搜索到
266
篇与
的结果
-
 SpringBoot 玩一玩代码混淆,防止反编译代码泄露 编译简单就是把代码跑一哈,然后我们的代码 .java文件 就被编译成了 .class 文件反编译就是针对编译生成的 jar/war 包 里面的 .class 文件 逆向还原回来,可以看到你的代码写的啥。比较常用的反编译工具 JD-GUI ,直接把编译好的jar丢进去,大部分都能反编译看到源码:那如果不想给别人反编译看自己写的代码呢?怎么做?混淆该篇玩的代码混淆 ,是其中一种手段。我给你看,但你反编译看到的不是真正的代码。先看一张效果示例图 :开整正文先看一下我们混淆一个项目代码,要做啥?一共就两步第一步, 在项目路径下,新增一份文件 proguard.cfg :proguard.cfg#指定Java的版本 -target 1.8 #proguard会对代码进行优化压缩,他会删除从未使用的类或者类成员变量等 -dontshrink #是否关闭字节码级别的优化,如果不开启则设置如下配置 -dontoptimize #混淆时不生成大小写混合的类名,默认是可以大小写混合 -dontusemixedcaseclassnames # 对于类成员的命名的混淆采取唯一策略 -useuniqueclassmembernames #混淆时不生成大小写混合的类名,默认是可以大小写混合 -dontusemixedcaseclassnames #混淆类名之后,对使用Class.forName('className')之类的地方进行相应替代 -adaptclassstrings #对异常、注解信息予以保留 -keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LineNumberTable,*Annotation*,EnclosingMethod # 此选项将保存接口中的所有原始名称(不混淆)--> -keepnames interface ** { *; } # 此选项将保存所有软件包中的所有原始接口文件(不进行混淆) #-keep interface * extends * { *; } #保留参数名,因为控制器,或者Mybatis等接口的参数如果混淆会导致无法接受参数,xml文件找不到参数 -keepparameternames # 保留枚举成员及方法 -keepclassmembers enum * { *; } # 不混淆所有类,保存原始定义的注释- -keepclassmembers class * { @org.springframework.context.annotation.Bean *; @org.springframework.beans.factory.annotation.Autowired *; @org.springframework.beans.factory.annotation.Value *; @org.springframework.stereotype.Service *; @org.springframework.stereotype.Component *; } #忽略warn消息 -ignorewarnings #忽略note消息 -dontnote #打印配置信息 -printconfiguration -keep public class com.example.myproguarddemo.MyproguarddemoApplication { public static void main(java.lang.String[]); }注意点:其余的看注释,可以配置哪些类不参与混淆,哪些枚举保留,哪些方法名不混淆等等。第二步,在 pom 文件上 加入 proguard 混淆插件 :build标签里面改动加入一下配置<build> <plugins> <plugin> <groupId>com.github.wvengen</groupId> <artifactId>proguard-maven-plugin</artifactId> <version>2.6.0</version> <executions> <!-- 以下配置说明执行mvn的package命令时候,会执行proguard--> <execution> <phase>package</phase> <goals> <goal>proguard</goal> </goals> </execution> </executions> <configuration> <!-- 就是输入Jar的名称,我们要知道,代码混淆其实是将一个原始的jar,生成一个混淆后的jar,那么就会有输入输出。 --> <injar>${project.build.finalName}.jar</injar> <!-- 输出jar名称,输入输出jar同名的时候就是覆盖,也是比较常用的配置。 --> <outjar>${project.build.finalName}.jar</outjar> <!-- 是否混淆 默认是true --> <obfuscate>true</obfuscate> <!-- 配置一个文件,通常叫做proguard.cfg,该文件主要是配置options选项,也就是说使用proguard.cfg那么options下的所有内容都可以移到proguard.cfg中 --> <proguardInclude>${project.basedir}/proguard.cfg</proguardInclude> <!-- 额外的jar包,通常是项目编译所需要的jar --> <libs> <lib>${java.home}/lib/rt.jar</lib> <lib>${java.home}/lib/jce.jar</lib> <lib>${java.home}/lib/jsse.jar</lib> </libs> <!-- 对输入jar进行过滤比如,如下配置就是对META-INFO文件不处理。 --> <inLibsFilter>!META-INF/**,!META-INF/versions/9/**.class</inLibsFilter> <!-- 这是输出路径配置,但是要注意这个路径必须要包括injar标签填写的jar --> <outputDirectory>${project.basedir}/target</outputDirectory> <!--这里特别重要,此处主要是配置混淆的一些细节选项,比如哪些类不需要混淆,哪些需要混淆--> <options> <!-- 可以在此处写option标签配置,不过我上面使用了proguardInclude,故而我更喜欢在proguard.cfg中配置 --> </options> </configuration> </plugin> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>repackage</goal> </goals> <configuration> <mainClass>com.example.myproguarddemo.MyproguarddemoApplication</mainClass> </configuration> </execution> </executions> </plugin> </plugins> </build>注意点:然后可以看到:然后点击 package,正常执行编译打包流程就可以 :然后可以看到jar的生成:看看效果:好了,该篇就到这。
SpringBoot 玩一玩代码混淆,防止反编译代码泄露 编译简单就是把代码跑一哈,然后我们的代码 .java文件 就被编译成了 .class 文件反编译就是针对编译生成的 jar/war 包 里面的 .class 文件 逆向还原回来,可以看到你的代码写的啥。比较常用的反编译工具 JD-GUI ,直接把编译好的jar丢进去,大部分都能反编译看到源码:那如果不想给别人反编译看自己写的代码呢?怎么做?混淆该篇玩的代码混淆 ,是其中一种手段。我给你看,但你反编译看到的不是真正的代码。先看一张效果示例图 :开整正文先看一下我们混淆一个项目代码,要做啥?一共就两步第一步, 在项目路径下,新增一份文件 proguard.cfg :proguard.cfg#指定Java的版本 -target 1.8 #proguard会对代码进行优化压缩,他会删除从未使用的类或者类成员变量等 -dontshrink #是否关闭字节码级别的优化,如果不开启则设置如下配置 -dontoptimize #混淆时不生成大小写混合的类名,默认是可以大小写混合 -dontusemixedcaseclassnames # 对于类成员的命名的混淆采取唯一策略 -useuniqueclassmembernames #混淆时不生成大小写混合的类名,默认是可以大小写混合 -dontusemixedcaseclassnames #混淆类名之后,对使用Class.forName('className')之类的地方进行相应替代 -adaptclassstrings #对异常、注解信息予以保留 -keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LineNumberTable,*Annotation*,EnclosingMethod # 此选项将保存接口中的所有原始名称(不混淆)--> -keepnames interface ** { *; } # 此选项将保存所有软件包中的所有原始接口文件(不进行混淆) #-keep interface * extends * { *; } #保留参数名,因为控制器,或者Mybatis等接口的参数如果混淆会导致无法接受参数,xml文件找不到参数 -keepparameternames # 保留枚举成员及方法 -keepclassmembers enum * { *; } # 不混淆所有类,保存原始定义的注释- -keepclassmembers class * { @org.springframework.context.annotation.Bean *; @org.springframework.beans.factory.annotation.Autowired *; @org.springframework.beans.factory.annotation.Value *; @org.springframework.stereotype.Service *; @org.springframework.stereotype.Component *; } #忽略warn消息 -ignorewarnings #忽略note消息 -dontnote #打印配置信息 -printconfiguration -keep public class com.example.myproguarddemo.MyproguarddemoApplication { public static void main(java.lang.String[]); }注意点:其余的看注释,可以配置哪些类不参与混淆,哪些枚举保留,哪些方法名不混淆等等。第二步,在 pom 文件上 加入 proguard 混淆插件 :build标签里面改动加入一下配置<build> <plugins> <plugin> <groupId>com.github.wvengen</groupId> <artifactId>proguard-maven-plugin</artifactId> <version>2.6.0</version> <executions> <!-- 以下配置说明执行mvn的package命令时候,会执行proguard--> <execution> <phase>package</phase> <goals> <goal>proguard</goal> </goals> </execution> </executions> <configuration> <!-- 就是输入Jar的名称,我们要知道,代码混淆其实是将一个原始的jar,生成一个混淆后的jar,那么就会有输入输出。 --> <injar>${project.build.finalName}.jar</injar> <!-- 输出jar名称,输入输出jar同名的时候就是覆盖,也是比较常用的配置。 --> <outjar>${project.build.finalName}.jar</outjar> <!-- 是否混淆 默认是true --> <obfuscate>true</obfuscate> <!-- 配置一个文件,通常叫做proguard.cfg,该文件主要是配置options选项,也就是说使用proguard.cfg那么options下的所有内容都可以移到proguard.cfg中 --> <proguardInclude>${project.basedir}/proguard.cfg</proguardInclude> <!-- 额外的jar包,通常是项目编译所需要的jar --> <libs> <lib>${java.home}/lib/rt.jar</lib> <lib>${java.home}/lib/jce.jar</lib> <lib>${java.home}/lib/jsse.jar</lib> </libs> <!-- 对输入jar进行过滤比如,如下配置就是对META-INFO文件不处理。 --> <inLibsFilter>!META-INF/**,!META-INF/versions/9/**.class</inLibsFilter> <!-- 这是输出路径配置,但是要注意这个路径必须要包括injar标签填写的jar --> <outputDirectory>${project.basedir}/target</outputDirectory> <!--这里特别重要,此处主要是配置混淆的一些细节选项,比如哪些类不需要混淆,哪些需要混淆--> <options> <!-- 可以在此处写option标签配置,不过我上面使用了proguardInclude,故而我更喜欢在proguard.cfg中配置 --> </options> </configuration> </plugin> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>repackage</goal> </goals> <configuration> <mainClass>com.example.myproguarddemo.MyproguarddemoApplication</mainClass> </configuration> </execution> </executions> </plugin> </plugins> </build>注意点:然后可以看到:然后点击 package,正常执行编译打包流程就可以 :然后可以看到jar的生成:看看效果:好了,该篇就到这。 -
微软发布史上最强虚拟机!流畅度堪比主机(附保姆级安装教程) 虚拟化技术有以下几个关键概念虚拟化技术的优点Hyper-V 简介启动 Hyper-V创建虚拟机虚拟化技术有以下几个关键概念主机(Host):也称为宿主机或物理机,指实际物理计算机,它上面部署了虚拟化软件的hypervisor。客户机(Guest):也称为虚拟机实例,指在主机上运行的虚拟环境,每个客户机都运行独立的操作系统和应用程序。Hypervisor:虚拟机监控器,是虚拟化软件的核心组件,负责管理和分配主机资源给客户机,并提供虚拟机的隔离性和管理功能。Hypervisor可以分为两种类型:类型1 Hypervisor(裸金属Hypervisor):直接安装在物理硬件上,作为主机操作系统。它能够更好地利用硬件资源,提供更高的性能和效率,而且更稳定可靠。类型2 Hypervisor(主机操作系统上的Hypervisor):安装在主机操作系统之上,例如在Windows或Linux操作系统之上。它相对较轻量,易于安装和管理,但性能和效率可能略低。资源池化:虚拟化技术可以将主机上的物理资源进行整合和共享,形成一个资源池。资源池可以根据需要动态分配和调整资源,提高资源利用率,实现更好的性能和灵活性。快照与复制:虚拟化技术提供了创建虚拟机快照和复制的功能。通过快照,可以记录虚拟机在某个时间点的状态,并在需要时进行还原。这对于备份、恢复和测试非常有用。虚拟化技术的优点资源利用率提高:通过虚拟化,可以更好地利用和共享物理计算机的资源,提高硬件资源的利用率。灵活性和可扩展性:虚拟化技术允许在同一台物理机上创建多个虚拟环境,根据需求动态配置和调整资源,以实现更好的灵活性和可扩展性。简化管理:虚拟化技术通过虚拟机管理工具提供集中化的管理和监控功能,简化了物理服务器的管理工作。高可用性和容灾:通过虚拟机迁移和聚合技术,可以实现虚拟机的高可用性和灾难恢复,提高系统的可靠性和稳定性。无论你是软件开发人员、IT 专业人员还是技术爱好者,你们中的许多人都需要运行多个操作系统。Hyper-V 让你可以在 Windows 上以虚拟机形式运行多个操作系统。Hyper-V 简介Hyper-V 是微软推出的一款虚拟化技术,它能够在单一物理服务器上运行多个虚拟机操作系统。Hyper-V 包含在 Windows Server 操作系统中,并允许管理员创建,运行和管理虚拟化服务器和虚拟机。Hyper-V 可以帮助企业节省硬件成本,提高应用程序可用性和灵活性,同时减少维护和管理成本。它还可以作为一种工具来测试不同操作系统和应用程序配置,以及支持迁移和备份虚拟机。Hyper-V 支持 Windows 操作系统和其他一些非 Windows 操作系统,如 Linux、FreeBSD 等。系统要求Windows 10 企业版、专业版或教育版;具有二级地址转换 (SLAT) 的 64 位处理器;CPU 支持 VM 监视器模式扩展(Intel CPU 的 VT-c 技术);最少 4 GB 内存;首先,确认您的计算机支持 Hyper-V 技术。具体方法是,在运行框中输入“msinfo32”进入系统信息界面,查看“Hyper-V需求存在”项是否为“是”。启动 Hyper-V通过 PowerShell 启动 以管理员身份打开 PowerShell 控制台,运行下面的命令。Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All使用 CMD 和 DISM 启用 Hyper-V 以管理员身份打开 PowerShell 或 CMD 会话。键入以下命令:DISM /Online /Enable-Feature /All /FeatureName:Microsoft-Hyper-V通过设置启动右键单击 Windows 按钮并选择“应用和功能”。选择相关设置下右侧的“程序和功能”。选择“打开或关闭 Windows 功能”。选择“Hyper-V”,然后单击“确定”。安装完成后,系统会提示你重新启动计算机。创建虚拟机从 “开始” 菜单中打开 “Hyper-V Quick Create” 。选择一个操作系统或者使用本地安装源选择你自己的操作系统。如果你想要使用自己的映像创建虚拟机,请选择 Local Installation Source。选择 Change Installation Source。