP地址(网络地址,广播地址)3.IP地址与硬件地址的关系,ARP协议(ARP原理,ARP缓存,同一局域网使用ARP,跨网使用ARP)4.IP数据报格式:首部长度和总长度,IP分片与重组(标识,标志,片偏移),生存时间TTL,协议,首部检验和5.划分子网:子网划分,子网掩码,根据IP地址和子网掩码计算该IP地址所在网络的网络地址,广播地址,子网数和子网中的主机数6.CIDR(给定一个CIDR地址快,计算最小IP地址,最大IP地址,掩码和地址总数)和路由聚合(给定几个IP地址,计算聚合后的地址)7.ICMP协议:ICMP协议的作用,ICMP差错报文何时产生,由谁产生.PING命令和Tracert命令的工作原理8.路由器:给定拓扑写出路由器(直连路由,静态路由和动态路由,默认路由),路由器根据路由器转发IP数据报的过程9.RIP:距离,距离向量算法,工作过程,特点10.OSPF:链路状态,OSPF的工作过程,OSPF区域11.外部网关协议BGP:寻找可达性的路由,策略路由12.IPv6:ipv6数据报格式,IPv6相比IPv4的变化,IPv6地址的表示,从IPv4相比IPv6的过渡技术13.IP多播:比较(单播,广播,多播,任播),IP多播数据报的封装,多播IP地址与多播MAC地址,IGMP协议的作用14.VPN:私有IP,VPN路由器封装IP数据报的过程,三种VPN类型的判断,NAT路由器封装IP数据报的过程15.MPLS:与传输路由技术的比较,负载均衡与FEC第五章 运输层1.运输层的作用2.UDP和TCP的特点,及使用它们的应用程序,熟知端口号3.UDP:首部格式,检验和4.TCP的首部格式(端口号,序号,确认号,窗口,首部长度,检验和,6个标志位)5.TCP的可靠传输:超时重传机制,TCP流量控制(序号,确认号,确认标志位,窗口,死锁问题与持续计时器),发送缓存和接受缓存的作用,捎带确认与累积确认6.TCP的拥塞控制:网络拥塞的判断,传输轮次与拥塞窗口大小的关系(慢开始与拥塞避免,门限ssthresh,重传计时器超时与三个重复ACK)7.TCP连接:TCP的套接字,三次握手建立TCP连接,四次握手释放TCP连接第六章 应用层1.域名系统DNS1)IP与域名的关系,DNS的作用,域名的结构2)四类域名服务器(根域名服务器,顶级域名服务器,权限域名服务器和本地域名服务器)3)迭代与递归解析域名的方式,DNS缓存2.文件传输协议FTP:FTP协议的作用,控制连接与21号端口,数据连接与20号端口,匿名FTP的三种使用方式3.WWW服务:HTTP协议的作用,URL,在浏览器的地址栏中输入一个URL后发生的报文交互情况,流水线持久连接,HTTP报文,Cookie的作用,三类web文档,搜索引擎4.电子邮件系统:电子邮件系统的组成,E-mail格式,SMTP,MIME,POP3和IMAP的区别,基于万维网的电子邮件5.动态主机配置协议DHCP:DHCP的作用(IP地址,子网掩码,默认网关IP地址,默认DNS服务器IP地址),DHCP的工作过程,IP租约期,DHCP服务器的位置及DHCP中继6. P2P应用:文件分发第七章 网络安全网络攻击的常见方式,对称密码体制和公钥密码体制,数字签名与保密通信,秘钥分配(KDC,CA)第九章 无线局域网两类WLAN,AdHoc,无线传感器网络,CSMA/CA,802.11帧(四个地址)其他1.归纳比较:地址长度(MAC地址,IPv4地址,IPv6地址,端口号)首部长度(帧首部,IPv4首部,IPv6首部)差错检验(帧校验CRC,IPv4,TCP和UDP的校验检验和)路由技术(RIP,OSPF,BGP,MPLS)数据交换(电路交换,报文交换,分组交换)TCP与UDPIPv4与IPv6P2P与C/S搜索引擎(全文检索与分类目录)CSMA/CD与CSMA/CA网络攻击方式(蠕虫,木马,逻辑炸弹,后门入侵,流氓软件,窃听,拒绝服务攻击)2.主要命令Ipconfig命令(/all,/displaydns,/flushdns,/release,/renew)ping命令(-n,-l,-t等参数)Traceroute命令arp命令(-a,-d,-s参数)3.术语:ISP,IXP,Hub,LAN,MAN,WAN,WLAN,VLAN,P2P,C/S,CSMA/CD,CSMA/CA,LiFi,Wifi,ADSL,HFC,FTTH,URL,VPN,IPSec,NAT,ICMP,IGMP,MSS,BGP,自治系统AS,HTTPS,MPLS,AP,SSID,AdHoc,区块链注:粗体为次重点,粗斜体为重点文章详情请访问:计算机网络期末复习提纲(全知识点总结)
-
面试官:从 MySQL 读取 百万 数据进行处理,应该怎么做?问倒一大片! 背景大数据量操作的场景大致如下:数据迁移数据导出批量处理数据在实际工作中当指定查询数据过大时,我们一般使用分页查询的方式一页一页的将数据放到内存处理。但有些情况不需要分页的方式查询数据或分很大一页查询数据时,如果一下子将数据全部加载出来到内存中,很可能会发生 OOM(内存溢出) ;而且查询会很慢,因为框架耗费大量的时间和内存去把数据库查询的结果封装成我们想要的对象(实体类)。举例:在业务系统需要从 MySQL 数据库里读取 100万 数据行进行处理,应该怎么做? 做法通常如下:常规查询:一次性读取 100万 数据到 JVM 内存中,或者分页读取流式查询:建立长连接,利用服务端游标,每次读取一条加载到 JVM 内存(多次获取,一次一行)游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据(多次获取,一次多行)常规查询默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于 MySQL 网络协议的设计,因此更易于实现。举例:假设单表 100万 数据量,一般会采用分页的方式查询:@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); }注:该示例使用的 MybatisPlus。该方式比较简单,如果在不考虑 LIMIT 深分页优化情况下,估计你的数据库服务器就噶皮了,或者你能等上几十分钟或几小时,甚至几天时间检索数据。流式查询流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。