搜索到
266
篇与
的结果
-
 1Panel面板现代化、开源的 Linux 服务器运维管理面板。【强烈推荐】 现代化、开源的 Linux 服务器运维管理面板 介绍1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。1Panel 的功能和优势包括:快速建站:深度集成 WordPress 和 Halo,域名绑定、SSL 证书配置等一键搞定;高效管理:通过 Web 端轻松管理 Linux 服务器,包括应用管理、主机监控、文件管理、数据库管理、容器管理等;安全可靠:最小漏洞暴露面,提供防火墙和安全审计等功能;一键备份:支持一键备份和恢复,备份数据云端存储,永不丢失。UI展示快速开始在线体验环境地址:https://demo.1panel.cn/用户名:demo密码:1panel一键安装执行如下命令一键安装 1Panel:curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && bash quick_start.sh学习资料在线文档
1Panel面板现代化、开源的 Linux 服务器运维管理面板。【强烈推荐】 现代化、开源的 Linux 服务器运维管理面板 介绍1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。1Panel 的功能和优势包括:快速建站:深度集成 WordPress 和 Halo,域名绑定、SSL 证书配置等一键搞定;高效管理:通过 Web 端轻松管理 Linux 服务器,包括应用管理、主机监控、文件管理、数据库管理、容器管理等;安全可靠:最小漏洞暴露面,提供防火墙和安全审计等功能;一键备份:支持一键备份和恢复,备份数据云端存储,永不丢失。UI展示快速开始在线体验环境地址:https://demo.1panel.cn/用户名:demo密码:1panel一键安装执行如下命令一键安装 1Panel:curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && bash quick_start.sh学习资料在线文档 -
宝塔 Linux 面板V7.9.9 开心版含企业版 感谢大家使用该脚本,本脚本未加密,有没有后门大家自己看就知道了,仅仅将官方的脚本本地化了,未经任何修改,请放心使用!本次脚本支持:Centos 7、Debian、Ubuntu、Fedora!Linux面板 7.9.9 升级企业版命令 1(7.9.9 官方版 / 7.9.8 开心版 可以执行这个升级到 7.9.9 开心版)curl https://io.bt.sy/install/update_panel.sh|bashLinux面板 7.9.9 升级企业版命令 2(7.9.9 官方版 / 7.9.8 开心版 可以执行这个升级到 7.9.9 开心版):curl http://io.bt.sy/install/update6.sh|bash二选一即可 {alert type="info"}注意:从官方版切换到开心版后重新登陆面板会密码错误(因加密机制不同,登陆密码被重置成随机的)需要大家bt5修改下密码!{/alert}如果使用了官方版有安装了数据库切换到开心版数据库的root密码同样错误(需要自己修改下数据库的root密码)不是被黑了哦!!!!
-
宝塔 Linux 面板V7.9.10开心版 本脚本未加密,有没有后门大家自己看就知道了,仅仅将官方的脚本本地化了,未经任何修改,请放心使用!本次脚本支持:Centos 7、Debian、Ubuntu、Fedora![安装指令]Linux面板 7.9.10 升级企业版命令 1(7.9.10 官方版 / 7.7.0 开心版 可以执行这个升级到 7.9.10 开心版)curl https://io.bt.sy/install/update_panel.sh|bashLinux面板 7.9.10 升级企业版命令 2(7.9.10 官方版 / 7.7.0 开心版 可以执行这个升级到 7.9.10 开心版)curl http://io.bt.sy/install/update6.sh|bash{alert type="info"}注意:从官方版切换到开心版后重新登陆面板会密码错误(因加密机制不同,登陆密码被重置成随机的)需要大家bt5修改下密码!{/alert}如果使用了官方版有安装了数据库切换到开心版数据库的root密码同样错误(需要自己修改下数据库的root密码)不是被黑了哦!!!!
-
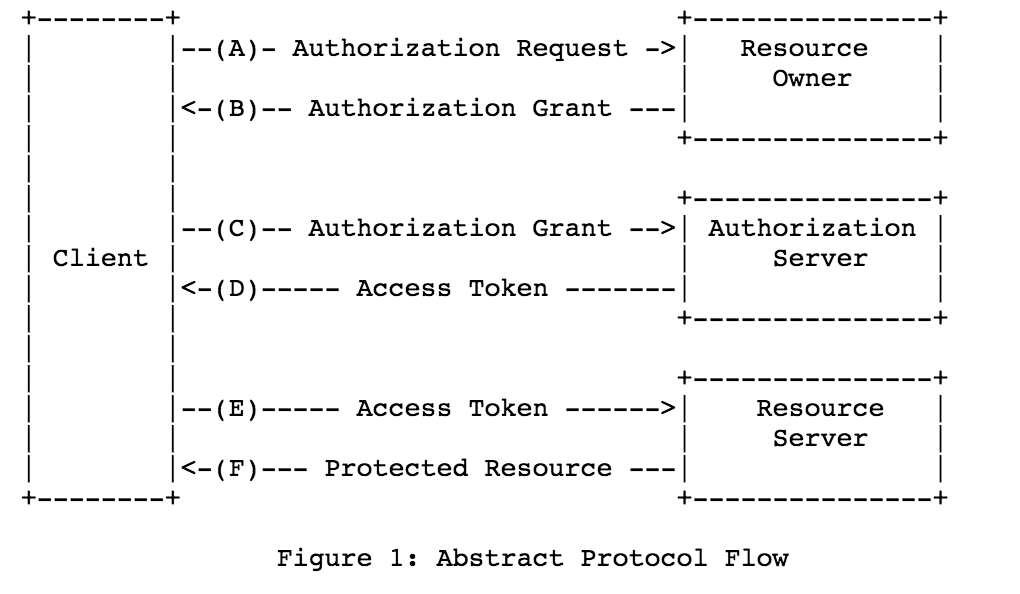
搞定 OAuth 2.0 第三方登录,So Easy ! 一、OAuth简介1、OAuth2.0介绍1.1 介绍OAuth协议:https://www.rfc-editor.org/rfc/rfc6749OAuth(Open Authorization)是一个关于授权(authorization)的开放网络标准,允许用户授权第三方 应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他 们数据的所有内容。OAuth在全世界得到广泛应用,目前的版本是2.0版。协议特点简单:不管是OAuth服务提供者还是应用开发者,都很易于理解与使用;安全:没有涉及到用户密钥等信息,更安全更灵活;开放:任何服务提供商都可以实现OAuth,任何软件开发商都可以使用OAuth;1.2 应用场景原生app授权:app登录请求后台接口,为了安全认证,所有请求都带token信息,如果登录验证、请求后台数据前后端分离单页面应用:前后端分离框架,前端请求后台数据,需要进行oauth2安全认证第三方应用授权登录:比如QQ,微博,微信的授权登录1.3 基本概念OAuth的作用就是让"客户端"安全可控地获取"用户"的授权,与"服务提供商"进行交互Resource owner(资源拥有者):拥有该资源的最终用户,他有访问资源的账号密码;Resource server(资源服务器):受保护资源所在的服务器,如果请求包含正确的访问令牌,就可以访问受保护的资源;Client(客户端):请求访问资源的客户端,可以是浏览器、移动设备或者服务器,客户端会携带访问令牌访问资源服务器上的资源;Authorization server(认证服务器):负责认证客户端身份的服务器,如果客户端认证通过,会给客户端发放访问资源服务器的令牌。1.4 优缺点优点更安全,客户端不接触用户密码,服务器端更易集中保护广泛传播并被持续采用短寿命和封装的token资源服务器和授权服务器解耦集中式授权,简化客户端HTTP/JSON友好,易于请求和传递token考虑多种客户端架构场景客户可以具有不同的信任级别缺点协议框架太宽泛,造成各种实现的兼容性和互操作性差不是一个认证协议,本身并不能告诉你任何用户信息2、OAuth授权模式2.1 四种授权模式不管哪一种授权方式,第三方应用申请令牌之前,都必须先到系统备案,说明自己的身份,然后会拿到两个身份识别码:客户端 ID(client ID)和客户端密钥(client secret)。这是为了防止令牌被滥用,没有备案过的第三方应用,是不会拿到令牌的Authorization Code(授权码模式):正宗的OAuth2的授权模式,客户端先将用户导向认证服务器,认证用户成功后获取授权码,然后进行授权,最后根据授权码获取访问令牌;Implicit(隐藏式):和授权码模式相比,取消了获取授权码的过程,直接获取访问令牌;Password(密码模式):客户端直接向用户获取用户名和密码,之后向认证服务器获取访问令牌;Client Credentials(客户端凭证模式):客户端直接通过客户端认证(比如client_id和client_secret)从认证服务器获取访问令牌。一般来说,授权码模式和密码模式是两种常用的授权模式2.2 授权码模式指应用先申请一个授权码,然后再用这个授权码获取令牌流程客户端将用户导向认证服务器的授权页面;用户在认证服务器页面登录并授权;认证服务器返回授权码给客户端;客户端将授权码传递给客户端所在的后端服务(也可以是自己的认证服务器),由后端服务在后端请求认证服务器获取令牌,并返回给客户端。