选择要转变为新虚拟机的 .iso 或 .vhdx。如果映像为 Linux 映像,请取消选择“安全启动”选项。选择 “创建虚拟机” 就这么简单!“快速创建” 将完成其余的工作。现在,你可以安装操作系统了。简单配置一下,然后就重新启动,之后就可以正常进入系统了。创建虚拟机其实和Vmware没什么区别。安装Win11虚拟机创建虚拟机时,选择本地安装源,点击更改安装源,选择你提前下载的Win11的iso镜像文件,此虚拟机将运行 Windows 保持默认勾选,点击右下角更多选项,给虚拟机一个名称和网络,网络选择Default Switch即可(你也可以选择你提前创建的网络)。然后点击创建虚拟机进入后续步骤。创建完虚拟机后,别着急点连接!!!选择编辑设置。在硬件>安全配置项下,加密支持下,一定一定一定要勾选启用受信任的平台模块(加密状态和虚拟机迁移流量选项可选可不选)。如果不勾选启用受信任的平台模块,在后面安装Windows时,将会提示:这台电脑无法运行Windows 11。在硬件>内存配置项下,RAM推荐最少4096 MB,默认为2048 MB,然后应用即可。现在你可以在成功创建虚拟机界面,点击连接按钮,来连接你创建的虚拟机了。点击启动按钮,你可能会看到如下界面,Press any key to boot from CD or DVD,>>Start PXE over IPv4。如果不出意外的话,你应该就能看到下面的安装界面了。唯一需要强调的是在你想执行哪种类型的安装,选择自定义:仅安装Windows(高级)选项。一切都配置完后,你可能会进入到看不到Windows的登录页面。如果无登录页面,你需要在菜单栏的"查看",取消"增强会话",然后自动重启后,即可看到登录界面,然后登录即可开始你的win11体验之旅。目前,微软又发布新版本(根据 22621.1848这个版本发布的)!下载地址:https://developer.microsoft.com/zh-cn/windows/downloads/virtual-machines/ 有兴趣的可以下载自行体验,安装方法和上面一样。
-
-
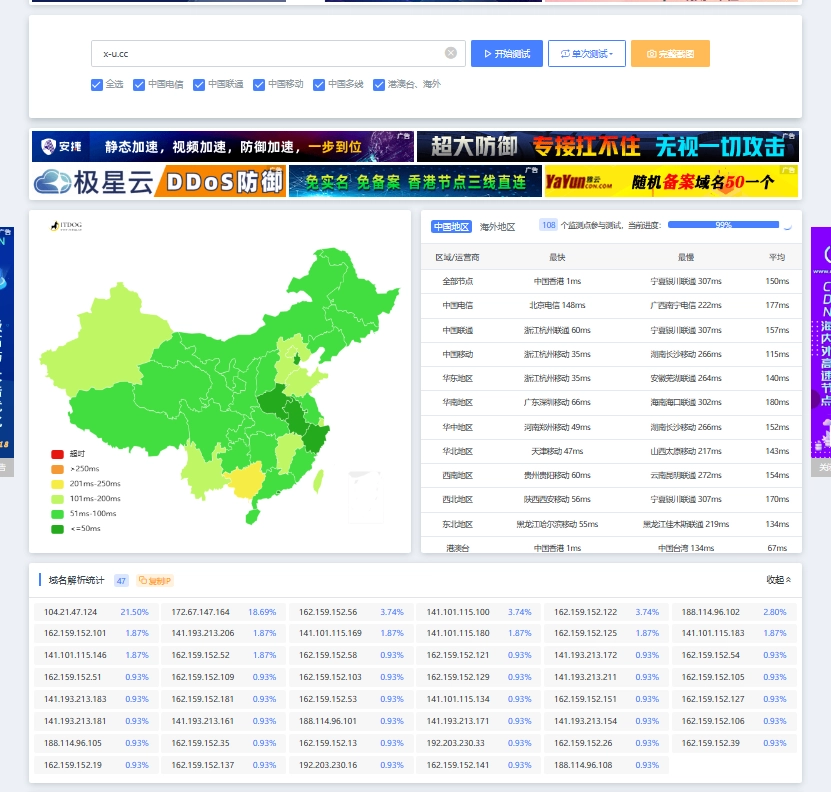
自建远程桌面连接服务,RustDesk搭建教程 什么时候需要远程协助呢? 可能是远程自己在家的电脑,方便游戏排队或者下载文件;也可能是远程单位电脑,进行远程办公;当然,我觉得更多情况是远程小伙伴,帮小伙伴解决一些技术问题。远程协助,除了可以用向日葵、QQ远程和Todesk等软件,有没有一款安全、经济和快速的软件呢?RustDesk本次教程教给大家如何通过 RustDesk ,部署自己的自建远程平台。主要的优点:安全性:RustDesk使用安全的加密通信协议来保护数据传输,确保远程桌面连接的安全性和隐私保护。跨平台支持:RustDesk支持跨多个操作系统平台,包括Windows、macOS和Linux、Android等,这使得它非常灵活和适用于不同的工作环境。而且从名字可以看出,RustDesk是使用Rust所编写,而使用Rust编写的程序,两大特点就是高效和并发,实际使用上,一台亚马逊入门(1C1G)EC2或者Lightsail(1C2G)给个人或者小型团队使用是没有问题的。准备工具服务器目前, RustDesk 支持 Linux Server 和 Windows Server 服务器;看自己的取舍,Linux比较节约资源,而Windows方便小白上手。为了重新体现我们是Linux技术博主,本次搭建使用 Linux Server 进行演示。根据 RustDesk 官网描述和实际测试,一台1C 1G的亚马逊EC2,中继模式下,8对设备远程依旧不卡!!!如果你是Windows Server用户,那么建议至少选择2C 4G的服务器配置,毕竟需要让Windows Server可以跑起来;本文主要演示Linux Server的方法。RustDesk部署下载服务端Github地址 我们使用的是X86版本服务器,所以这里我们下载X86版本的服务包:拷贝下载地址,到服务器上使用wget进行下载和解压:# 使用wget进行下载1.1.8-2版本(最新版本可以看上述发布地址) wget https://github.com/rustdesk/rustdesk-server/releases/download/1.1.8-2/rustdesk-server-linux-amd64.zip # 使用unzip解压 unzip rustdesk-server-linux-amd64.zip # 重命名解压后文件(方便管理) mv amd64 RustDesk现在,我们的RustDesk前期的准备就完成了。接下来,我们尝试运行,之后再注册为服务。尝试运行我们可以先尝试运行一下;确保可以使用后,我们再使用pm2挂起访问,或者systemctl注册为服务。为了方便我们测试,这里使用screen双开两个虚拟终端,并以前台模式挂起后端进程:# 安装screen sudo apt install screen之后,在刚刚我们的RustDesk解压后的目录内,可以看到相关的文件:RustDesk├── hbbr├── hbbs└── rustdesk-utils解释一下各个作用:hbbs: RustDesk的ID服务,用于分配和注册ID;hbbr: RustDesk的中继服务,主要远程访问就是这个,如果直连远程不行,会使用hbbr进行流量中继。之后,我们使用两个screen进行启动:# 创建一个叫myHbbs的虚拟终端: screen -R myHbbs # 运行hbbs ./hbbs通常情况下就会启动成功:使用screen启动hbbs紧接着,Ctrl+a 和 d 返回主终端,启动 hbbr 。# 创建一个叫yHbb的虚拟终端: screen -R myHbbr # 运行hbbr ./hbbr到此,如果没什么防火墙、安全组问题, RustDesk 就启动完成了。使用screen启动hbbr使用screen启动完成查看这个 RustDesk 目录,就可以发现,多了一些数据库文件和一个证书文件:RustDesk├── db_v2.sqlite3├── db_v2.sqlite3-shm├── db_v2.sqlite3-wal├── hbbr├── hbbs├── id_ed25519├── id_ed25519.pub└── rustdesk-utils我们需要拷贝.pub这个公钥文件,用于接下来的本地配置:拷贝公钥文件比如,我的公钥文件内容:C6bJn7*50nCK3y4=接下来,我们可以进行本地的配置。本地配置到 RustDesk 上的客户端下载地址,下载我们的客户端:RustDesk 客户端 Github 发布地址 通常情况下,我们下载最新的发布版本即可:比如:我这里安装macOS,并打开:点击上面的三个点,进入配置:找到网络配置:解锁网络配置,上方两个输入你的服务器IP,下方的Key输入上一步内我们拷贝的公钥(对于我是C6bJn7*50nCK3y4=),如果你有使用域名,IP部分也可以使用域名(CDN不行):我们没有开启强制加密,所以理论上key不填写,也可以进行连接;只是,不填写key,网络传输可能不安全。到此,我们的配置配置就完成了。我们可以体验一下。注册服务现在,我们回到服务端。刚刚使用的screen可能不太优雅,这里我们准备了两个方案注册为访问,方便管理。使用pm2运行如果要使用pm2运行,需要提前安装nodejs,使用nodejs的软件包管理器(npm或者yarn)安装pm2。安装nodejs的方法,我在之前的文章内已经说的十分详细,这里就不再过多介绍,如果不知道如何操作,可以参考:Windows/macOS/Linux上安装Node.js,并使用NVM管理多版本Node.js 就简单说一下思路和使用命令吧:# 安装nvm git clone https://github.com/nvm-sh/nvm.git ~/.nvm # 追加到环境变量 echo 'export NVM_DIR="$HOME/.nvm"' >> ~/.zshrc echo '[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm' >> ~/.zshrc # 重载环境变量 source ~/.zshrc # 使用nvm安装18版本nodejs nvm install 18 # 使用nodejs的npm安装pm2 npm install -g pm2之后,使用pm2的命令,启动hbbr和hbbs:# 当前正在RustDesk的目录内 pm2 start hbbs pm2 start hbbr之后,就可以发现。RustDesk已经启动。 具体的pm2使用,以后有机会和大家讲解。使用Systemctl运行我其实挺喜欢用 systemctl 的;但是上篇文章,其实已经足够详细,这里就直接给配置的脚本吧,我们需要创建两个Server,首先是 hbbs :[Unit] Description=RustDesk Hbbs After=network.target [Service] User=mintimate Type=simple WorkingDirectory=/home/mintimate/myApplication/RustDesk ExecStart=/home/mintimate/myApplication/RustDesk/hbbs ExecStop=/bin/kill -TERM $MAINPID [Install] WantedBy=multi-user.target之后是 hbbr :[Unit] Description=RustDesk Hbbr After=network.target [Service] User=mintimate Type=simple WorkingDirectory=/home/mintimate/myApplication/RustDesk ExecStart=/home/mintimate/myApplication/RustDesk/hbbr ExecStop=/bin/kill -TERM $MAINPID [Install] WantedBy=multi-user.target到此,使用 Systemctl 注册为服务就完成啦。其实也可以使用 screen ,就是重启系统后,再次启动比较麻烦。Q&A个人的一些使用经验,还有一些常见的问题。如何开启强制加密如果你搭建好了 RustDesk 后,会发发现:不需要设置 key ,也可以进行 RustDesk 的连接。这是因为 RustDesk 默认服务器端会开启加密,但是并不强制。如何你想开启强制加密,可以在启动 hbbr 和 hbbs 的时候,加上参数 -k _ :./hbbr -k _ ./hbbs -k _这样,客户端建立的连接,就需要强制设置好 key ,也就是我们的 *.pub 文件,否则无法建立通讯和远程连接。