如果没有流式查询,我们想要从数据库取 100万 条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。MyBatis 流式查询接口 MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:Cursor 是可关闭的;Cursor 是可遍历的。除此之外,Cursor 还提供了三个方法:isOpen():用于在取数据之前判断 Cursor 对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed():用于判断查询结果是否全部取完。getCurrentIndex():返回已经获取了多少条数据使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理为什么要用流式查询? 如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了 sharding-sphere 的代码不难发现,除了 group by 与 order by 字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。游标查询对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。这种处理方式比常规查询要快很多。当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。Mybatis 的处理加了两个注解: @Options 和 @ResultType@Mapper public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> { // 方式一 多次获取,一次多行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000) Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper); // 方式二 一次获取,一次一行 @Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ") @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000) @ResultType(BigDataSearchEntity.class) void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler); }@OptionsResultSet.FORWORD_ONLY:结果集的游标只能向下滚动ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变fetchSize:每次获取量@ResultType@ResultType(BigDataSearchEntity.class):转换成返回实体类型注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。注意: 虽然上面的代码中都有 @Options 但实际操作却有不同:方式一是多次查询,一次返回多条;方式二是一次查询,一次返回一条;原因: Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。非流式查询和流式查询区别:非流式查询:内存会随着查询记录的增长而近乎直线增长。流式查询:内存会保持稳定,不会随着记录的增长而增长。其内存大小取决于批处理大小BATCH_SIZE的设置,该尺寸越大,内存会越大。所以BATCH_SIZE应该根据业务情况设置合适的大小。另外要切记每次处理完一批结果要记得释放存储每批数据的临时容器,即上文中的 gxids.clear() ;
-
Async/Await 在前端中的应用 async/await 是 ECMAScript 2017 中新增的语法糖,旨在简化异步编程。它基于 Promise ,并通过引入 async 和 await 关键字来使异步代码看起来更像同步代码。使用 async/await使用 async/await 的前提条件是要有异步操作,比如发起 AJAX 请求或操作 DOM 。下面是一个简单的例子,展示如何使用 async/await 发起 AJAX 请求:async function getData(url) { try { const response = await fetch(url); const data = await response.json(); return data; } catch (error) { console.error(error); } } const data = getData('https://example.com/data'); data.then((result) => console.log(result));在上面的例子中,我们定义了一个名为 getData 的异步函数,并将其声明为 async 。该函数接受一个 URL 参数,使用 fetch 函数向服务器发送请求,然后等待响应。一旦响应返回,代码就会继续执行,解析 JSON 数据并将其返回。注意,在 try 代码块中使用了 await 关键字,这告诉 JavaScript 引擎等待该行代码的结果,然后继续执行接下来的代码。如果出现错误, catch 代码块会捕获并处理它们。在上述代码中,我们调用了 getData 函数,并使用 .then() 方法处理返回值。由于 getData 函数返回一个 Promise ,因此可以使用 .then() 处理它的结果。错误处理与 Promise 一样,Async/Await 也需要正确地处理错误。如果一个异步操作失败,它将返回一个拒绝( rejected )状态的 Promise 。为了处理异步操作的错误,我们通常会在 try/catch 块中使用 await 。