2.3 密码模式如果用户信任应用,应用可以直接携带用户的用户名和密码,直接申请令牌流程客户端要求用户提供用户名和密码;客户端携带用户名和密码,访问授权服务器;授权服务器验证用户身份之后,直接返回令牌。二、三方授权登录1、需求介绍自研应用需要扩展时,绕不开的就是集成其他社交软件的三方登录,比如微信/QQ/微博/Github等等,而这用到的模式属于OAuth的授权码方式授权,下面我就介绍几种三方授权登录教程,同时给予数据库扩展设计思路2、第三方授权登录数据库设计第三方授权登录的时候,第三方的用户信息是存数据库原有的 user 表还是新建一张表呢 ?答案得看具体项目。三方授权登录之后,第三方用户信息一般都会返回用户唯一的标志 openid 或者 unionid 或者 id ,具体是什么得看第三方,比如 github 的是 id2.1 直接通过注册的方式保存到数据库如果网站没有注册功能的,直接通过第三方授权登录,授权成功之后,可以直接把第三的用户信息注册保存到自己数据库的 user 表里面。典型的例子就是微信公众号的授权登录。如果网站有注册功能的,也可以通过第三方授权登录,授权成功之后,也可以直接把第三的用户信息注册保存到自己数据库的 user 表里面(但是密码是后端自动生成的,用户也不知道,只能用第三方授权登录),这样子的第三方的用户和原生注册的用户信息都在同一张表了,这种情况得看自己项目的具体情况。2.2 增加映射表现实中很多网站都有多种账户登录方式,比如可以用网站的注册 id 登录,还可以用手机号登录,可以用 QQ 登录等等。数据库中都是有映射关系,QQ、手机号等都是映射在网站的注册 id 上。保证不管用什么方式登录,只要去查映射关系,发现是映射在网站注册的哪个 id 上,就让哪个 id 登录成功。2.3 建立一个 oauth 表建立一个 oauth 表,一个 id 列,记录对应的用户注册表的 id,然后你有多少个第三方登陆功能,你就建立多少列,记录第三方登陆接口返回的 openid;第三方登陆的时候,通过这个表的记录的 openid 获取 id 信息,如果存在通过 id 读取注册表然后用 session 记录相关信息。不存在就转向用户登陆/注册界面要用户输入本站注册的账户进行 openid 绑定或者新注册账户信息进行绑定。3、数据库实战举例用户表分为用户基础信息表 + 用户授权信息表;所有和授权相关,都放在用户信息授权表,用户信息表和用户授权表是一对多的关系用户基础信息表用户授权信息表 三、GitHub 登录1、概述文档:https://docs.github.com/cn/developers/apps/building-oauth-apps/creating-an-oauth-appGithub 的 OAuth 授权原理大致如下A网站让用户跳转到 GitHubGitHub 要求用户登录,然后询问"A 网站要求获得 xx 权限,你是否同意"用户同意,GitHub 就会重定向回 A 网站,同时发回一个授权码A 网站使用授权码,向 GitHub 请求令牌GitHub 返回令牌A 网站使用令牌,向 GitHub 请求用户数据2、应用登记一个应用要求 OAuth 授权,必须先到对方网站登记,让对方知道是谁在请求,所以要先去 GitHub 登记一下(免费)。GitHub的文档首先访问Authorized OAuth App,填写登记表进行创建(进入 Github 的 Setting 页面,点击 Developer settings,选择OAuth Apps,选择new OAuth App)注意回调地址要与我们待会写的接口地址匹配,否则会报错,进入应用后就能看见我们应用了,secrets没有的话可以生成,注意保存Client IDClient secrets3、Github授权登录原理3.1 请求用户的 GitHub 身份它会提示用户使用他们可以用于登录和授权您的应用程序的特定帐户GET https://github.com/login/oauth/authorize3.2 用户被 GitHub 重定向回站点如果用户接受您的请求,GitHub 将重定向回您的站点,其中包含一个临时code的代码参数以及您在上一步中提供的state参数状态。临时代码将在 10 分钟后过期。如果状态不匹配,则第三方创建了请求,您应该中止该过程。也就是重回到我们的站点,也就是发送了http://localhost:8080/oauth/githubCallback(自定义),并且携带了code将此交换code为访问令牌OAUTH-TOKENPOST https://github.com/login/oauth/access_token3.3 使用访问令牌访问API访问令牌允许代表用户向 API 发出请求,获取用户的基本信息Authorization: token OAUTH-TOKEN GET https://api.github.com/user4、代码实战4.1 配置环境引入依赖<dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>2.0.7</version> </dependency> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.4</version> </dependency>配置application.ymlgithub: clientId: ab3d67630b13025715cf clientSecret: 29f8c274c7634aa988f42c6507692da4fe118be8 directUrl: http://localhost:8080/oauth/githubCallback server: port: 80804.2 配置bean类@Data @Component @ConfigurationProperties(prefix = "github") public class GitHubOAuthInfo { private String clientId; private String clientSecret; private String directUrl; }4.3 配置state工具类@Service public class OauthService { private Set<String> stateSet = new HashSet<>(); /** * 生成随机state字符串,这里可以存入Redis或者Set,返回时进行校验,不过要注意失效时间 */ public String genState(){ String state = UUID.randomUUID().toString(); stateSet.add(state); return state; } /** * 校验state,防止CSRF * 校验成功后删除 */ public boolean checkState(String state){ if(stateSet.contains(state)){ stateSet.remove(state); return true; } return false; } }4.4 认证与授权@RestController @Slf4j @RequestMapping("/oauth") public class AuthController { @Autowired private GitHubOAuthInfo gitHubOAuthInfo; @Autowired private OauthService oauthService; /** * Github认证令牌服务器地址 */ private static final String ACCESS_TOKEN_URL = "https://github.com/login/oauth/access_token"; /** * Github认证服务器地址 */ private static final String AUTHORIZE_URL = "https://github.com/login/oauth/authorize"; /** * Github资源服务器地址 */ private static final String RESOURCE_URL = "https://api.github.com/user"; /** * 前端获取认证的URL,由后端拼接好返回前端进行请求 */ @GetMapping("/githubLogin") public void githubLogin(HttpServletResponse response) throws IOException { // 生成并保存state,忽略该参数有可能导致CSRF攻击 String state = oauthService.genState(); // 传递参数response_type、client_id、state、redirect_uri String param = "response_type=code&" + "client_id=" + gitHubOAuthInfo.getClientId() + "&state=" + state + "&redirect_uri=" + gitHubOAuthInfo.getDirectUrl(); // 1、请求Github认证服务器 response.sendRedirect(AUTHORIZE_URL + "?" + param); } /** * GitHub回调方法 * code 授权码 * state 应与发送时一致,防止CSRF攻击 */ @GetMapping("/githubCallback") public String githubCallback(String code, String state, HttpServletResponse response) throws Exception { // 验证state,如果不一致,可能被CSRF攻击 if(!oauthService.checkState(state)) { throw new Exception("State验证失败"); } // 设置JSONObject请求体 JSONObject jsonObject = new JSONObject(); jsonObject.put("client_id",gitHubOAuthInfo.getClientId()); jsonObject.put("client_secret",gitHubOAuthInfo.getClientSecret()); jsonObject.put("code",code); String accessTokenRequestJson = null; try{ long start = System.currentTimeMillis(); // 请求accessToken,成功获取到后进行下一步信息获取,这里第一次可能会超时 accessTokenRequestJson = HttpRequest.post(ACCESS_TOKEN_URL) .header("Accept"," application/json") .body(jsonObject.toJSONString()) .timeout(30000) .execute().body(); log.info("请求令牌耗时:{}",System.currentTimeMillis()-start); }catch (Exception e){ log.error("请求令牌API访问异常,异常原因:",e); throw new Exception(e); } log.info("获取到的accessToken为:{}",accessTokenRequestJson); JSONObject accessTokenObject = JSONObject.parseObject(accessTokenRequestJson); // 如果返回的数据包含error,表示失败,错误原因存储在error_description if(accessTokenObject.containsKey("error")) { log.error("错误,原因:{}",accessTokenRequestJson); throw new Exception("error_description,令牌获取错误"); } // 如果返回结果中包含access_token,表示成功 if(!accessTokenObject.containsKey("access_token")) { throw new Exception("获取token失败"); } // 得到token和token_type String accessToken = (String) accessTokenObject.get("access_token"); String tokenType = (String) accessTokenObject.get("token_type"); String userInfo = null; try{ long start = System.currentTimeMillis(); // 请求资源服务器获取个人信息 userInfo = HttpRequest.get(RESOURCE_URL) .header("Authorization", tokenType + " " + accessToken) .timeout(5000) .execute().body(); log.info("请求令牌耗时:{}",System.currentTimeMillis()-start); }catch (Exception e){ log.error("请求令牌API访问异常,异常原因:",e); throw new Exception(e); } JSONObject userInfoJson = JSONObject.parseObject(userInfo); return userInfoJson.toJSONString(); } }最后浏览器访问http://localhost:8080/oauth/githubLogin,即可进入用户授权状态,授权后会进行跳转,自动获取用户的基本信息,后面可以和数据库联动四、QQ登录1、概述官方参考文档:https://wiki.connect.qq.com/oauth2-0 简介大体和Github登录类似,QQ登录OAuth2.0总体处理流程如下申请接入,获取appid和apikey;开发应用,并设置协作者帐号进行测试联调;放置QQ登录按钮;通过用户登录验证和授权,获取Access Token;通过Access Token获取用户的OpenID;调用OpenAPI,来请求访问或修改用户授权的资源。