-
[VPS评测] - VPS主机评测脚本 新买的 VPS 一般都要测试下性能,收集了网络上常见测试 VPS脚本一、秋水逸冰VPS性能测试脚本wget -qO- bench.sh | bash二、BlueSkyXN综合工具箱wget -O box.sh https://raw.githubusercontent.com/BlueSkyXN/SKY-BOX/main/box.sh && chmod +x box.sh && clear && ./box.sh三、SuperSpeed.sh 修复版bash <(curl -Lso- https://git.io/superspeed_uxh)四、一键检测VPS回程国内三网路由curl https://raw.githubusercontent.com/zhanghanyun/backtrace/main/install.sh -sSf | sh五、流媒体解锁测试一键脚本bash <(curl -L -s https://raw.githubusercontent.com/lmc999/RegionRestrictionCheck/main/check.sh)
-
One Manager 搭建一个美观的网盘 前几天闲着没事,就去逛别人的博客,经常能够看到网盘,感觉很美观,今天就用 One Manager 搭建一个一样美观的网盘1.什么是 One Manager?这是一个利用微软onedrive api将onedrive目录映射成一个云盘的程序(同时支持阿里云盘),类似的程序有很多,比如OneIndex、Pyone、OnePoint等等。2.One Manager 能做什么?通过借助onedrive和阿里云盘等网盘api和refresh_token,把云盘映射到网站上,从而达成直接在网站上上传文件(直接同步到网盘上),用直链直接下载文件,管理文件,并让访客访问的目的。3.如果要搭建,该准备些什么?虚拟主机——近年来,虚拟主机的价格一跌再跌,几乎新手类的入门虚拟主机30左右一年,当然也有免费的羊毛可以薅,这里推荐腾讯云(速度快,有保障),小鱼云(速度快,实惠,不用备案),乐数云(可白嫖),如果找到可行的主机都可以域名——这就不用多说了,想要被访问,域名必不可少,最近的各大厂也是疯狂甩卖白菜价的top,xyz域名(硅云0元,西数1元,腾讯9元,请根据自己需要,以及认为cdn哪个加速快选用),freenom也是一个不错的选择,tk,ml,ga顶级域名都是免费的,但是最近又看了下,貌似失效了,也不知道什么时候恢复One Manager 本体软件GitHub作者链接:https://github.com/qkqpttgf/OneManager-php蓝奏云备用链接:https://wwck.lanzouf.com/iYKMm0l9uzlc(如果打不开请把lanzouf改成lanzoui或者lanzouw)以下是详细教程最最基础部分,先进行虚拟主机域名的解析与绑定首先打开你的虚拟主机的控制面板界面,点击域名绑定(由于各厂商不同,就不放图了)看虚拟主机提示的想要绑定,先解析的链接(如果是ip地址,都行,请看好是用cname还是a记录解析)打开域名管理界面,添加解析记录,如果是ip,大部分情况下用a记录,主机名随便填,@的话,是你访问的云盘就是你的域名,xxx的话,你的云盘访问地址就是xxx.你的域名,在后面选择解析方式,cname或者a,然后把ip或者链接填到记录值一栏,其余的就不用管了在虚拟主机绑定你的域名,记住你要绑定的目录下载源码,打开ftp文件管理进行在线上传,将你下载的源码进行上传,并解压到你绑定的目录,保证那一堆文件在你绑定的目录里面接下来就可以在浏览器输入你的网盘地址,进行设置了由于各个厂商的主机默认配置不同,进入配置时,如果出现伪静态设置错误可自行百度 “One Manager伪静态” 或者复制以下代码复制到目录里面的 .htaccess 文件# # Apache # # LoadModule rewrite_module modules/mod_rewrite.so # # AllowOverride All RewriteEngine On # RewriteCond $1 !^(.well-known) RewriteRule ^(.*) index.php?/$1 [L] ### nginx # rewrite ^/(?!.well-known)(.*)$ /index.php?/$1 last; # ### nginx Subdirectory 在子目录中使用 # location /OneManager2/ { # rewrite ^/(.*)$ /OneManager2/index.php?/$1 last; # } # ### caddy # rewrite { # to index.php?/$1 # } # ### caddy2 Caddyfile # @try_files { # not path /.well-known/* # file { # try_files index.php # } # } # rewrite @try_files {http.matchers.file.relative} # 进入网站设置完成后,可见到这样的界面点击左上角的登录,输入你自己设置的密码登录成功后,登录按钮变成了管理,点击后再点击设置,进行添加盘在添加盘的左侧选择你要添加的盘(推荐阿里云盘和onedrive,在国内速度还行,其余差不多都需要魔法)阿里云盘搭建方法先点击添加盘,按要求输入标签和名称,接下来就要获取refresh tokenhttps://alist.nn.ci/zh/guide/drivers/aliyundrive.html 打开网址,点击获取 token ,用手机阿里云盘扫描二维码,再点击下按钮,就能够获取token再次进入你的添加盘的界面,输入 token ,就可以看到阿里云盘挂载成功了onedrive搭建方法点击添加盘,根据默认的设置直接添加标签和名称,会自动跳转到 microsoft登录,登录就可以挂载成功了如果觉得界面不够美观,可以点击平台变量进行设置https://www.cnblogs.com/braless/p/14173750.html 该网站可以教你如何个性化你的网盘这边建议游客主题设置为 classic ,比较美观结尾注意事项登录成功进行上传文件后,请点击管理-刷新当前目录缓存,游客端方可看见文件
-
JAVA项目自从用了接口请求合并,效率直接加倍! 请求合并到底有什么意义呢?我们来看下图。假设我们3个用户(用户id分别是1、2、3),现在他们都要查询自己的基本信息,请求到服务器,服务器端请求数据库,发出3次请求。我们都知道数据库连接资源是相当宝贵的,那么我们怎么尽可能节省连接资源呢?这里把数据库换成被调用的远程服务,也是同样的道理。我们改变下思路,如下图所示。我们在服务器端把请求合并,只发出一条SQL查询数据库,数据库返回后,服务器端处理返回数据,根据一个唯一请求ID,把数据分组,返回给对应用户。