下面是一个错误处理的例子:async function getData(url) { try { const response = await fetch(url); if (!response.ok) { throw new Error('Network response was not ok'); } const data = await response.json(); return data; } catch (error) { console.error(error); } }在上述代码中,我们使用 if 语句检查是否从服务器收到了正常响应。如果没有,我们抛出一个错误。这会触发 catch 代码块,允许我们处理错误。并行处理异步任务在很多情况下,我们需要同时处理多个异步任务。这时,可以使用 Promise.all() 方法来并行执行异步任务,并等待它们全部完成后再继续执行代码。下面是一个例子,展示如何同时发起多个 AJAX 请求并等待它们全部完成:async function fetchData() { const urls = ['https://example.com/data1', 'https://example.com/data2', 'https://example.com/data3']; const promises = urls.map(url => fetch(url)); const responses = await Promise.all(promises); const data = await Promise.all(responses.map(response => response.json())); return data; } const data = fetchData(); data.then((result) => console.log(result));在上述代码中,我们首先定义了一个包含多个 URL 的数组。然后,我们使用 map() 方法将每个 URL 转换为一个 fetch() 方法调用,并将这些调用存储在一个新的数组中。接着,我们使用 Promise.all() 方法等待所有 fetch() 调用都返回结果。然后,我们使用 map() 方法将每个响应解析为 JSON 数据,并将这些数据存储在一个新的数组中。最后,我们将包含所有数据的数组返回到调用方。使用 async/await 处理动画效果在 Web 开发中,通常需要在 DOM 元素上应用动画效果。使用传统的 JavaScript 回调函数和 setTimeout() 方法来实现这些效果可能会导致出现回调地狱的问题。通过使用 async/await,我们可以更轻松地在 DOM 上应用动画效果。例如,下面是一个简单的例子,展示如何使用 async/await 实现淡入动画效果:async function fadeIn(element, duration) { element.style.opacity = 0; element.style.display = 'block'; const start = performance.now(); while (performance.now() - start < duration) { const percentage = (performance.now() - start) / duration; element.style.opacity = Math.min(percentage, 1); await new Promise(resolve => requestAnimationFrame(resolve)); } element.style.opacity = 1; }在上述代码中,我们定义了一个名为 fadeIn 的异步函数,并将其声明为 async。该函数接受两个参数:一个 DOM 元素和一个表示动画持续时间的数字(以毫秒为单位)。在函数的主体中,我们首先设置元素的初始状态:将其不透明度设置为 0,并将其显示出来(通过将其 display 样式设置为 "block" )。接着,我们使用 performance.now() 函数获取当前时间,并在每个帧之间进行循环。在循环内部,我们计算从动画开始到当前帧的时间百分比,并使用该百分比来计算元素应该具有的不透明度值。然后,我们使用 requestAnimationFrame() 函数等待下一帧,并将其封装在一个 Promise 中,以便在下一帧完成时恢复函数的执行。最后,我们将元素的不透明度设置为 1 ,以确保最终状态正确。结论Async/await 是现代 JavaScript 中非常有用的功能,它使异步编程变得更加容易和直观。除了处理 AJAX 请求外,在动画效果和其他异步操作方面也非常有用。希望本文对您有所帮助!
-
Typecho 批量更换文章中的图片地址 前言最近,博客将图片都上传到了七牛云对象存储了(关于本站图床的一些配置),本地服务器的图片也删除了。那么,如何批量修改文章中那么多的图片地址呢?批量修改图片地址这里用phpMyAdmin工具进行演示,当然也可以用navicat等数据库管理工具,都是一样的。首先我们需要确定要更换的地址,要注意路径,比如原本本地服务器存储的域名地址是https://www.xxxx.cn/image/2023/。然后你将2023路径下的所有图片,都上传到了对象存储,地址是:https://img.xxxx.cn/image/2023/ 那么这个时候你只需要批量将原本的https://www.xxx.cn/image/ 更改成https://img.xxxx.cn/image (为什么要带上image呢主要防止有些地方链接非图片,被误更改了)。然后打开数据库管理工具,选择 typecho 的数据库,打开 typecho_contents 表,点击SQL,执行下列sql语句。(这里是 更改文章内图片 的)UPDATE typecho_contents SET text = REPLACE(text,'旧域名地址','新域名地址');然后再去 typecho_fields 表执行下列sql语句(这里是 更改封面图片 的)UPDATE typecho_fields SET str_value = REPLACE(str_value,'旧域名地址','新域名地址');执行后,显示批量更改成功,然后就可以返回博客的文章中查看图片链接是否正确,是否能被访问啦!