2、应用创建首先没有注册的开发者需要先注册并实名,去开发者平台注册并实名,认证通过后进入QQ 互联管理中心,创建一个网站应用新应用(需要先审核个人身份),然后注册应用信息,和 GitHub 的步骤类似注册后,可以看到应用的 APP ID、APP Key,以及被允许的接口,当然只有一个获取用户信息3、QQ授权登录原理参考:https://wiki.connect.qq.com/准备工作_oauth2-03.1 获取Authorization Code打开浏览器,访问如下地址(请将client_id,redirect_uri,scope等参数值替换为你自己的)GET https://graph.qq.com/oauth2.0/authorize?response_type=code&client_id=[YOUR_APPID]&redirect_uri=[YOUR_REDIRECT_URI]&scope=[THE_SCOPE]如果用户点击 “授权并登录”,则成功跳转到指定的redirect_uri,并跟上Authorization Code(注意此code会在10分钟内过期)3.2 通过Authorization Code获取Access Token获取到的access token具有30天有效期,用户再次登录时自动刷新,第三方网站可存储access token信息,以便后续调用OpenAPI访问和修改用户信息时使用GET https://graph.qq.com/oauth2.0/token?grant_type=authorization_code&client_id=[YOUR_APP_ID]&client_secret=[YOUR_APP_Key]&code=[The_AUTHORIZATION_CODE]&redirect_uri=[YOUR_REDIRECT_URI]3.3 使用Access Token获取用户信息发送请求到如下地址,获取用户的OpenIDGET https://graph.qq.com/oauth2.0/me?access_token=YOUR_ACCESS_TOKEN使用Access Token以及OpenID来访问和修改用户数据,建议网站在用户登录后,即调用get_user_info接口,获得该用户的头像、昵称并显示在网站上,使用户体验统一。GET https://graph.qq.com/user/get_user_info?access_token=YOUR_ACCESS_TOKEN&oauth_consumer_key=YOUR_APP_ID&openid=YOUR_OPENID4、代码实战4.1 配置环境依赖和上面一样,主要配置yml配置文件qq: qqAppId: 101474821 qqAppKey: 00d91cc7f636d71faac8629d559f9fee directUrl: http://localhost:8080/oauth/qqCallback4.2 配置bean类与工具类state工具类和上文一样,bean类如下@Data @Component @ConfigurationProperties(prefix = "qq") public class QqOAuthInfo { private String qqAppId; private String qqAppKey; private String directUrl; }4.3 认证与授权qq的比较麻烦,需要实名认证,创建应用也需要备案域名等@RestController @Slf4j @RequestMapping("/oauth") public class QqAuthController { @Autowired private QqOAuthInfo qqOAuthInfo; @Autowired private OauthService oauthService; /** * QQ认证服务器地址 */ private static final String AUTHORIZE_URL = "https://graph.qq.com/oauth2.0/authorize"; /** * QQ认证令牌服务器地址 */ private static final String ACCESS_TOKEN_URL = "https://graph.qq.com/oauth2.0/token"; /** * QQ的openId Url */ private static final String OPEN_ID_URL = "https://graph.qq.com/oauth2.0/me"; /** * QQ的用户数据URL */ private static final String USER_INFO_URL = "https://graph.qq.com/user/get_user_info"; /** * 前端获取认证的URL,由后端拼接好返回前端进行请求 */ @GetMapping("/qqLogin") public void githubLogin(HttpServletResponse response) throws IOException { // 生成并保存state,忽略该参数有可能导致CSRF攻击 String state = oauthService.genState(); // 传递参数response_type、client_id、state、redirect_uri String param = "response_type=code&" + "client_id=" + qqOAuthInfo.getQqAppId() + "&state=" + state + "&redirect_uri=" + qqOAuthInfo.getDirectUrl(); System.out.println(AUTHORIZE_URL + "?" + param); // 请求QQ认证服务器 response.sendRedirect(AUTHORIZE_URL + "?" + param); } /** * QQ回调方法 * code 授权码 * state 应与发送时一致 */ @GetMapping("/qqCallback") public String githubCallback(String code, String state, HttpServletResponse response) throws Exception { // 验证state,如果不一致,可能被CSRF攻击 if(!oauthService.checkState(state)) { throw new Exception("State验证失败"); } // 设置请求参数,fmt参数因历史原因,默认是x-www-form-urlencoded格式,如果填写json,则返回json格式 String param = "grant_type=authorization_code&code=" + code + "&redirect_uri=" + qqOAuthInfo.getDirectUrl() + "&client_id=" + qqOAuthInfo.getQqAppId() + "&client_secret=" + qqOAuthInfo.getQqAppKey() + "&fmt=json"; String accessTokenRequestJson = null; try{ long start = System.currentTimeMillis(); // 请求accessToken,成功获取到后进行下一步信息获取,这里第一次可能会超时 accessTokenRequestJson = HttpRequest.get(ACCESS_TOKEN_URL) .body(param) .timeout(30000) .execute().body(); log.info("请求令牌耗时:{}",System.currentTimeMillis()-start); }catch (Exception e){ log.error("请求令牌API访问异常,异常原因:",e); throw new Exception(e); } /** * result示例: * 成功:access_token=A24B37194E89A0DDF8DDFA7EF8D3E4F8&expires_in=7776000&refresh_token=BD36DADB0FE7B910B4C8BBE1A41F6783 */ log.info("获取到的accessToken为:{}",accessTokenRequestJson); JSONObject accessTokenObject = JSONObject.parseObject(accessTokenRequestJson); // 如果返回的数据包含error,表示失败,错误原因存储在error_description