技术手段LinkedBlockQueue 阻塞队列ScheduledThreadPoolExecutor 定时任务线程池CompleteableFuture future 阻塞机制(Java 8 的 CompletableFuture 并没有 timeout 机制,后面优化,使用了队列替代)代码实现查询用户的代码public interface UserService { Map<String, Users> queryUserByIdBatch(List<UserWrapBatchService.Request> userReqs); } @Service public class UserServiceImpl implements UserService { @Resource private UsersMapper usersMapper; @Override public Map<String, Users> queryUserByIdBatch(List<UserWrapBatchService.Request> userReqs) { // 全部参数 List<Long> userIds = userReqs.stream().map(UserWrapBatchService.Request::getUserId).collect(Collectors.toList()); QueryWrapper<Users> queryWrapper = new QueryWrapper<>(); // 用in语句合并成一条SQL,避免多次请求数据库的IO queryWrapper.in("id", userIds); List<Users> users = usersMapper.selectList(queryWrapper); Map<Long, List<Users>> userGroup = users.stream().collect(Collectors.groupingBy(Users::getId)); HashMap<String, Users> result = new HashMap<>(); userReqs.forEach(val -> { List<Users> usersList = userGroup.get(val.getUserId()); if (!CollectionUtils.isEmpty(usersList)) { result.put(val.getRequestId(), usersList.get(0)); } else { // 表示没数据 result.put(val.getRequestId(), null); } }); return result; } }合并请求的实现package com.springboot.sample.service.impl; import com.springboot.sample.bean.Users; import com.springboot.sample.service.UserService; import org.springframework.stereotype.Service; import javax.annotation.PostConstruct; import javax.annotation.Resource; import java.util.*; import java.util.concurrent.*; /*** * zzq * 包装成批量执行的地方 * */ @Service public class UserWrapBatchService { @Resource private UserService userService; /** * 最大任务数 **/ public static int MAX_TASK_NUM = 100; /** * 请求类,code为查询的共同特征,例如查询商品,通过不同id的来区分 * CompletableFuture将处理结果返回 */ public class Request { // 请求id 唯一 String requestId; // 参数 Long userId; //TODO Java 8 的 CompletableFuture 并没有 timeout 机制 CompletableFuture<Users> completableFuture; public String getRequestId() { return requestId; } public void setRequestId(String requestId) { this.requestId = requestId; } public Long getUserId() { return userId; } public void setUserId(Long userId) { this.userId = userId; } public CompletableFuture getCompletableFuture() { return completableFuture; } public void setCompletableFuture(CompletableFuture completableFuture) { this.completableFuture = completableFuture; } } /* LinkedBlockingQueue是一个阻塞的队列,内部采用链表的结果,通过两个ReenTrantLock来保证线程安全 LinkedBlockingQueue与ArrayBlockingQueue的区别 ArrayBlockingQueue默认指定了长度,而LinkedBlockingQueue的默认长度是Integer.MAX_VALUE,也就是无界队列,在移除的速度小于添加的速度时,容易造成OOM。 ArrayBlockingQueue的存储容器是数组,而LinkedBlockingQueue是存储容器是链表 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁, 而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量, 也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。 */ private final Queue<Request> queue = new LinkedBlockingQueue(); @PostConstruct public void init() { //定时任务线程池,创建一个支持定时、周期性或延时任务的限定线程数目(这里传入的是1)的线程池 ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); scheduledExecutorService.scheduleAtFixedRate(() -> { int size = queue.size(); //如果队列没数据,表示这段时间没有请求,直接返回 if (size == 0) { return; } List<Request> list = new ArrayList<>(); System.out.println("合并了 [" + size + "] 个请求"); //将队列的请求消费到一个集合保存 for (int i = 0; i < size; i++) { // 后面的SQL语句是有长度限制的,所以还要做限制每次批量的数量,超过最大任务数,等下次执行 if (i < MAX_TASK_NUM) { list.add(queue.poll()); } } //拿到我们需要去数据库查询的特征,保存为集合 List<Request> userReqs = new ArrayList<>(); for (Request request : list) { userReqs.add(request); } //将参数传入service处理, 这里是本地服务,也可以把userService 看成RPC之类的远程调用 Map<String, Users> response = userService.queryUserByIdBatch(userReqs); //将处理结果返回各自的请求 for (Request request : list) { Users result = response.get(request.requestId); request.completableFuture.complete(result); //completableFuture.complete方法完成赋值,这一步执行完毕,下面future.get()阻塞的请求可以继续执行了 } }, 100, 10, TimeUnit.MILLISECONDS); //scheduleAtFixedRate是周期性执行 schedule是延迟执行 initialDelay是初始延迟 period是周期间隔 后面是单位 //这里我写的是 初始化后100毫秒后执行,周期性执行10毫秒执行一次 } public Users queryUser(Long userId) { Request request = new Request(); // 这里用UUID做请求id request.requestId = UUID.randomUUID().toString().replace("-", ""); request.userId = userId; CompletableFuture<Users> future = new CompletableFuture<>(); request.completableFuture = future; //将对象传入队列 queue.offer(request); //如果这时候没完成赋值,那么就会阻塞,直到能够拿到值 try { return future.get(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } return null; } }控制层调用/*** * 请求合并 * */ @RequestMapping("/merge") public Callable<Users> merge(Long userId) { return new Callable<Users>() { @Override public Users call() throws Exception { return userBatchService.queryUser(userId); } }; }Callable 是什么可以参考:https://blog.csdn.net/baidu_19473529/article/details/123596792模拟高并发查询的代码package com.springboot.sample; import org.springframework.web.client.RestTemplate; import java.util.Random; import java.util.concurrent.CountDownLatch; public class TestBatch { private static int threadCount = 30; private final static CountDownLatch COUNT_DOWN_LATCH = new CountDownLatch(threadCount); //为保证30个线程同时并发运行 private static final RestTemplate restTemplate = new RestTemplate(); public static void main(String[] args) { for (int i = 0; i < threadCount; i++) {//循环开30个线程 new Thread(new Runnable() { public void run() { COUNT_DOWN_LATCH.countDown();//每次减一 try { COUNT_DOWN_LATCH.await(); //此处等待状态,为了让30个线程同时进行 } catch (InterruptedException e) { e.printStackTrace(); } for (int j = 1; j <= 3; j++) { int param = new Random().nextInt(4); if (param <=0){ param++; } String responseBody = restTemplate.getForObject("http://localhost:8080/asyncAndMerge/merge?userId=" + param, String.class); System.out.println(Thread.currentThread().getName() + "参数 " + param + " 返回值 " + responseBody); } } }).start(); } } }测试效果要注意的问题Java 8 的 CompletableFuture 并没有 timeout 机制后面的SQL语句是有长度限制的,所以还要做限制每次批量的数量,超过最大任务数,等下次执行(本例中加了MAX_TASK_NUM判断)使用队列的超时解决Java 8 的 CompletableFuture 并没有 timeout 机制核心代码package com.springboot.sample.service.impl; import com.springboot.sample.bean.Users; import com.springboot.sample.service.UserService; import org.springframework.stereotype.Service; import javax.annotation.PostConstruct; import javax.annotation.Resource; import java.util.*; import java.util.concurrent.*; /*** * zzq * 包装成批量执行的地方,使用queue解决超时问题 * */ @Service public class UserWrapBatchQueueService { @Resource private UserService userService; /** * 最大任务数 **/ public static int MAX_TASK_NUM = 100; /** * 请求类,code为查询的共同特征,例如查询商品,通过不同id的来区分 * CompletableFuture将处理结果返回 */ public class Request { // 请求id String requestId; // 参数 Long userId; // 队列,这个有超时机制 LinkedBlockingQueue<Users> usersQueue; public String getRequestId() { return requestId; } public void setRequestId(String requestId) { this.requestId = requestId; } public Long getUserId() { return userId; } public void setUserId(Long userId) { this.userId = userId; } public LinkedBlockingQueue<Users> getUsersQueue() { return usersQueue; } public void setUsersQueue(LinkedBlockingQueue<Users> usersQueue) { this.usersQueue = usersQueue; } } /* LinkedBlockingQueue是一个阻塞的队列,内部采用链表的结果,通过两个ReenTrantLock来保证线程安全 LinkedBlockingQueue与ArrayBlockingQueue的区别 ArrayBlockingQueue默认指定了长度,而LinkedBlockingQueue的默认长度是Integer.MAX_VALUE,也就是无界队列,在移除的速度小于添加的速度时,容易造成OOM。 ArrayBlockingQueue的存储容器是数组,而LinkedBlockingQueue是存储容器是链表 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁, 而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量, 也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。 */ private final Queue<Request> queue = new LinkedBlockingQueue(); @PostConstruct public void init() { //定时任务线程池,创建一个支持定时、周期性或延时任务的限定线程数目(这里传入的是1)的线程池 ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); scheduledExecutorService.scheduleAtFixedRate(() -> { int size = queue.size(); //如果队列没数据,表示这段时间没有请求,直接返回 if (size == 0) { return; } List<Request> list = new ArrayList<>(); System.out.println("合并了 [" + size + "] 个请求"); //将队列的请求消费到一个集合保存 for (int i = 0; i < size; i++) { // 后面的SQL语句是有长度限制的,所以还要做限制每次批量的数量,超过最大任务数,等下次执行 if (i < MAX_TASK_NUM) { list.add(queue.poll()); } } //拿到我们需要去数据库查询的特征,保存为集合 List<Request> userReqs = new ArrayList<>(); for (Request request : list) { userReqs.add(request); } //将参数传入service处理, 这里是本地服务,也可以把userService 看成RPC之类的远程调用 Map<String, Users> response = userService.queryUserByIdBatchQueue(userReqs); for (Request userReq : userReqs) { // 这里再把结果放到队列里 Users users = response.get(userReq.getRequestId()); userReq.usersQueue.offer(users); } }, 100, 10, TimeUnit.MILLISECONDS); //scheduleAtFixedRate是周期性执行 schedule是延迟执行 initialDelay是初始延迟 period是周期间隔 后面是单位 //这里我写的是 初始化后100毫秒后执行,周期性执行10毫秒执行一次 } public Users queryUser(Long userId) { Request request = new Request(); // 这里用UUID做请求id request.requestId = UUID.randomUUID().toString().replace("-", ""); request.userId = userId; LinkedBlockingQueue<Users> usersQueue = new LinkedBlockingQueue<>(); request.usersQueue = usersQueue; //将对象传入队列 queue.offer(request); //取出元素时,如果队列为空,给定阻塞多少毫秒再队列取值,这里是3秒 try { return usersQueue.poll(3000,TimeUnit.MILLISECONDS); } catch (InterruptedException e) { e.printStackTrace(); } return null; } } ...