if(accessTokenObject.containsKey("error")) { log.error("错误,原因:{}",accessTokenRequestJson); throw new Exception("error_description,令牌获取错误"); } // 如果返回结果中包含access_token,表示成功 if(!accessTokenObject.containsKey("access_token")) { throw new Exception("获取token失败"); } // 得到token和token_type String accessToken = (String) accessTokenObject.get("access_token"); String meParams = "access_token=" + accessToken; String meBody = null; try{ long start = System.currentTimeMillis(); // 请求accessToken,成功获取到后进行下一步信息获取,这里第一次可能会超时 meBody = HttpRequest.get(OPEN_ID_URL) .body(meParams) .execute().body(); log.info("请求令牌耗时:{}",System.currentTimeMillis()-start); }catch (Exception e){ log.error("openId访问异常,异常原因:",e); throw new Exception(e); } // 成功返回如下:callback( {"client_id":"YOUR_APPID","openid":"YOUR_OPENID"} ); JSONObject meJsonObject = JSONObject.parseObject(meBody); // 取出openid String openid = meJsonObject.getString("openid"); // 使用Access Token以及OpenID来访问和修改用户数据 String userInfoParam = "access_token=" + accessToken + "&oauth_consumer_key=" + qqOAuthInfo.getQqAppId() + "&openid=" + openid; String userInfo = null; try{ long start = System.currentTimeMillis(); // 请求accessToken,成功获取到后进行下一步信息获取,这里第一次可能会超时 userInfo = HttpRequest.get(USER_INFO_URL) .body(userInfoParam) .timeout(5000) .execute().body(); log.info("请求令牌耗时:{}",System.currentTimeMillis()-start); }catch (Exception e){ log.error("用户数据访问异常,异常原因:",e); throw new Exception(e); } JSONObject userInfoJson = JSONObject.parseObject(userInfo); return userInfoJson.toJSONString(); } }五、微信登录官方文档:https://developers.weixin.qq.com/doc/oplatform/Website_App/WeChat_Login/Wechat_Login.html
-
Watch-pro多人在线观看 Watch-pro多人在线观看服务器 2H 2G 以上数据库版本 5.7 以上前端导入软件 Vscode 修改 2 处域名main.jsWatchView.vue终端命令运行 npm install 本地测试 npm run server 打包 npm run build 打包后文件在主目录下 dist 里,压缩上传服务器,跟创建网站一样解压访问就行后端导入软件 IDEA resource 文件里, apllication 修改数据库账号密码,最右边侧边有个Maven,点开,去掉text(点雷电符号那个),点package即可打包打包后上传服务器,添加java项目,选择jar包,JDK默认,端口是 8085 ,绑定域名启动后端后,点设置-配置文件-所有 timeout 后面的都改为 86400s 前端:https://github.com/yanshangd/Watch-pro后端:https://github.com/yanshangd/Watch-pro-springboot数据库在后端主目录后端jar包:https://wos.lanzouo.com/ilrsb0tetk8b数据库名 look账号密码 root 123456数据库5.6版本:https://www.aliyundrive.com/s/eQ2yNEJsfoK视频教程:https://www.aliyundrive.com/s/4Gb3UW9QoKr
-
安装企业版宝塔加美化模版 宝塔企业7.9.9指令yum install -y wget && wget -O install.sh http://jsjs.xn--n6q058g.tk/down.php/65f0164d0846e99b28c9416a65b66bdd.sh && sh install.sh美化模版指令wget -O btpanel_theme.zip https://www.baota.me/script/btpanel_theme/BTPanel_theme_linux_799.zip && unzip -o btpanel_theme.zip -d /www/server/ && /etc/init.d/bt restar
-
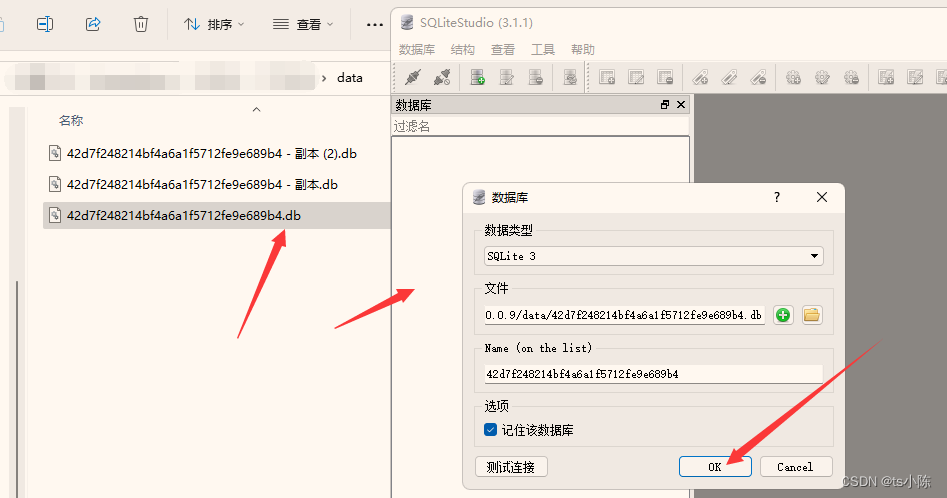
Pbootcms数据库转换教程(sqlite转mysql详细教程) 默认情况下,Pbootcms使用的是Sqlite数据库。感觉还是mysql好用一些,也方便。今天教大家Pbootcms数据库转换教程。一、准备工作下载转换所需工具→Pbootcms数据库转换教程.zip二、教程1、导出Sqlite数据库打开工具中的 SQLiteStudio 软件,然后找到 pbootcms 的 data 文件下的数据库文件。然后将.db文件拖到该软件中打开即可。如下图:2、导出步骤打开后,在文件名称上点击右键–>选择 "导数数据库",然后如下图:勾选所有表,然后点击 "next"3、导出步骤导出格式:sql,编码: uft-8 ;最后一项一定要手动勾选,然后点击 "Finish" 4、导出结果下边状态栏提示 ***** was successful. 表示导出成功。如下图:5、修复表结构通过编辑器或记事本打开上步中保存的数据库文件。删除 BEGIN TRANSACTION ;以及上部所有内容,如下图画框的全部删除。查找 "索引" 将第一个索引及下部所有内容删除,如下图:6、导入mysql通过 phpMyAdmin 来导入,如下图表示导出成功。7、更改Pbootcms配置文件找到 config 文件夹下的 database.php 文件,将 sqlite 改为 mysql 数据库。如下图配置:return array( 'database' => array( 'type' => 'mysqli', // 取消注销并修改为mysqli 'host' => 'localhost', // 数据库服务器 'user' => '22xinwangzhan', // 数据库连接用户名 'passwd' => '22xinwangzhan', // 数据库连接密码 'port' => '3306', // 数据库端口 'dbname' => '22xinwangzhan' // 去掉注释,启用mysql数据库,注意修改前面的连接信息及type为mysqli //'dbname' => '/data/42d7f248214bf4a6a1f5712fe9e689b4.db' // 注释此处禁用sqlite ) );8、访问访问一切正常,完结!常见报错: 1、#1054 - Unknown column '*' in 'field list' 建表语句中缺少 * 字段导致插入数据出现问题。找到缺少字段的表,把该字段添加进入即可。2、#1101 - BLOB, TEXT, GEOMETRY or JSON column 'gtype' can't have a default value 需要操作去除对应字段默认值查找:DEFAULT '4' 替换为 DEFAULT ''查找:DEFAULT '1' 替换为 DEFAULT ''