省略... @Override public Map<String, Users> queryUserByIdBatchQueue(List<UserWrapBatchQueueService.Request> userReqs) { // 全部参数 List<Long> userIds = userReqs.stream().map(UserWrapBatchQueueService.Request::getUserId).collect(Collectors.toList()); QueryWrapper<Users> queryWrapper = new QueryWrapper<>(); // 用in语句合并成一条SQL,避免多次请求数据库的IO queryWrapper.in("id", userIds); List<Users> users = usersMapper.selectList(queryWrapper); Map<Long, List<Users>> userGroup = users.stream().collect(Collectors.groupingBy(Users::getId)); HashMap<String, Users> result = new HashMap<>(); // 数据分组 userReqs.forEach(val -> { List<Users> usersList = userGroup.get(val.getUserId()); if (!CollectionUtils.isEmpty(usersList)) { result.put(val.getRequestId(), usersList.get(0)); } else { // 表示没数据 , 这里要new,不然加入队列会空指针 result.put(val.getRequestId(), new Users()); } }); return result; } ...省略...小结请求合并,批量的办法能大幅节省被调用系统的连接资源,本例是以数据库为例,其他RPC调用也是类似的道理。缺点就是请求的时间在执行实际的逻辑之前增加了等待时间,不适合低并发的场景。
-
消息推送 架构设计(推荐看看) 构建企业级统一基础推送服务,支持通过多渠道推送,能够统一集成的电子邮件、短信、聊天、钉钉、企业微信和其他公共社交应用:聊天 - 微信Wechat/QQ站内推送通知(移动设备和Web浏览器)站外推送通知(移动设备,APP没有开启)短信(如登录密码、营销活动)电子邮件钉钉企业微信企业级统一基础推送服务,是一个通用特性,适用于所有现代分布式应用,无论采用何种编程语言和技术。推送能力的演进第一阶段(模块化):各自为政、各自封装企业内部,早期业务量比较少,各系统基本都是有自己的推送模块,类型也是五花八门:聊天模块短信模块电子邮件模块websocket 模块各自封装模块比较简单,但是实现分散、各系统模块的质量也很难统一保证。第二阶段(框架化):集成框架为了减少重复性设计、开发成本, 设计了统一的推送框架同一套微服务框架,共用一个统一的推送框架为了解决上述分散实现的问题,企业内部统一实现了一个综合各类推送功能的基础库,供业务方统一调用。聊天基础starter短信基础starter电子邮件基础starterwebsocket 基础starter于是,我们把 springboot-starter 的逻辑封装到了服务治理框架内,微服务服务启动时,每一个服务对各种的starter进行运维管理、配置管理。第三阶段(服务化):推送服务集成到框架,每一套服务,都需要重复性的解决3高问题。推送服务,数据量大,需要解决跨库查询问题推送服务,性能要求高,需要解决高并发问题大数据量、并发量高,意味着:硬件资源投入大运维成本高这样的基础服务,需要进行沉淀,剥离,集中成统一的、基础服务,由专门团队负责维护、迭代、运维。降低重复投入、重复建设成本, 真正的降本增效。于是, 推送框架 演进为 推送服务推送服务在业务系统中的位置一个业务应用, 基本上有很多原子服务编排、整合而来,最终构建出一个完整的架构图。接入层,这是外部请求进入内部系统的门户,所有的请求都必须通过 API 网关。应用层,也被称为聚合层,它为相关业务提供聚合接口,并调用中台服务进行组合。原子服务,包括就是原子技术服务,原子业务服务,根据业务需求提供相关的接口。原子服务为整个架构提供可复用的能力。例如,在B站视频网站平台上,评论服务作为一项原子服务,在B站的视频、文章、社区都需要,那么为了提高复用性,评论服务就可以独立为原子服务,不能与特定需求紧密耦合。在这种情况下, 评论服务,需要供一种可以适应不同场景的复用能力。类似的,文件存储、数据存储、推送服务、身份验证服务等功能,都会沉淀为原子服务,业务开发人员,在原子服务基础上,进行编排、配置、组合,可以快速构建业务应用。推送服务功能要求发送通知对通知进行优先级排序根据客户的保存偏好发送通知支持单个/简单的通知消息和批量通知消息各种通知的分析用例通知消息的报告推送非功能性需求(NFR)高性能:qps > 1W高可用性(HA):99.99%低延迟:TP99 在10ms以下高扩展:可扩展/可插拔的设计,以便添加更多适配器和提供商,与所有通知模块的API集成以及与客户端和服务提供商/供应商的外部集成跨平台:支持Android/iOS移动设备和桌面/笔记本电脑的Web浏览器自伸缩:可在本地(VMware Tanzu)和 AWS、GCP 或 Azure 等公共云服务上扩展负载推送系统设计架构这些解决方案设计的考虑因素和组件包括:1. 通知客户端 这些客户端通过 API 调用请求单个和批量消息。它们将向简单和批量通知服务发送通知消息。简单通知客户端:专门用于发送单个通知的客户端,负责向用户发送单一通知。这些客户端通常用于向特定用户发送重要通知,例如密码找回或账户异常提醒。批量通知客户端:专门用于发送批量通知的客户端,负责向用户批量推送通知。这些客户端通常用于需要通知大量用户的场景,例如企业内部通知或营销活动。2. 通知服务作为入口点的这些服务,通过暴露 REST API 与客户端互动。它们负责构建通知消息,通过调用"模板服务"。这些消息将使用"验证服务"进行验证。简单通知服务:该服务将提供 API,主要负责处理简单通知请求,提供与后端服务集成的 API,以便将通知发送给用户。这种服务通常用于处理较少的通知请求,例如针对特定用户或事件的简单通知。批量通知服务:该服务将提供 API,主要负责处理批量通知请求,提供与后端服务集成的 API,以便批量发送通知。这种服务通常用于处理大量的通知请求,例如企业内部的批量通知或营销活动的批量推送。此服务还将管理通知消息。它将发送的消息持久化到数据库并维护活动日志。可以使用这些服务的 API 重新发送同一条消息。它将提供添加/更新/删除和查看旧消息和新消息的 API。它还将提供 Web 仪表板,该仪表板应具有筛选选项,以根据不同的条件(如日期范围、优先级、模块用户、用户组等)筛选消息。3. 模板服务 此服务主要负责所有可用的一次性密码(OTP)、短信、电子邮件、聊天以及其他推送通知消息的模板管理。它还提供了 REST API ,以便创建、更新、删除和管理模板。除此之外,它还将提供一个用户界面(UI)的仪表板页面,使用户能从网络控制台检查和管理各种消息模板。4. 消息分发服务 定时分发服务:该服务将提供API来安排立即或指定时间的通知。可以是以下任何一种:秒分钟每小时每天每周每月每年自定义频率等。还可能有其他自动触发的服务,基于预定时间进行消息触发。消息验证服务:此服务全权负责根据业务规定和预期格式对通知信息进行核实。批量通知需由授权的系统管理员同意。消息优先级服务:该服务负责对通知进行优先级排序,分为高、中、低三个等级。通知信息具有较高的优先级和有时间限制的到期时间,它们将始终以较高优先级发送。"通用出口处理器"会接收消息并根据相同的优先级从高、中和低三个不同的队列中发送和处理。在非工作时间,可以以低优先级发送批量通知。在交易过程中的应用程序通知可以发送到中优先级,如电子邮件等。企业可以根据通知的重要性确定优先级。5. 事件优先级队列(消息队列) 此服务提供事件中心功能,负责接收通知服务的高、中、低三个优先级的信息。它会根据业务的优先级来发送和接收通知。企业可以根据通知的重要性来设定优先级。服务内部包含三个主题,用于根据业务优先级接收和发送通知:低优先级:主要用于在非工作时间发送批量通知。中优先级:适用于在交易过程中发送的应用程序通知,如电子邮件等。高优先级:通知信息具有较高的优先级和有时间限制的到期时间,它们将始终以较高优先级发送。6. 通用出站处理程序该服务通过轮询事件优先级队列来接收事件中心中的通知信息,并根据其优先级进行处理。高优先级的通知会优先处理"高"队列,依次类推。最后,它通过事件中心将通知信息发送到特定的适配器。此外,该服务还从用户选择服务中获取目标用户/应用程序,以便进行通知的分发。在处理过程中,通用出口处理器会根据事件的优先级进行相应的操作,确保重要事件得到优先处理。这样,企业可以根据通知的优先级来确定处理顺序,从而提高通知的处理效率。除此之外, 通用出站处理程序,还能进行消息的进一步按照通道类型进行分发:该服务将消息发送到各种支持的适配器。这些适配器会根据不同的设备(如桌面/移动设备)和通知类型(如短信/OTP/电子邮件/聊天/推送通知)进行转换。7. 通知适配器 这些转换器将从消息队列(rocketmq)接收传入信息并根据其所支持的格式传递给外部合作伙伴。以下是一些转换器,根据需求可以增加更多:QQ 通知适配器服务微信Wechat 聊天通知适配器服务应用内通知适配器服务电子邮件适配器服务短信适配器服务OTP 适配器服务8. 通道供应商这些是外部的 SAAS(云上/本地)服务提供商,利用它们的基础设施和技术实现实际的通知传递。它们可能是像 AWS SNS、MailChimp 等的付费推送通道服务。QQ 供应商集成服务微信Wechat 供应商集成服务应用推送通知供应商集成服务电子邮件供应商集成服务短信供应商集成服务9. 用户选择服务该服务提供选择目标用户和各种应用程序模块的功能。这可能包括将批量消息发送到特定的用户组或不同的应用程序模块。可能是 AD/IAM/eDirectory/用户数据库/用户组,具体取决于客户的偏好。在服务内部,它将使用"用户配置文件服务"API 来消费和检查客户的通知偏好。10. 用户配置文件服务 此服务提供各种功能,包括管理用户配置文件及其偏好设置。还管理内部用户标识,和外部通道标识之间的关联关系钉钉用户标识 和 用户标识 关联关系企业微信 用户标识 和 用户标识 关联关系用户和邮箱的关联关系等等它还将提供取消订阅通知以及通知接收频率等功能。"通知服务"将依赖于此服务,以便根据用户的通知偏好来发送通知。此外,该服务还可以用于统计和分析用户对通知的偏好,以帮助企业优化通知策略。11. 分析服务 该处理器将负责执行所有的分析工作,识别通知使用情况、趋势并生成报告。它将从分析数据库(Cassandra)和通知数据库中提取所有最终的通知信息,用于分析和报告目的。以下是一些用例:每天/每秒的总通知数哪个通知系统使用最频繁消息的平均大小和频率基于优先级过滤消息等等...12. 通知跟踪器此服务将持续监视事件中心队列并跟踪所有发送的通知。它捕获通知的元数据,如传输时间、传送状态、通信渠道、消息类型等。13. 通知数据库:Mysql数据库集群 通知数据库,用于存储库用于存储所有通知信息,包括发送时间、状态等。它包括一个数据库集群,其中领导者用于执行所有写操作,读取操作则在读取副本/跟随者上进行。这个数据库群集将持久化所有通知,供分析和报告使用。它基于“写入更多,读取更少”的理念。它能提供良好的性能和低延迟,适应大量的通知,因为它内部处理大量的写操作,并与其他数据库节点同步,保持高可用性和可靠性的冗余数据/消息。在任何节点崩溃的情况下,消息将始终可用。
-
Cloudflare加速解析服务-优化大陆访问速度 前言Cloudfalre 加速解析是由 心有网络 向中国大陆用户提供的公共优化服务接入服务节点: cf.13d7s.site接入使用方式类似于其它CDN的CNAME接入,可以为中国大陆用户访问Cloudflare网络节点大幅度加速,累计加速节点60+,其中移动网络为最快,联通最慢。开始前的温馨提示(看一下)1、教程使用阿里云域名演示2、教程过程会cloudflare和阿里云来回切换,所以大家不要以为我教程过程中切换页面之前的页面就把之前的页面关闭了3、教程是在别的地方看见的,原文说的比较简单,我这里会很详细。4、域名商要支持分区解析(大概意思就是能选路,国内网络怎么访问,国外网络怎么访问),推荐阿里云Aliyun、腾讯云DNSpod,如果你的域名不是这两家,末尾我会演示一下在其他地方的域名使用他们的域名解析的5、本教程十分详细,不用担心自己是小白就看不懂(基本是一个教程一个图那种)教程登陆 cloudflare(官网有点卡,耐心等一下,有能力可以挂梯子):https://dash.cloudflare.com/ 有账号我们直接登录,没有账号我们直接注册一个登录。(这里如果我们是第一次弄的话邮箱地址一定要写清楚,后面验证域名的时候会给我们发邮件)登录之后我们添加我们的网站。我这里网站是x-u.cc一进来就会让我们选择服务,这里我们有钱的话可以去买,不想花钱的话我们直接往下面翻,我这里选择白嫖服务这里的话是提示我们域名之前的解析记录,看一下没有问题的话就继续了。(这里如果我们没有解析记录话我们添加一下,然后继续)(记住这里一定要选代理,不代理的话他不会给我们套CDN)然后这里有一大推东西(大概意思就是我们把DNS服务器改成他的),我们不用管,往下找到第四步。这里是我们要修改dns服务器的值我们现在终于可以去打开我们的阿里云了,多开一个页面,登录阿里云:阿里云-计算,为了无法计算的价值 (aliyun.com)登录阿里云之后,我们点击控制台,找到域名:这里我们点x-u.cc,不要去点解析然后进入这个页面,点击修改dns服务器然后修改我们的DNS服务器,这里我其实已经修改好了,但是为了照顾小白,我这里还是再弄一下。这里可以填写两个dns服务,我们直接把之前的cloudflare页面的dns服务值复制过来然后我们DNS就修改好了阿里云这边改好了之后我们切回我们的cloudflare点击下一步了。这里我们选稍后完成进入到这里之后我们等一哈,cloudflare会给我们一个成功的邮件(基本十几秒就到了)。邮箱一到,表示我们已经成功了现在我们去使用itdog测试一下:https://itdog.cn/这里大家其实只会有几个ip,也没有我这么绿,这是因为我之前已经弄好了导致的。好的,目前为止我们已经完成3/2的进度了,马上就可以和我一样快了(滑稽)现在我们切回我们之前阿里云的dns页面,继续修改我们的dns服务器添加dns服务器到能填写4个地址然后我们这里前面两个写上我们阿里云的地址:dns1.hichina.comdns2.hichina.com然后3和4我们写上cloudflare的地址这里我们可以直接复制粘贴到3和4的输入框中:这里会发现我第三个框是红色的,然后确定也是灰色的,这里说明我们第三个框有点问题(一般都是前面有多的空格或者后面有多的空格)我们把多余的空格删除就行了接下来我们点击域名解析:这里我们添加解析:注意:国内(我们需要添加三条解析(中国移动、中国电信、中国联通))我们CNAME解析值是:cf.13d7s.site境外我们CNAME解析值是:你的域名+.cdn.cloudflare.net(比如我是@解析,那我的解析值就是x-u.cc,我的域名值就是x-u.cc.cdn.cloudflare.net,如果我是www解析,那我域名值就是www.x-u.cc.cdn.cloudflare.net)好的,我们现在就已经完成了我们所有过程,我们现在打开itdog看看是否有变化。https://itdog.cn/
-
一个通用型PDF文件处理工具,完全开源,个人免费使用! 🔥本项目系统是一款通用型PDF文件处理工具,包含PDF合并、拆分、旋转、水印、加密、转换等20多项常用功能,完全开源,个人免费使用,界面简洁,简单易用。虽然目前网上关于PDF处理的工具有很多,但是都有一些缺点:专业的PDF编辑软件对于高级一点的功能(添加水印、页面编辑等)需要收费或限制功能在线PDF工具类网站需要上传PDF到服务器处理再下载,有泄露隐私风险各大编程语言的PDF处理库虽然可以免费实现一些高级功能,但是需要一定的编程经验,使用没有图形界面程序方便部分小众工具虽然可以满足部分特殊需求,但是功能较为单一由于PDF处理是一个很常见的需求,为了绕开上述这些限制,提高工作效率,诞生了此项目。本项目具有如下优势:完全本地化:无需联网,不必担心隐私泄露功能丰富:支持包括PDF批量合并、拆分、添加水印、加密/解密、提取、OCR识别在内的20余项功能跨平台:支持在Windows、Mac、Linux设备上使用开源免费界面简洁,使用简单体积小巧(~30M),绿色免安装,随用随开插件化:根据需要选择是否安装额外组件,减小安装包体积功能演示上手指南安装二进制安装去Releases版块下载对应平台的安装包安装即可。编译安装安装go环境、node环境和python环境# 确认go安装成功 go version # 确认 "~/go/bin" 位于PATH环境变量中 echo "export PATH=$PATH:$HOME/go/bin" >> $HOME/.bashrc source $HOME/.bashrc echo $PATH | grep go/bin # 确认nodejs安装成功 npm --version编译项目git clone https://github.com/kevin2li/PDF-Guru.git cd PDF-Guru ROOT=$(pwd) go install github.com/wailsapp/wails/v2/cmd/wails@latest go mod tidy # 安装前端依赖 cd ${ROOT}/frontend npm install # 安装后端环境 cd ${ROOT}/thirdparty pip install -r requirements.txt pyinstaller -F -w pdf.py mkdir ${ROOT}/build/bin # 1) for darwin, linux cp dist/pdf ocr.py convert.py ${ROOT}/build/bin # 2) for windows cp dist/pdf.exe ${ROOT}/build/bin cp ocr.py ${ROOT}/build/bin cp convert.py ${ROOT}/build/bin cd $ROOT wails dev # 开发预览 wails build # 编译将build/bin目录打包,运行PDF Guru即可。最后,想学习这个项目的可以查看 项目地址 !!



![[VPS评测] - VPS主机评测脚本](https://r2.upi.cc/book-cover.png?key=806931)