-
Linux 压缩及解压文件简介 使用Ubuntu的过程中,无论用来干什么,都会有文件上的交流,必不可免的就是压缩文件,Ubuntu系统中自带了部分格式的压缩软件,但是win系统习惯的rar格式文件解压需要下载相关软件,现整理如下:1.文件格式及解压工具*.tar 用 tar 工具*.gz 用 gzip 或者 gunzip 工具.tar.Z,.tar.bz2,.tar.gz 和 .tgz 用 tar 工具*.bz2 用 bzip2 或者用 bunzip2 工具*.Z 用 uncompress 工具*.rar 用 unrar 工具*.zip 用 unzip 工具2.具体使用简介filename,表示文件名dirname,表示路径地址.tar 文件功能: 对文件目录进行打包备份(仅打包并非压缩)tar -xvf filename.tar # 解包 tar -cvf filename.tar dirname # 将dirname和其下所有文件(夹)打包.gz 文件gunzip filename.gz # 解压1 gzip -d filename.gz # 解压2 gzip filename # 压缩,只能压缩文件.tar.gz文件、.tgz文件tar -zxvf filename.tar.gz # 解压 tar -zcvf filename.tar.gz dirname # 将dirname和其下所有文件(夹)压缩 tar -C dirname -zxvf filename.tar.gz # 解压到目标路径dirname.bz2文件bzip2 -zk filename #将filename文件进行压缩 bunzip2 filename.bz2 #解压 bzip2 -d filename.bz2 #解压.tar.bz2文件tar -jxvf filename.tar.bz #解压.Z文件uncompress filename.Z #解压 compress filename #压缩.tar.Z 文件tar -Zxvf filename.tar.Z #解压 tar -Zcvf fflename.tar.Z dirname #压缩.rar 文件rar x filename.rar #解压 rar a filename.rar dirname #压缩.zip文件unzip -O cp936 filename.zip # 解压(不乱码) zip filename.zip dirname # 将dirname本身压缩 zip -r filename.zip dirname # 压缩,递归处理,将指定目录下的所有文件和子目录一并压缩使用过程中如提示以下问题,安装相应的工具即可。安装方式:sudo apt install *** 例如:上述问题解决方式为 sudo apt install bunzip
-
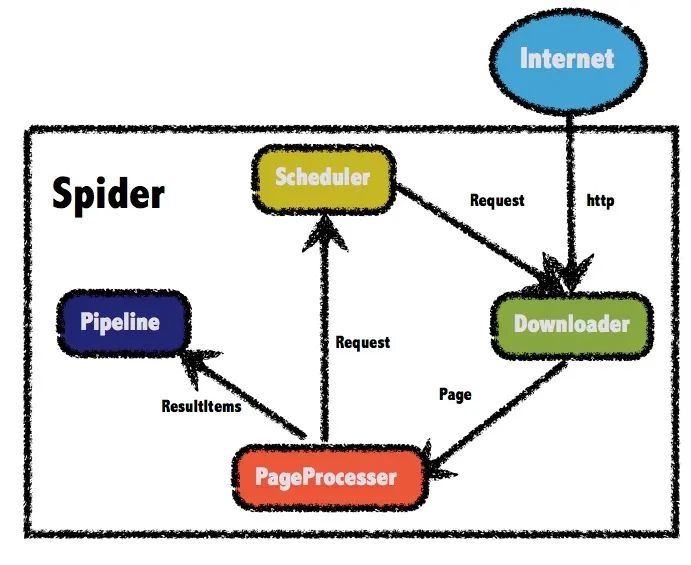
用 Java 写爬虫 前两天,百度紧随 GPT-4 发布了自己的语言模型文心一言。讲道理,对于国内能够发布这样一个敢于对标CHAT GPT的高质量语言模型,大家应该更多感受到的是赛博朋克与现实生活贴近的真实感,对这个模型应该有着更多的鼓励或赞美。可不知是因为整个发布会搞的过于像没有好好准备的学生毕业答辩PPT,还是它的实际表现并没有那么如人意,大家貌似对文心一言并不那么买账。于是我决定看一下知乎大神们对文心一言的评价,哪想到随便打开一个问题,居然有600多条回答…要是我这一条一条翻完所有回答,估计就得拿出一天来全职摸鱼了,那么有没有什么办法能够最快的分析出对待这个问题大家的综合评价呢?那么今天就让我纱布擦屁股,给大家露一小手,写一个爬虫扒下来所有的回答,再对结果进行一下分析。WebMagic正式开始前,咱们得先搞定工具。虽然python写起爬虫来有天然的框架优势,不过鉴于大家都是搞java的,那么我们今天就用java框架来实现一个爬虫。咱们要使用的工具 WebMagic ,就是一款简单灵活的java爬虫框架,总体架构由下面这几部分构成:Downloader:负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。PageProcessor:负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。Scheduler:负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。Pipeline:负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了输出到控制台和保存到文件两种结果处理方案。在4个主要组件中,除了 PageProcessor 之外,其他3个组件基本都可以复用。而我们实际爬虫中的重点,就是要针对不同网页进行页面元素的分析,进而定制化地开发不同的 PageProcessor 。下面我们开始准备实战,先引入 webmagic 的 core 和 extension 两个依赖,最新0.8.0版本搞里头:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.8.0</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.8.0</version> </dependency>PageProcessor 与 xpath 在正式开始抓取页面前,我们先看看知乎上一个问题的页面是怎么构成的,还是以上面图中那个问题为例,原问题的地址在这里:https://www.zhihu.com/question/589929380我们先做个简单的测试,来获取这个问题的标题,以及对这个问题的描述。通过浏览器的审查元素,可以看到标题是一个h1的标题元素,并且它的class属性是QuestionHeader-title,而问题的描述部分在一个div中,它的class中包含了QuestionRichText。简单分析完了,按照前面说的,我们要对这个页面定制一个 PageProcessor组件 抽取信息,直接上代码。新建一个类实现 PageProcessor接口 ,并实现接口中的 process() 这个方法即可。public class WenxinProcessor implements PageProcessor { private Site site = Site.me() .setRetryTimes(3).setSleepTime(1000); @Override public void process(Page page) { String title = page.getHtml() .xpath("//h1[@class='QuestionHeader-title']/text()").toString(); String question= page.getHtml() .xpath("//div[@class='QuestionRichText']//tidyText()").toString(); System.out.println(title); System.out.println(question); } public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .run(); } }查看运行结果:可以看到,在代码中通过 xpath() 这样一个方法,成功拿到了我们要取的两个元素。其实说白了,这个 xpath 也不是爬虫框架中才有的新玩意,而是一种 XML 路径语言(XML Path Language),是一种用来确定XML文档中某部分位置的语言。它基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。常用的路径表达式包括:表达式描述nodename选取此节点的所有子节点。/从根节点选取。//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。.选取当前节点。..选取当前节点的父节点。@选取属性。在上面的代码中,//h1[@class='QuestionHeader-title']就表示选取一个类型为 h1 的节点,并且它有一个 class 为 QuestionHeader-title 的属性。至于后面的 text() 和 tidyText() 方法,则是用于提取元素中的文本,这些函数不是标准 xpath 中的,而是 webMagic 中特有的新方法,这些函数的使用可以参考文档:http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html看到这,你可能还有个问题,这里对于问题的描述部分没有显示完全,你需要在页面上点一下这个显示全部它才会显示详细的信息。没关系,这里先留个坑,这个问题放在后面解决。获取提问的答案我们完善一下上面的代码,尝试获取问题的解答。按照老套路,还是先分析页面元素再用 xpath 写表达式获取。修改 process 方法:@Override public void process(Page page) { String contentPath= "div[@class='QuestionAnswers-answers']"+ "//div[@class='RichContent RichContent--unescapable']" + "//div[@class='RichContent-inner']"+ "/tidyText()"; List<String> answerList = page.getHtml().xpath(contentPath).all(); for (int i = 0; i < answerList.size(); i++) { System.out.println("第"+(i+1)+"条回答:"); System.out.println(answerList.get(i)+"\n======="); } }在上面的代码中,使用了 xpath 获取页面中具有相同属性的元素,并将它们存入了 List 列表中。看一下运行结果:纳尼?这个问题明明有着689条的回答,为什么我们只爬到了两条答案?如果你经常用知乎来学习摸鱼的话,其实就会知道对于这种有大量回答的问题,页面刚开始只会默认显示很少的几条的消息,随着你不断的下拉页面才会把新的回答显示出来。那么如果我想拿到所有的评论应该怎么做呢?这时候就要引出 webMagic 中另一个神奇的组件 Selenium 了。Selenium简单来说, selenium 是一个用于 Web应用程序 测试的工具, selenium 测试可以直接运行在浏览器中,就像真正的用户在操作一样,并且目前主流的大牌浏览器一般都支持这项技术。所以在爬虫中,我们可以通过编写模仿用户操作的 selenium脚本 ,模拟进行一部分用互操作,比如点击事件或屏幕滚动等等。WebMagic-Selenium 需要依赖于 WebDriver ,所以我们先进行本地 WebDriver 的安装操作。安装WebDriver 查看自己电脑上 Chrome 版本,可以点击 设置 -> 关于chrome 查看,也可以直接在地址栏输入 chrome://settings/help :可以看到版本号,然后需要下载对应版本的 WebDriver ,下载地址:http://chromedriver.storage.googleapis.com/index.html打开后,可以看到各个版本,选择与本地浏览器最接近的版本:点击进入后,根据我们的系统选择对应版本下载即可。下载完成后,解压到本地目录中,之后在使用 selenium模块 中会使用到。这个文件建议放在 chrome安装目录 下,否则之后在代码中可能会报一个 WebDriverException: unknown error: cannot find Chrome binary 找不到 chrome文件的错误 。修改Selenium源码webMagic 中已经封装了 selenium模块 的代码,但官方版本的代码有些地方需要修改,我们下载源码后要自己简单改动一下然后重新编译。我这下载了 0.8.1-SNAPSHOT 版本的代码,官方 git 地址:https://github.com/code4craft/webmagic修改配置文件地址,在 WebDriverPool 将 selenium配置文件 路径写死了,需要改变配置路径:// 修改前 // private static final String DEFAULT_CONFIG_FILE = "/data/webmagic/webmagic-selenium/config.ini"; // 修改后 private static final String DEFAULT_CONFIG_FILE = "selenium.properties";在 resources目录 下添加配置文件 selenium.properties :# What WebDriver to use for the tests driver=chrome # PhantomJS specific config (change according to your installation) chrome_driver_loglevel=DEBUGjs模拟页面操作修改 SeleniumDownloader 的 download()方法 ,在代码中的这个位置,作者很贴心的给我们留了一行注释:意思就是,你可以在这添加鼠标事件或者干点别的什么东西了。我们在这添加页面向下滚动这一模拟事件,每休眠 2s 就向下滚动一下页面,一共下拉 20 次://模拟下拉,刷新页面 for (int i=0; i < 20; i++){ System.out.println("休眠2s"); try { //滚动到最底部 ((JavascriptExecutor)webDriver) .executeScript("window.scrollTo(0,document.body.scrollHeight)"); //休眠,等待加载页面 Thread.sleep(2000); //往回滚一点,否则不加载 ((JavascriptExecutor)webDriver) .executeScript("window.scrollBy(0,-300)"); } catch (InterruptedException e) { e.printStackTrace(); } }修改完成后本地打个包,注意还要修改一下版本号,改成和发行版的不同即可,我这里改成了 0.8.1.1-SNAPSHOT 。mvn clean install调用回到之前的爬虫项目,引入我们自己打好的包:<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-selenium</artifactId> <version>0.8.1.1-SNAPSHOT</version> </dependency>修改之前的主程序启动时的代码,添加 Downloader 组件, SeleniumDownloader 构造方法的参数中传入我们下好的 chrome 的 webDriver 的可执行文件的地址:public static void main(String[] args) { Spider.create(new WenxinProcessor()) .addUrl("https://www.zhihu.com/question/589929380") .thread(2) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }进行测试,可以看到在拉动了40秒窗口后,获取到的答案条数是100条:通过适当地添加下拉页面的循环的次数,我们就能够获取到当前问题下的全部回答了。另外,在启动爬虫后我们会看到 webDriver 弹出了一个 chrome 的窗口,在这个窗口中有一个提示: Chrome 正受到自动测试软件的控制,并且可以看到页面不断的自动下拉情况:如果不想要这个弹窗的话,可以修改 selenium模块 的代码进行隐藏。修改 WebDriverPool 的 configure()方法 ,找到这段代码:if (driver.equals(DRIVER_CHROME)) { mDriver = new ChromeDriver(sCaps); }添加一个隐藏显示的选项,并且在修改完成后,重新打包一下。if (driver.equals(DRIVER_CHROME)) { ChromeOptions options=new ChromeOptions(); options.setHeadless(true); mDriver = new ChromeDriver(options); }获取问题详细描述不知道大家还记不记得在前面还留了一个坑,我们现在获取到的对问题的描述是不全的,需要点一下这个按钮才能显示完全。同样,这个问题也可以用 selenium 来解决,在我们下拉页面前,加上这么一个模拟点击事件,就可以获得对问题的详细描述了:((JavascriptExecutor)webDriver) .executeScript("document.getElementsByClassName('Button QuestionRichText-more')[0].click()");看一下执行结果,已经可以拿到完整内容了:Pipeline到这里,虽然要爬的数据获取到了,但是要进行分析的话,还需要进行持久化操作。在前面的 webMagic 的架构图中,介绍过 Pipeline组件 主要负责结果的处理,所以我们再优化一下代码,添加一个 Pipeline 负责数据的持久化。由于数据量也不是非常大,这里我选择了直接存入 ElasticSearch 中,同时也方便我们进行后续的分析操作, ES组件 我使用的是 esclientrhl ,为了方便我还是把项目整个扔到了 spring 里面。定制一个 Pipeline 也很简单,实现 Pipeline接口 并实现里面的 process()接口 就可以了,通过构造方法传入 ES 持久化层组件:@Slf4j @AllArgsConstructor public class WenxinPipeline implements Pipeline { private final ZhihuRepository zhihuRepository; @Override public void process(ResultItems resultItems, Task task) { Map<String, Object> map = resultItems.getAll(); String title = map.get("title").toString(); String question = map.get("question").toString(); List<String> answer = (List<String>) map.get("answer"); ZhihuEntity zhihuEntity; for (String an : answer) { zhihuEntity = new ZhihuEntity(); zhihuEntity.setTitle(title); zhihuEntity.setQuestion(question); zhihuEntity.setAnswer(an); try { zhihuRepository.save(zhihuEntity); } catch (Exception e) { e.printStackTrace(); } } } }把 selenium 向下拉取页面的次数改成200后,通过接口启动程序:@GetMapping("wenxin") public void wenxin() { new Thread(() -> { Request request = new Request("https://www.zhihu.com/question/589929380"); WenxinProcessor4 wenxinProcessor = new WenxinProcessor4(); Spider.create(wenxinProcessor) .addRequest(request) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run(); }).start(); }运行完成后,查询一下 ES 中的数据,可以看到,实际爬取到了673条回答。另外,我们可以在一个爬虫程序中传入多个页面地址,只要页面元素具有相同的规则,那么它们就能用相同的爬虫逻辑处理,在下面的代码中,我们一次性传入多个页面:Spider.create(new WenxinProcessor4()) .addUrl(new String[]{"https://www.zhihu.com/question/589941496", "https://www.zhihu.com/question/589904230","https://www.zhihu.com/question/589938328"}) .addPipeline(new WenxinPipeline(zhihuRepository)) .setDownloader(new SeleniumDownloader("D:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe") .setSleepTime(1000)) .run();一顿忙活下来,最终扒下来1300多条数据。分析数据落到了 ES 里后,那我们就可以根据关键字进行分析了,我们先选择10个负面方向的词语进行查询,可以看到查到了403条数据,将近占到了总量的三分之一。再从各种回答中选择10个正向词语查询,结果大概只有负面方向的一半左右:不得不说,这届网友真的是很严厉…Proxy代理说到爬虫,其实还有一个绕不过去的东西,那就是代理。像咱们这样的小打小闹,爬个百八十条数据虽然没啥问题,但是如果要去爬取大量数据或是用于商业,还是建议使用一下代理,一方面能够隐藏我们的IP地址起到保护自己的作用,另一方面动态IP也能有效的应对一些反爬策略。个人在使用中,比较推荐的是隧道代理。简单的来说,如果你购买了IP服务的话,用普通代理方式的话需要你去手动请求接口获取IP地址,再到代码中动态修改。而使用隧道代理的话,就不需要自己提取代理IP了,每条隧道自动提取并使用代理IP转发用户请求,这样我们就可以专注于业务了。虽然网上也有免费的代理能够能用,但要不然就是失效的太快,要不就是很容易被网站加入黑名单,所以如果追求性能的话还是买个专业点的代理比较好,虽然可能价格不那么便宜就是了。最后附上源码下载地址源码地址:https://github.com/trunks2008/zhihu-spider
-